On September 17, 2024, during routine maintenance, Cloudflare inadvertently stopped announcing fifteen IPv4 prefixes, affecting some Business plan websites for approximately one hour. During this time, IPv4 traffic for these customers would not have reached Cloudflare, and users attempting to connect to websites assigned addresses within those prefixes would have received errors.
We’re very sorry for this outage.
This outage was the result of an internal software error and not the result of an attack. In this blog post, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
Cloudflare assembled a dedicated Addressing team in 2019 to simplify the ways that IP addresses are used across Cloudflare products and services. The team builds and maintains systems that help Cloudflare conserve and manage its own network resources. The Addressing team also manages periodic changes to the assignment of IP addresses across infrastructure and services at Cloudflare. In this case, our goal was to reduce the number of IPv4 addresses used for customer websites, allowing us to free up addresses for other purposes, like deploying infrastructure in new locations. Since IPv4 addresses are a finite resource and are becoming more scarce over time, we carry out these kinds of “renumbering” exercises quite regularly.
Renumbering in Cloudflare is carried out using internal processes that move websites between sets of IP addresses. A set of IP addresses that no longer has websites associated with it is no longer needed, and can be retired. Once that has happened, the associated addresses are free to be used elsewhere.
Back in July 2024, a batch of Business plan websites were moved from their original set of IPv4 addresses to a new, smaller set, appropriate to the forecast requirements of that particular plan. On September 17, after confirming that all of the websites using those addresses had been successfully renumbered, the next step was to be carried out: detach the IPv4 prefixes associated with those addresses from Cloudflare’s network and to withdraw them from service. That last part was to be achieved by removing those IPv4 prefixes from the Internet’s global routing table using the Border Gateway Protocol (BGP), so that traffic to those addresses is no longer routed towards Cloudflare. The prefixes concerned would then be ready to be deployed for other purposes.
What was released and how did it break?
When we migrated customer websites out of their existing assigned address space in July, we used a one time migration template that cycles through all the websites associated with the old IP addresses and moves them to new ones. This calls a function that updates the IP assignment mechanism to synchronize the IP address-to-website mapping.
A couple of months prior to the July migration, the relevant function code was updated as part of a separate project related to legacy SSL configurations. That update contained a fix that replaced legacy code to synchronize two address pools with a call to an existing synchronization function. The update was reviewed, approved, merged, and released.
Unfortunately, the fix had consequences for the subsequent renumbering work. Upon closer inspection (we’ve done some very close post-incident inspection), a side effect of the change was to suppress updates in cases where there was no linked reference to a legacy SSL certificate. Since not all websites use legacy certificates, the effect was that not all websites were renumbered — 1,661 customer websites remained linked to old addresses in the address pools that were intended to be withdrawn. This was not noticed during the renumbering work in July, which had concluded with the assumption that every website linked to the old addresses had been renumbered, and that assumption was not checked.
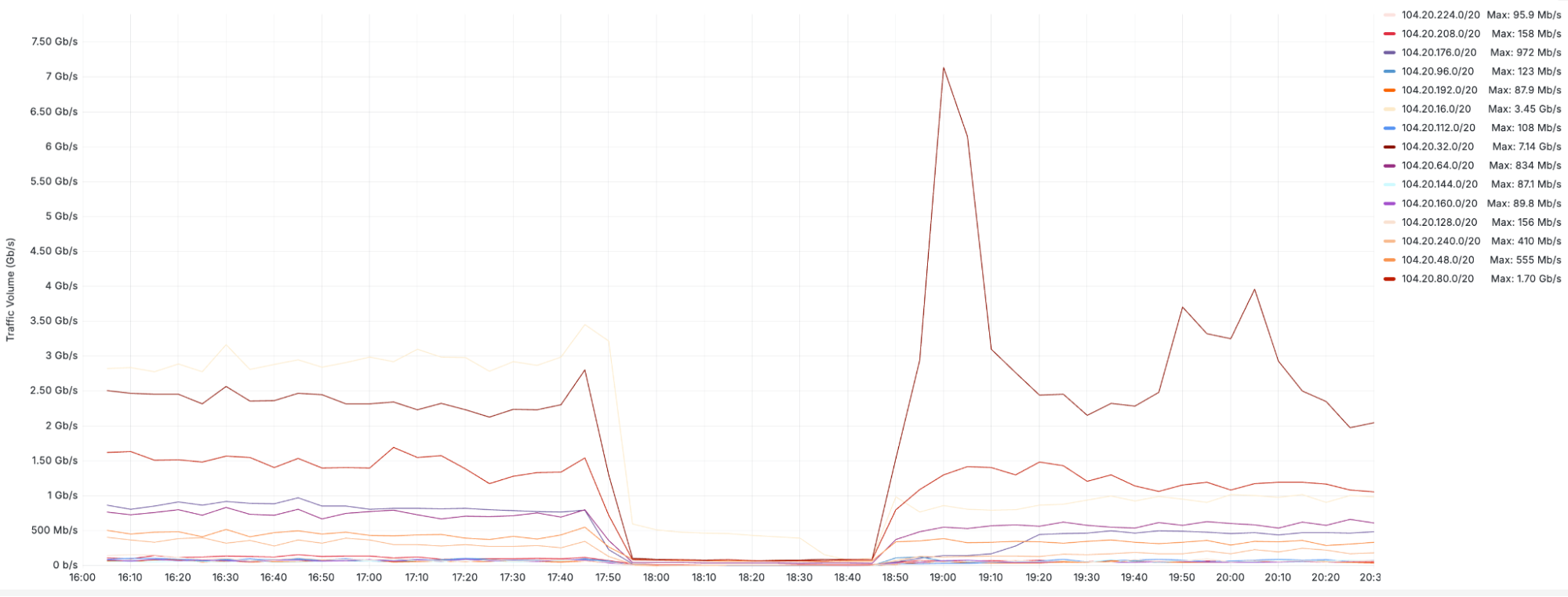
At 2024-09-17 17:51 UTC, fifteen IPv4 prefixes corresponding to the addresses that were thought to be safely unused were withdrawn using BGP. Cloudflare operates a global network with hundreds of data centers, and there was some variation in the precise time when the prefixes were withdrawn from particular parts of the world. In the following ten minutes, we observed an aggregate 10 Gbps drop in traffic to the 1,661 affected websites network-wide.
