During Birthday Week 2023, we launched Workers AI. Since then, we have been listening to your feedback, and one thing we’ve heard consistently is that our customers want Workers AI to be faster. In particular, we hear that large language model (LLM) generation needs to be faster. Users want their interactive chat and agents to go faster, developers want faster help, and users do not want to wait for applications and generated website content to load. Today, we’re announcing three upgrades we’ve made to Workers AI to bring faster and more efficient inference to our customers: upgraded hardware, KV cache compression, and speculative decoding.
Thanks to Cloudflare’s 12th generation compute servers, our network now supports a newer generation of GPUs capable of supporting larger models and faster inference. Customers can now use Meta Llama 3.2 11B, Meta’s newly released multi-modal model with vision support, as well as Meta Llama 3.1 70B on Workers AI. Depending on load and time of day, customers can expect to see two to three times the throughput for Llama 3.1 and 3.2 compared to our previous generation Workers AI hardware. More performance information for these models can be found in today’s post: Cloudflare’s Bigger, Better, Faster AI platform.
New KV cache compression methods, now open source
In our effort to deliver low-cost low-latency inference to the world, Workers AI has been developing novel methods to boost efficiency of LLM inference. Today, we’re excited to announce a technique for KV cache compression that can help increase throughput of an inference platform. And we’ve made it open source too, so that everyone can benefit from our research.
It’s all about memory
One of the main bottlenecks when running LLM inference is the amount of vRAM (memory) available. Every word that an LLM processes generates a set of vectors that encode the meaning of that word in the context of any earlier words in the input that are used to generate new tokens in the future. These vectors are stored in the KV cache, causing the memory required for inference to scale linearly with the total number of tokens of all sequences being processed. This makes memory a bottleneck for a lot of transformer-based models. Because of this, the amount of memory an instance has available limits the number of sequences it can generate concurrently, as well as the maximum token length of sequences it can generate.
