
One of the main challenges for businesses leveraging AI in their workflows is managing the infrastructure needed to support large-scale training and deployment…
One of the main challenges for businesses leveraging AI in their workflows is managing the infrastructure needed to support large-scale training and deployment of machine learning (ML) models. The NVIDIA FLARE platform provides a solution: a powerful, scalable infrastructure for federated learning that makes it easier to manage complex AI workflows across enterprises.
NVIDIA FLARE 2.3.0 is the latest release of the NVIDIA federated learning platform. It comes packed with exciting new features and enhancements, including:
- Multi-cloud support using infrastructure-as-code (IaC)
- Natural language processing (NLP) examples, including BERT and GPT-2
- Split learning for separating data and labels
This post takes a closer look at these features and explores how they can help your organization boost your AI workflows and achieve better results with machine learning.
Multi-cloud deployment
With this release, you can now seamlessly manage your multi-cloud infrastructure using IaC, leverage the strengths of different cloud providers, and distribute your workloads for improved efficiency and reliability. IaC enables you to automate the management and deployment of your infrastructure, saving time and reducing the risk of human error. NVIDIA FLARE 2.3.0 supports automated deployment on Microsoft Azure and AWS clouds.
To deploy NVIDIA FLARE in the cloud, use the NVIDIA FLARE CLI commands to create the infrastructure, deploy, and start the Dashboard UI, FL Server, and FL Client(s). To create and deploy NVIDIA FLARE in the cloud, follow the commands from the NVIDIA FLARE startup kit, which is a signed software package generated from the NVIDIA FLARE provisioning process and distributed to server and clients.
/start.sh --cloud azure | aws
/start.sh --cloud azure | aws
nvflare dashboard --cloud azure | awsThese commands will create the resource group, networking, security, compute runtime instances, and more (infrastructure-as-code) and deploy the NVIDIA FLARE client or server to the newly created virtual machine (VM). Each startup kit contains a unique configuration for the FLARE server or client that can be deployed independently. This gives users the flexibility to deploy on-prem or on a mix of cloud service providers (for example server on AWS and clients on Azure and/or AWS) for a simple hybrid multi-cloud configuration.
