
In the AI landscape of 2023, vector search is one of the hottest topics due to its applications in large language models (LLM) and generative AI. Semantic…
In the AI landscape of 2023, vector search is one of the hottest topics due to its applications in large language models (LLM) and generative AI. Semantic vector search enables a broad range of important tasks like detecting fraudulent transactions, recommending products to users, using contextual information to augment full-text searches, and finding actors that pose potential security risks.
Data volumes continue to soar and traditional methods for comparing items one by one have become computationally infeasible. Vector search methods use approximate lookups, which are more scalable and can handle massive amounts of data more efficiently. As we show in this post, accelerating vector search on the GPU provides not only faster search times, but the index building times can also be substantially faster.
This post provides:
- An introduction to vector search with a brief review of popular applications
- An overview of the RAFT library for accelerating vector search on the GPU
- Performance comparison of GPU-accelerated vectors search indexes against the state-of-the-art on the CPU
The second post in this series dives deeper into each of the GPU-accelerated indexes mentioned in this post and gives a brief explanation of how the algorithms work, along with a summary of important parameters to fine-tune their behavior. For more information, see Accelerating Vector Search: Fine-Tuning GPU Index Algorithms.
What is vector search?
 Figure 1. Vector search process
Figure 1. Vector search process
Figure 1 shows that vector search entails creating an index of vectors and performing lookups to find some number of vectors in the index that are closest to a query vector. The vectors could be as small as three-dimensional points from a lidar point cloud or larger embeddings from text documents, images, or videos.
Vector search is the process of querying a database to find the most similar vectors. This similarity search is done on numerical vectors that can represent any type of object (Figure 2). These vectors are often embeddings created from multimedia like images, video, and text fragments or entire documents that went through a deep learning model to encode their semantic characteristics into a vector form.
Embedding vectors typically have the advantage of being a smaller object than the original document (lower dimensionality), while maintaining as much information about the source as possible. Therefore, two documents that are similar often have similar embeddings.
 Figure 2. Vectors represent data points in higher dimensions
Figure 2. Vectors represent data points in higher dimensions
The points in Figure 2 are 3D but they could be 500 dimensions or even higher.
This makes it easier to compare objects, as the embedding vectors are smaller and retain most of the information. When two documents share similar characteristics, their embedding vectors are often spatially close, or similar.
Approximate methods for vector search
To handle larger datasets efficiently, approximate nearest neighbor (ANN) methods are often used for vector search. ANN methods speed up the search by approximating the closest vectors. This avoids the exhaustive distance computation often required by an exact brute-force approach, which requires comparing the query against every single vector in the database.
In addition to the search compute cost, storing many vectors can also consume a large amount of memory. To ensure both fast searches and low memory usage, you must index vectors in an efficient way. As we outline a bit later, this can sometimes benefit from compression. A vector index is a space-efficient data structure built on mathematical models that is used for efficiently querying several vectors at a time.
Updating the indexes, such as from inserting and deleting vectors, can cause problems when indexes take hours or even days to build. It turns out that these indexes can often be built much faster on the GPU. We showcase this performance later in the post.
Vector search in LLMs
LLMs have become popular for capturing and preserving the semantic meaning and context of the original documents. This means that the vectors resulting from LLM models can be searched using vector similarity search. This search finds items that happen to contain similar words, shapes, or moving objects. It also finds vectors that contextually and semantically mean similar things.
This semantic search doesn’t rely on exact word matching. For example, searching for the term, “I would like to buy a muscle car” in an image database should be able to contextualize the sentence to understand the following:
- Buying a car is different from renting a car, so you’d expect to find vectors closer to car dealerships and reviews from car purchasers, rather than car rental companies.
- A muscle car is different from a bodybuilder so you’d expect to find vectors about Dodge Chargers and not Arnold Schwarzenegger.
- Buying a muscle car is different from buying muscle relaxers or economy vehicles.
More recently, large language transformer-based models like ChatGPT, LLaMa, NeMo, and BERT have provided significant technical leaps that are increasing the contextual awareness of the models and making them even more useful and applicable to more industries.
In addition to creating embedding vectors that can be stored and later searched, these new LLM models use semantic search in pipelines that generate new content from context gleaned by finding similar vectors. This content generation process, shown in Figure 3, is known as retrieval-augmented generative AI.
Using vector search in a vector database
A vector database stores high-dimensional vectors (for example, embeddings), and facilitates fast and accurate search and retrieval based on vector similarity (for example, ANN algorithms). Some databases are purpose-built for vector search (for example, Milvus). Other databases include vector search capabilities as an additional feature (for example, Redis).
Choosing which vector database to use depends on the requirements of your workflow.
Retrieval-augmented language models allow pretrained models to be customized for specific products, services, or other domain-specific use cases by augmenting a search with additional context that has been encoded into vectors by the LLM and stored in a vector database.
More specifically, a search is encoded into vector form and similar vectors are found in the vector database to augment the search. The vectors are then used with the LLM to formulate an appropriate response. Retrieval-augmented LLMs are a form of generative AI and they have revolutionized the industry of chatbots and semantic text search.