So what is the KV cache anyway?
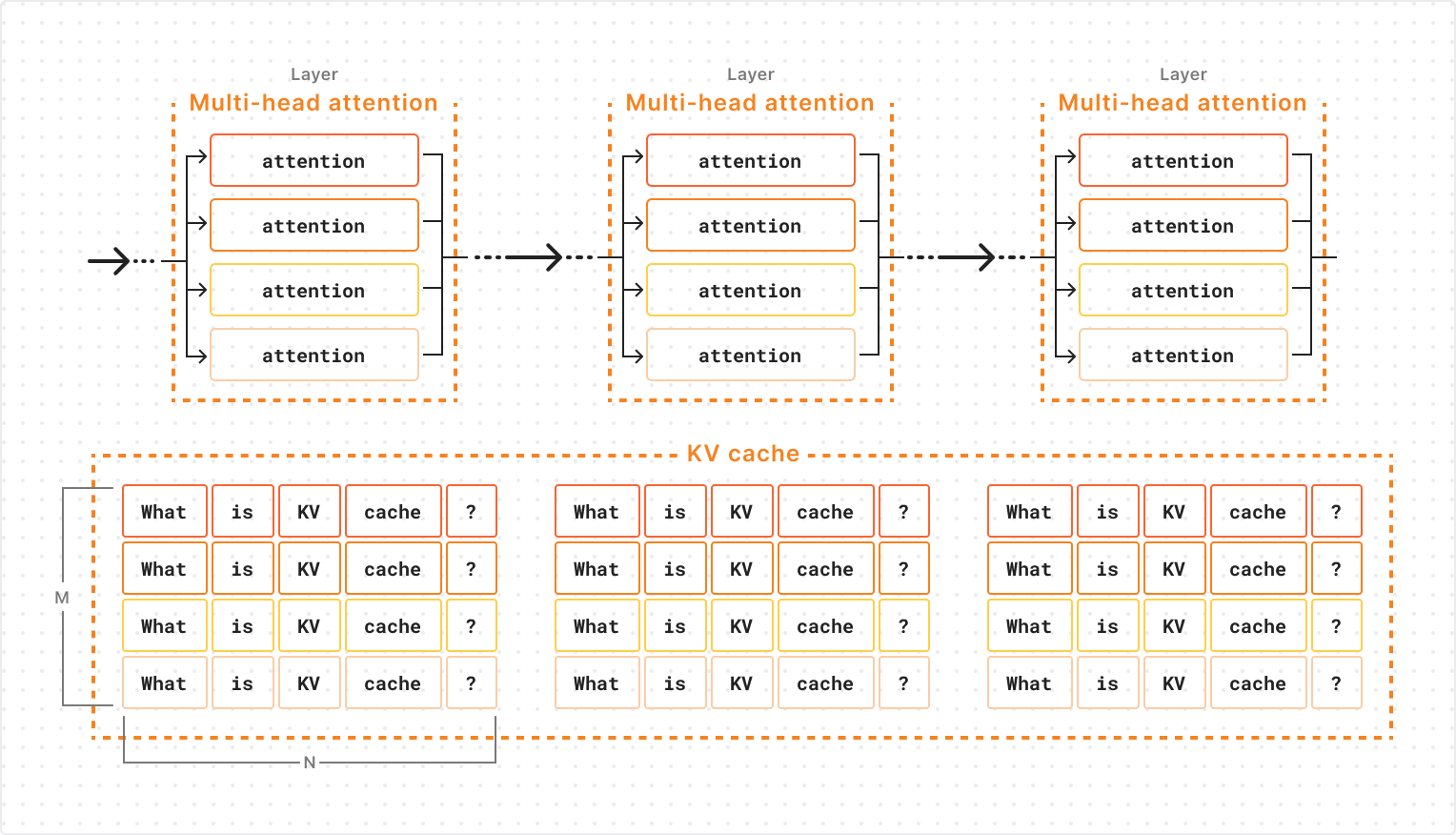
LLMs are made up of layers, with an attention operation occurring in each layer. Within each layer’s attention operation, information is collected from the representations of all previous tokens that are stored in cache. This means that vectors in the KV cache are organized into layers, so that the active layer’s attention operation can only query vectors from the corresponding layer of KV cache. Furthermore, since attention within each layer is parallelized across multiple attention “heads”, the KV cache vectors of a specific layer are further subdivided into groups corresponding to each attention head of that layer.
The diagram below shows the structure of an LLM’s KV cache for a single sequence being generated. Each cell represents a KV and the model’s representation for a token consists of all KV vectors for that token across all attention heads and layers. As you can see, the KV cache for a single layer is allocated as an M x N matrix of KV vectors where M is the number of attention heads and N is the sequence length. This will be important later!
For a deeper look at attention, see the original “Attention is All You Need” paper.
KV-cache compression — “use it or lose it”
Now that we know what the KV cache looks like, let’s dive into how we can shrink it!
The most common approach to compressing the KV cache involves identifying vectors within it that are unlikely to be queried by future attention operations and can therefore be removed without impacting the model’s outputs. This is commonly done by looking at the past attention weights for each pair of key and value vectors (a measure of the degree with which that KV’s representation has been queried during past attention operations) and selecting the KVs that have received the lowest total attention for eviction. This approach is conceptually similar to a LFU (least frequently used) cache management policy: the less a particular vector is queried, the more likely it is to be evicted in the future.
Different attention heads need different compression rates