The graph above shows traffic volume (in bits per second) for each individual prefix that was affected by the incident.
Incident timeline and impact
All timestamps are UTC on 2024-09-17.
At 17:41, the Addressing engineering team initiated the release that disabled prefixes in production.
At 17:51, BGP announcements began to be withdrawn and traffic to Cloudflare on the impacted prefixes started to drop.
At 17:57, the SRE team noticed alerts triggered by an increase in unreachable IP address space and began investigating. The investigation ended shortly afterwards, since it is generally expected that IP addresses will become unreachable when they are being removed from service, and consequently the alerts did not seem to indicate an abnormal situation.
At 18:36, Cloudflare received escalations from two customers, and an incident was declared. A limited deployment window was quickly implemented once the severity of the incident was assessed.
At 18:46, Addressing team engineers confirmed that the change introduced in the renumbering release triggered the incident and began preparing the rollback procedure to revert changes.
At 18:50, the release was rolled back, prefixes were re-announced in BGP to the Internet, and traffic began flowing back through Cloudflare.
At 18:50:27, the affected routes were restored and prefixes began receiving traffic again.
There was no impact to IPv6 traffic. 1,661 customer websites that were associated with addresses in the withdrawn IPv4 prefixes were affected. There was no impact to other customers or services.
How did we fix it?
The immediate fix to the problem was to roll back the release that was determined to be the proximal cause. Since all approved changes have tested roll back procedures, this is often a pragmatic first step to fix whatever has just been found to be broken. In this case, as in many, it was an effective way to resolve the immediate impact and return things to normal.
Identifying the root cause took more effort. The code mentioned above that had been modified earlier this year is quite old, and part of a legacy system that the Addressing team has been working on moving away from since the team’s inception. Much of the engineering effort during that time has been on building the modern replacement, rather than line-level dives into the legacy code.
We have since fixed the specific bug that triggered this incident. However, to address the more general problem of relying on old code that is not as well understood as the code in modern systems, we will do more. Sometimes software has bugs, and sometimes software is old, and these are not useful excuses; they are just the way things are. It’s our job to maintain the agility and confidence in our release processes while living in this reality, maintaining the level of safety and stability that our customers and their customers rely on.
What are we doing to prevent this from happening again?
We take incidents like this seriously, and we recognise the impact that this incident had. Though this specific bug has been resolved, we have identified several steps we can take to mitigate the risk of a similar problem occurring in the future. We are implementing the following plan as a result of this incident:
Test: The Addressing Team is adding tests that check for the existence of outstanding assignments of websites to IP addresses as part of future renumbering exercises. These tests will verify that there are no remaining websites that inadvertently depend on the old addresses being in service. The changes that prompted this incident made incorrect assumptions that all websites had been renumbered. In the future, we will avoid making assumptions like those, and instead do explicit checks to make sure.
Process: The Addressing team is improving the processes associated with the withdrawal of Cloudflare-owned prefixes, regardless of whether the withdrawal is associated with a renumbering event, to include automated and manual verification of traffic levels associated with the addresses that are intended to be withdrawn. Where traffic is attached to a service that provides more detailed logging, service-specific request logs will be checked for signs that the addresses thought to be unused are not associated with active traffic.
Implementation: The Addressing Team is reviewing every use of stored procedures and functions associated with legacy systems. Where there is doubt, functionality will be re-implemented with present-day standards of documentation and test coverage.
We are sorry for the disruption this incident caused for our customers. We are actively making these improvements to ensure improved stability moving forward and to prevent this problem from happening again.
Source:: CloudFlare