Figure 3. Example workflow of a text retrieval application using RAPIDS RAFT for vector search
Other applications of vector similarity search
In addition to retrieval-augmented LLMs for generative AI, vector embeddings have been around for some time and have found many useful applications in the real world:
- Recommender systems: Provide personalized suggestions according to what a user has shown interest in or interacted with.
- Finance: Fraud detection models vectorize user transactions, making it possible to determine whether those transactions are similar to typical fraudulent activities.
- Cybersecurity: Uses embeddings to model and search behaviors of bad actors and anomalous activities.
- Genomics: Finds similar genes and cell structures in genomics analysis, such as single-cell RNA analysis.
- Chemistry: Models molecular descriptors or fingerprints of chemical structures to compare them or find similar structures in a database.
We are always interested in learning about your use cases so don’t hesitate to leave a comment if you either use vector search already or would like to discuss how it could benefit your application.
RAPIDS RAFT library for vector search
RAFT is a library of composable building blocks for accelerating machine learning algorithms on the GPU, such as those used in nearest neighbors and vector search. ANN algorithms are among the core building blocks that comprise vector search libraries. Most importantly, these algorithms can greatly benefit from GPU acceleration.
For more information about RAFT’s core APIs and the various accelerated building blocks that it contains, see Reusable Computational Patterns for Machine Learning and Data Analytics with RAPIDS RAFT.
ANN for fast searches
In addition to brute-force for exact search, RAFT currently provides three different algorithms for ANN search:
- IVF-Flat
- IVF-PQ
- CAGRA
The choice of the algorithm can depend upon your needs, as they each offer different advantages. Sometimes, brute force can even be the better option. More are being added in upcoming releases.
Because these algorithms are not doing an exact search, it is possible that some highly similar vectors are missed. The recall metric can be used to represent how many neighbors in the results are actual nearest neighbors of the query. Most of our benchmarks target recall levels of 85% and higher, meaning 85% (or more) of the relevant vectors were retrieved.
To tune the resulting indexes for different levels of recall, use various settings, or hyperparameters, when training approximate nearest-neighbors algorithms. Reducing the recall score often increases the speed of your searches and increasing the recall decreases the speed. This is known as the recall-speed tradeoff.
For more information, see Accelerating Vector Search: Fine-Tuning GPU Index Algorithms.
Performance comparison
GPUs excel at processing a lot of data at one time. All the algorithms just mentioned can outperform corresponding algorithms on the CPU when computing the nearest neighbors for thousands or tens of thousands of points at a time.
However, CAGRA was specifically engineered with online search in mind, which means that it outperforms the CPU even when only querying the nearest neighbors for a few data points at a time.
Figure 4 and Figure 5 show benchmarks that we performed by building an index on 100M vectors and querying only 10 vectors at a time. In Figure 4, CAGRA outperforms HNSW, which is one of the most popular indexes for vector search on CPU, in raw search performance even for an extremely small batch size of 10 vectors. This speed comes at a memory cost, however. In Figure 5, you can see that CAGRA’s memory footprint is a bit higher than the other nearest neighbors methods.
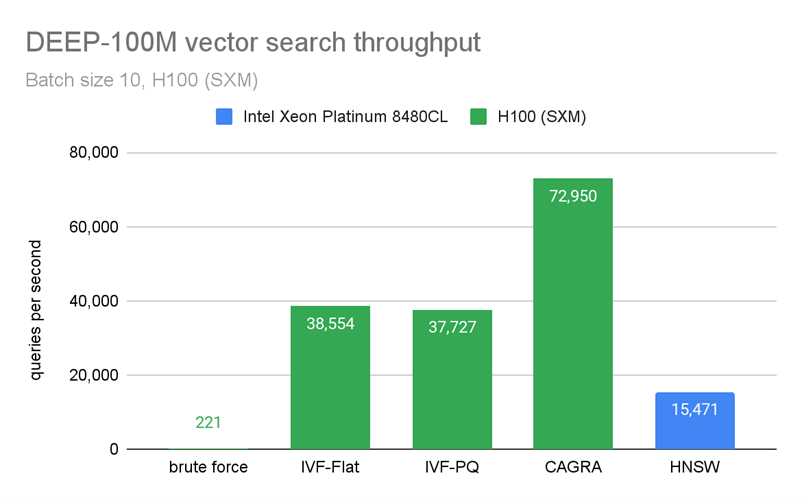 Figure 4. Vector search throughput at 95% recall on DEEP-100M dataset, batch size of 10
Figure 4. Vector search throughput at 95% recall on DEEP-100M dataset, batch size of 10
In Figure 5, the host memory of IVF-PQ is for the optional refinement step.