As we saw earlier, the KV cache for each sequence in a particular layer is allocated on the GPU as a # attention heads X sequence length tensor. This means that the total memory allocation scales with the maximum sequence length for all attention heads of the KV cache. Usually this is not a problem, since each sequence generates the same number of KVs per attention head.
When we consider the problem of eviction-based KV cache compression, however, this forces us to remove an equal number of KVs from each attention head when doing the compression. If we remove more KVs from one attention head alone, those removed KVs won’t actually contribute to lowering the memory footprint of the KV cache on GPU, but will just add more empty “padding” to the corresponding rows of the tensor. You can see this in the diagram below (note the empty cells in the second row below):
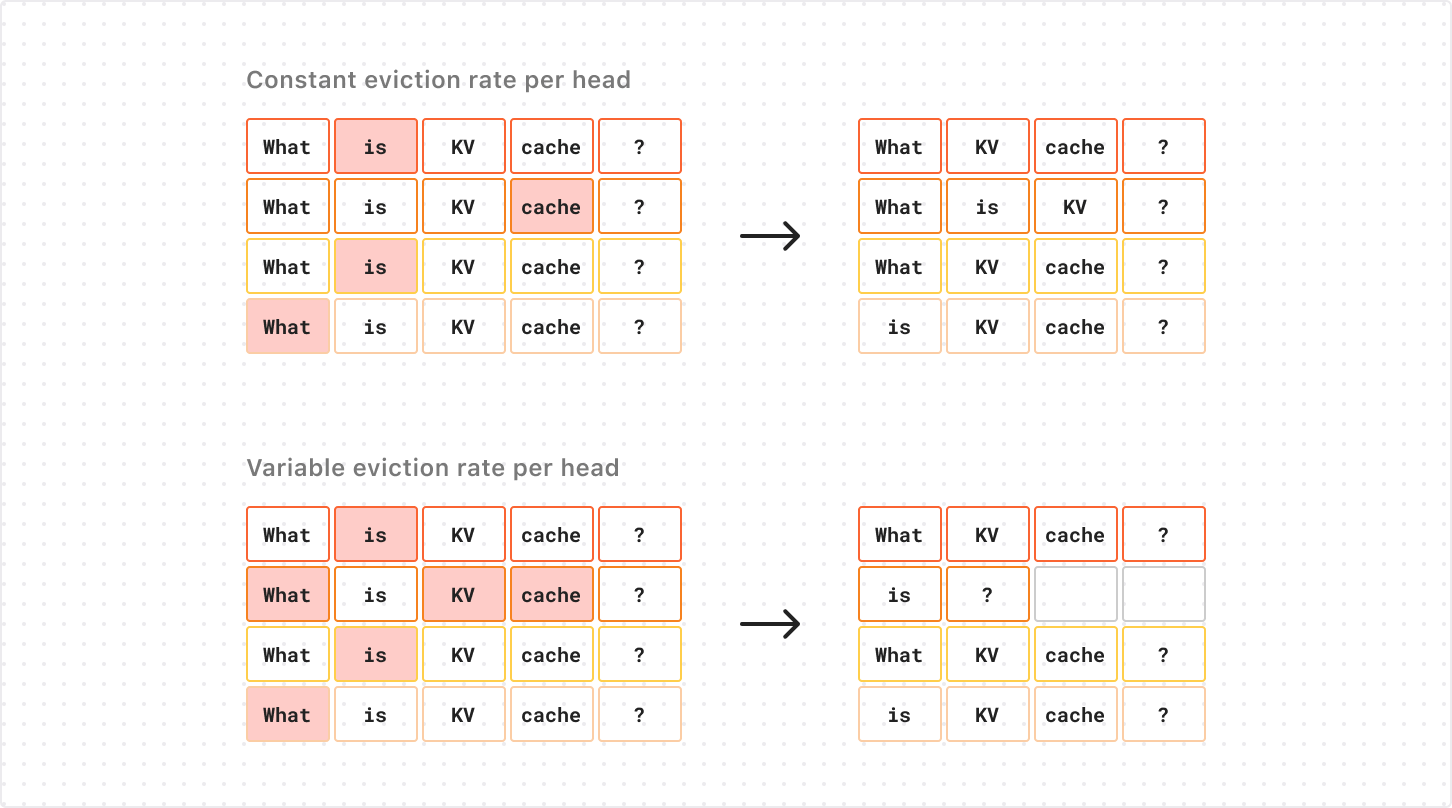
The extra compression along the second head frees slots for two KVs, but the cache’s shape (and memory footprint) remains the same.
This forces us to use a fixed compression rate for all attention heads of KV cache, which is very limiting on the compression rates we can achieve before compromising performance.
Enter PagedAttention
The solution to this problem is to change how our KV cache is represented in physical memory. PagedAttention can represent N x M tensors with padding efficiently by using an N x M block table to index into a series of “blocks”.
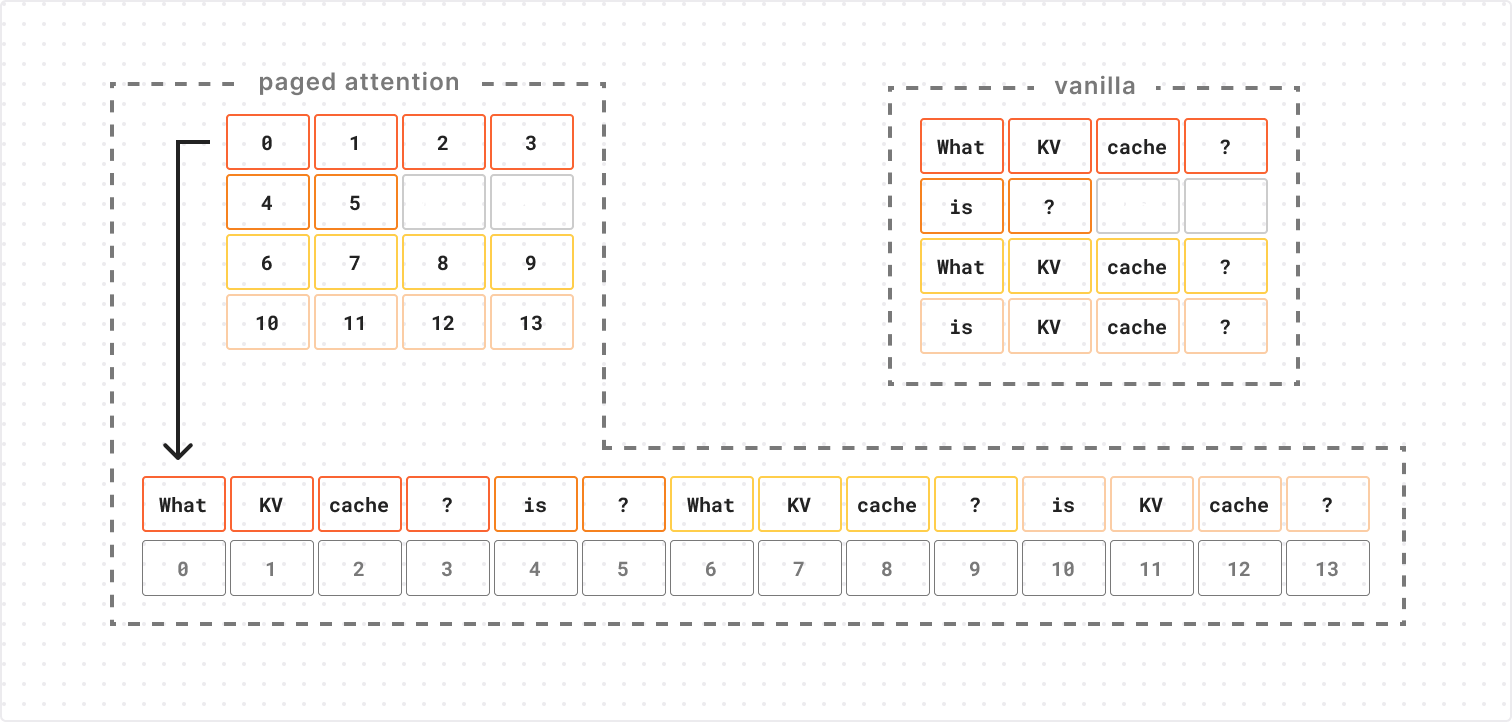
This lets us retrieve the ith element of a row by taking the ith block number from that row in the block table and using the block number to lookup the corresponding block, so we avoid allocating space to padding elements in our physical memory representation. In our case, the elements in physical memory are the KV cache vectors, and the M and N that define the shape of our block table are the number of attention heads and sequence length, respectively. Since the block table is only storing integer indices (rather than high-dimensional KV vectors), its memory footprint is negligible in most cases.
Results