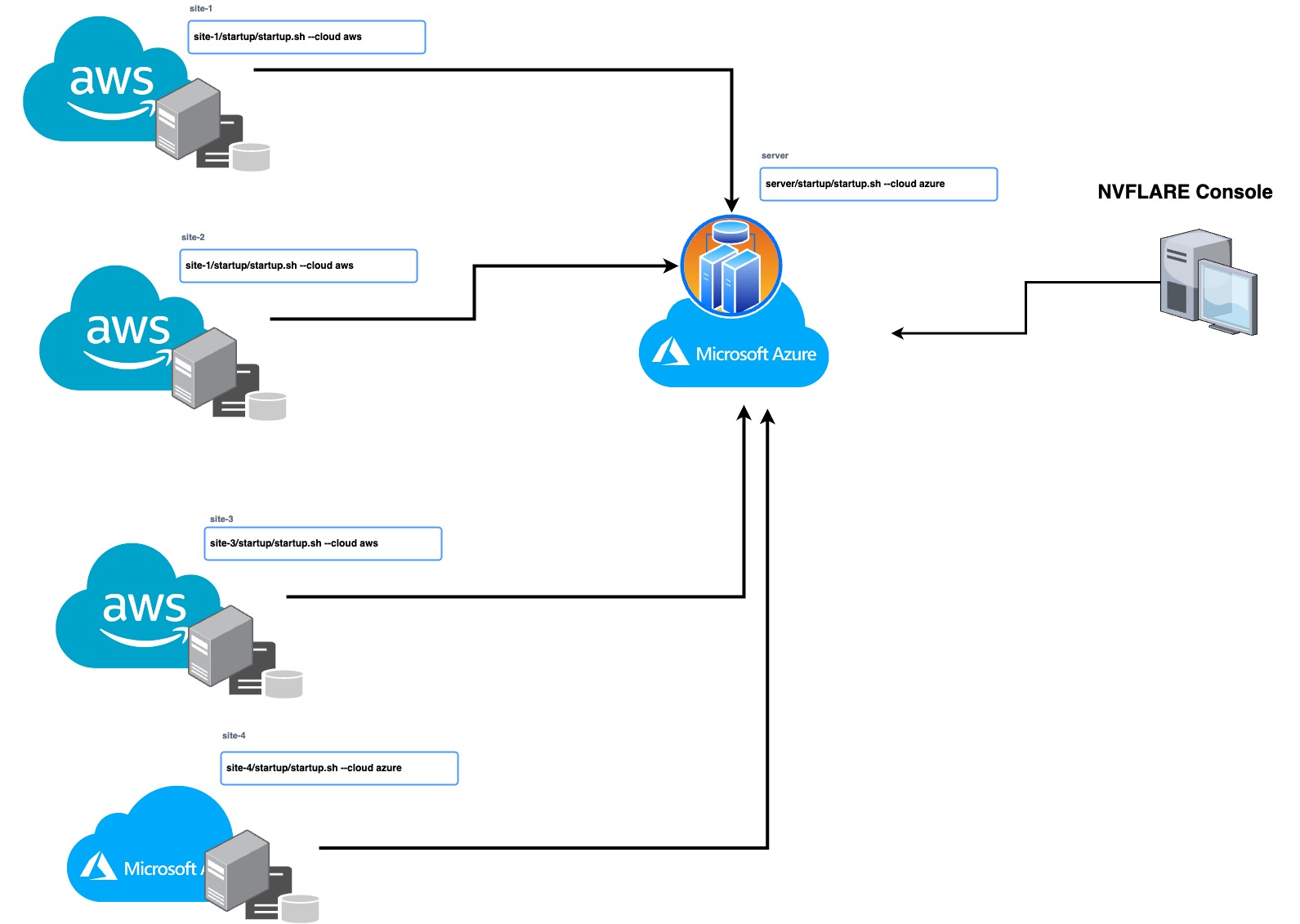 Figure 1. The NVIDIA FLARE one-line CLI command for setting up a multi-cloud deployment
Figure 1. The NVIDIA FLARE one-line CLI command for setting up a multi-cloud deployment
LLMs and federated learning
Large language models (LLMs) are unlocking new possibilities in numerous industries. Drug discovery in healthcare is one example—see Build Generative AI Pipelines for Drug Discovery with NVIDIA BioNeMo Service for more details.
Leveraging federated learning in LLM training has many benefits, including:
- Preserving data privacy: Models can be trained without data leaving the premises. This can be important even within the same organization, where the data resides in different divisions in different parts of the world. For example, it may not be possible to copy the data stored in Europe and China into a centralized data lake, given the different national privacy laws.
- Avoiding data movement: Even if privacy is not a concern, copying a large amount of data from one location to another requires time and money.
- Leveraging data diversity: When different sites have different types of data, training a model through federated learning can leverage this data diversity to improve the global model.
- Achieving task diversity: Training models with various tasks can promote model performance. This can also be achieved through federated learning.
- Computing cost distribution: Training LLMs requires many resources and can be expensive. It is challenging to find one institute with sufficient computing resources for the task. With federated learning, it is possible to leverage the compute resources from multiple locations to train a model shared by all participants.
- Training parallelism: Federated learning enables both data and model parallelism for model training through horizontal data splits and splitting different layers of model into different locations.
To illustrate these capabilities, NVIDIA FLARE 2.3.0 introduces NLP named entity recognition (NER) examples with GPT-2 (Generative Pretrained Transformer 2) and BERT (Bidirectional Encoder Representations from Transformers) models. Visit NVIDIA/NVFlare on GitHub for more details. Parameter-efficient tuning and related work are in progress, along with additional LLM model examples for future releases.
Federated NLP
NVIDIA FLARE has the capability to support a variety of NLP tasks with different backbone models, such as NER, text classification, and language generation.