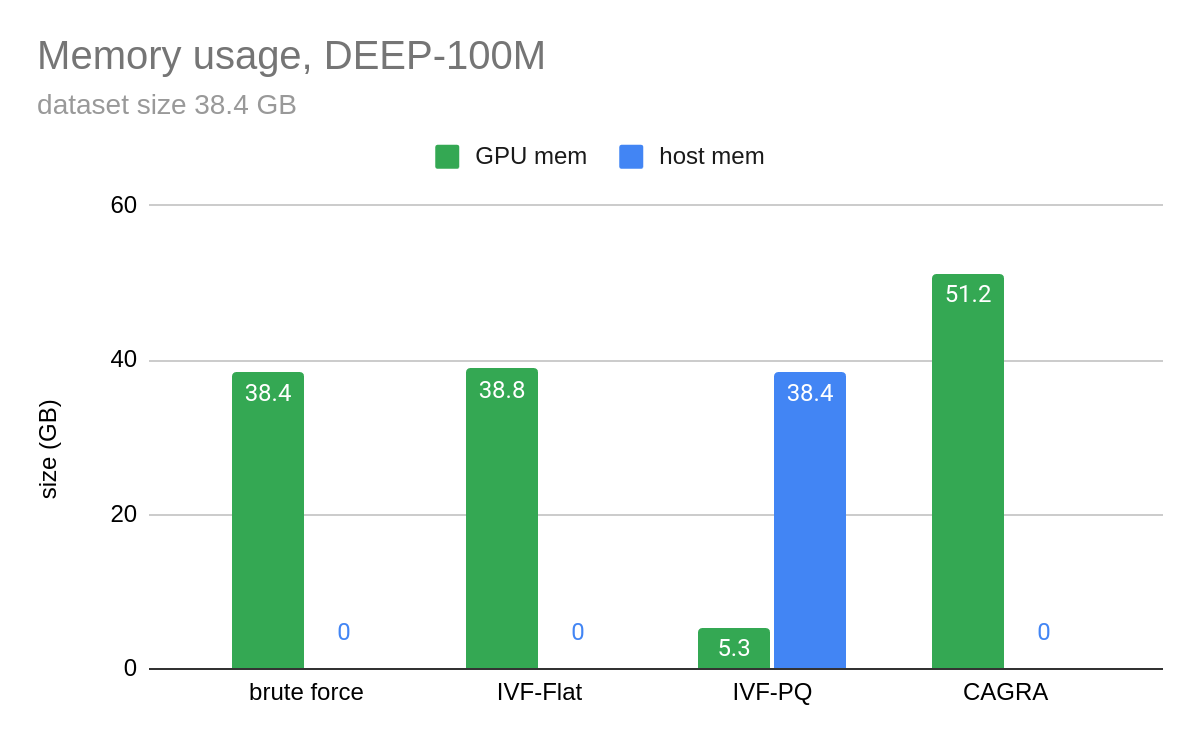 Figure 5. GPU memory usage
Figure 5. GPU memory usage
Figure 6 presents a comparison of the index build times and shows that indexes can often be built faster on the GPU.
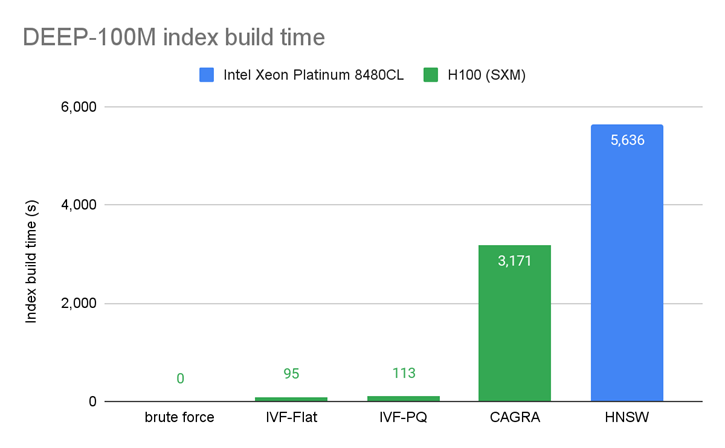 Figure 6. Index build time for the best-performing index at 95% recall
Figure 6. Index build time for the best-performing index at 95% recall
Summary
From feature stores to generative AI, vector similarity search can be applied in every industry. Vector search on the GPU performs at lower latency and achieves higher throughput for every level of recall for both online and batch processing.
RAFT is a set of composable building blocks that can be used to accelerate vector search in any data source. It has pre-built APIs for Python and C++. Integration for RAFT is underway for Milvus, Redis, and FAISS. We encourage database providers to try RAFT and consider integrating it into their data sources.
In addition to state-of-the-art ANN algorithms, RAFT contains other GPU-accelerated building blocks, such as matrix and vector operations, iterative solvers, and clustering algorithms. The second post in this series dives deeper into each of the GPU-accelerated indexes mentioned in this post and gives a brief explanation of how the algorithms work, along with a summary of important parameters to fine-tune their behavior. For more information, see Accelerating Vector Search: Fine-Tuning GPU Index Algorithms.
RAPIDS RAFT is fully open source and available on the /rapidsai/raft GitHub repo. You can also follow us on Twitter at @rapidsai.
Source:: NVIDIA