Using paged attention lets us apply different rates of compression to different heads in our KV cache, giving our compression strategy more flexibility than other methods. We tested our compression algorithm on LongBench (a collection of long-context LLM benchmarks) with Llama-3.1-8B and found that for most tasks we can retain over 95% task performance while reducing cache size by up to 8x (left figure below). Over 90% task performance can be retained while further compressing up to 64x. That means you have room in memory for 64 times as many tokens!
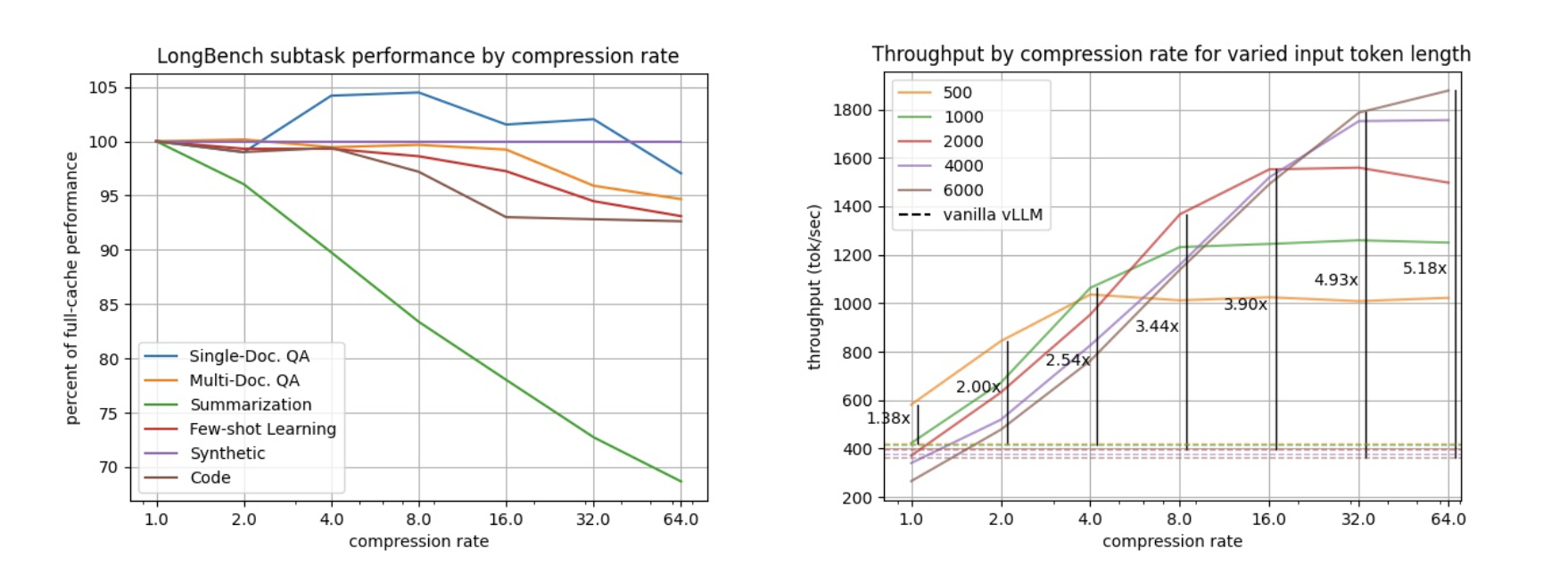
This lets us increase the number of requests we can process in parallel, increasing the total throughput (total tokens generated per second) by 3.44x and 5.18x for compression rates of 8x and 64x, respectively (right figure above).
Try it yourself!
If you’re interested in taking a deeper dive check out our vLLM fork and get compressing!!
Speculative decoding for faster throughput
A new inference strategy that we implemented is speculative decoding, which is a very popular way to get faster throughput (measured in tokens per second). LLMs work by predicting the next expected token (a token can be a word, word fragment or single character) in the sequence with each call to the model, based on everything that the model has seen before. For the first token generated, this means just the initial prompt, but after that each subsequent token is generated based on the prompt plus all other tokens that have been generated. Typically, this happens one token at a time, generating a single word, or even a single letter, depending on what comes next.
But what about this prompt:
Knock, knock!
If you are familiar with knock-knock jokes, you could very accurately predict more than one token ahead. For an English language speaker, what comes next is a very specific sequence that is four to five tokens long: “Who’s there?” or “Who is there?” Human language is full of these types of phrases where the next word has only one, or a few, high probability choices. Idioms, common expressions, and even basic grammar are all examples of this. So for each prediction the model makes, we can take it a step further with speculative decoding to predict the next n tokens. This allows us to speed up inference, as we’re not limited to predicting one token at a time.