This release focuses on the application of NER using the NCBI disease dataset, which contains abstracts from biomedical research papers annotated with disease mentions. The dataset is commonly used for benchmarking NER models in the biomedical domain. For more information, see NCBI Disease Corpus: A Resource for Disease Name Recognition and Concept Normalization.
The task of NER involves identifying named entities in text and classifying them into predefined categories. In the case of the NCBI disease dataset, the objective is to recognize and capture the disease mentions.
To tackle the NER task, the NVIDIA FLARE example explores the use of two popular models, BERT and GPT-2. BERT is a pretrained transformer-based model that is widely used for a variety of NLP tasks, including NER. GPT-2 is another transformer-based model that is primarily used for language generation, but can also be fine-tuned for NER.
The BERT-base-uncased and GPT-2 models have 110 million and 124 million parameters, respectively. The number of parameters in a model is an indication of its size and complexity. Larger models with more parameters tend to learn more intricate relationships within the data. However, they also require more computing resources and take longer to train than smaller models.
Upcoming releases will include support for larger, billion-parameter models and other tasks.
Split learning
Split learning is a technique that enables multiple parties to collaboratively train a machine learning model on their respective datasets without having to share their raw data with each other. The model is split into two or more parts, and each part can run on one of the participating parties.
This approach has several advantages over traditional ML methods, especially in scenarios where data privacy is a major concern. Like federated learning, split learning never shares raw data among the parties. This means that sensitive information can be kept confidential, while enabling the parties to gain insights and benefit from the collaboration.
The NVIDIA FLARE 2.3.0 release shows an example of split learning in which the data and label can be separated into two different sites. It is possible to achieve data and model protection by placing part of the model on one site and sending activations/embeddings to another site to calculate the loss. This technique can be seen in the CIFAR10 split learning example.
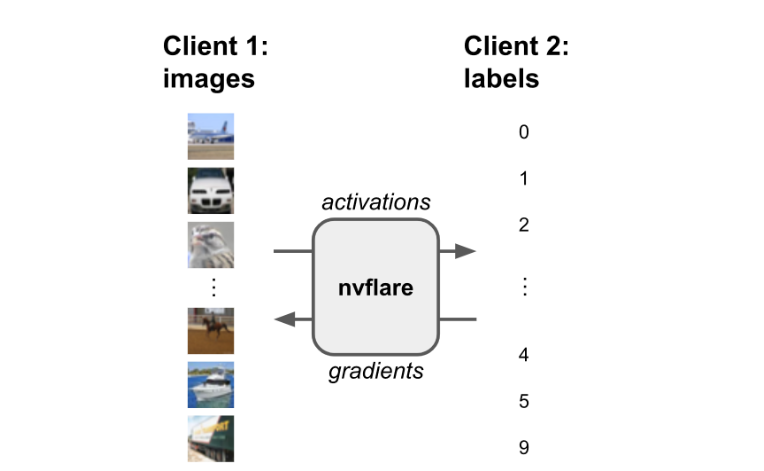 Figure 2. Splitting the data and labels across different clients keeps sensitive information confidential
Figure 2. Splitting the data and labels across different clients keeps sensitive information confidential
Get started with NVIDIA FLARE 2.3.0
NVIDIA FLARE 2.3.0 enables you to quickly deploy to multi-cloud and explore NLP examples for LLMs, and demonstrates split learning capability. By incorporating these features into workflows, teams can save time, improve accuracy, reduce risk, and boost AI workflows.
In addition to the features detailed in this post, NVIDIA FLARE 2.3.0 comes with many other features, including:
- Traditional ML, as detailed in Federated Traditional Machine Learning Algorithms
- Private set intersection (PSI) for calculating multi-party private set intersection; used for vertical learning as part of preprocessing
- FLARE API for interacting with federated learning jobs
For more information, check out the NVIDIA FLARE documentation, NVIDIA AI and Data Science forum, NVIDIA/NVFlare on GitHub, and the paper, NVIDIA FLARE: Federated Learning from Simulation to Real-World.
Source:: NVIDIA