There are several different implementations of speculative decoding, but each in some way uses a smaller, faster-to-run model to generate more than one token at a time. For Workers AI, we have applied prompt-lookup decoding to some of the LLMs we offer. This simple method matches the last n tokens of generated text against text in the prompt/output and predicts candidate tokens that continue these identified patterns as candidates for continuing the output. In the case of knock-knock jokes, it can predict all the tokens for “Who’s there” at once after seeing “Knock, knock!”, as long as this setup occurs somewhere in the prompt or previous dialogue already. Once these candidate tokens have been predicted, the model can verify them all with a single forward-pass and choose to either accept or reject them. This increases the generation speed of llama-3.1-8b-instruct by up to 40% and the 70B model by up to 70%.
Speculative decoding has tradeoffs, however. Typically, the results of a model using speculative decoding have a lower quality, both when measured using benchmarks like MMLU as well as when compared by humans. More aggressive speculation can speed up sequence generation, but generally comes with a greater impact to the quality of the result. Prompt lookup decoding offers one of the smallest overall quality impacts while still providing performance improvements, and we will be adding it to some language models on Workers AI including @cf/meta/llama-3.1-8b-instruct.
And, by the way, here is one of our favorite knock-knock jokes, can you guess the punchline?
Knock, knock!
Who’s there?
Figs!
Figs who?
Figs the doorbell, it’s broken!
Keep accelerating
As the AI industry continues to evolve, there will be new hardware and software that allows customers to get faster inference responses. Workers AI is committed to researching, implementing, and making upgrades to our services to help you get fast inference. As an Inference-as-a-Service platform, you’ll be able to benefit from all the optimizations we apply, without having to hire your own team of ML researchers and SREs to manage inference software and hardware deployments.
We’re excited for you to try out some of these new releases we have and let us know what you think! Check out our full-suite of AI announcements here and check out the developer docs to get started.
Source:: CloudFlare