On 14 July 2025, Cloudflare’s 1.1.1.1 Resolver service became unavailable to the Internet starting at 21:52 UTC and ending at 22:54 UTC. The majority of 1.1.1.1 users globally were affected. For many users, not being able to resolve names using the 1.1.1.1 Resolver meant that basically all Internet services were unavailable. This outage can be observed on Cloudflare Radar.
The outage occurred because of a misconfiguration of legacy systems used to maintain the infrastructure that advertises Cloudflare’s IP addresses to the Internet.
This was a global outage. During the outage, Cloudflare’s 1.1.1.1 Resolver was unavailable worldwide.
We’re very sorry for this outage. The root cause was an internal configuration error and not the result of an attack or a BGP hijack. In this blog, we’re going to talk about what the failure was, why it occurred, and what we’re doing to make sure this doesn’t happen again.
Background
Cloudflare introduced the 1.1.1.1 public DNS Resolver service in 2018. Since the announcement, 1.1.1.1 has become one of the most popular DNS Resolver IP addresses and it is free for anyone to use.
Almost all of Cloudflare’s services are made available to the Internet using a routing method known as anycast, a well-known technique intended to allow traffic for popular services to be served in many different locations across the Internet, increasing capacity and performance. This is the best way to ensure we can globally manage our traffic, but also means that problems with the advertisement of this address space can result in a global outage.
Cloudflare announces these anycast routes to the Internet in order for traffic to those addresses to be delivered to a Cloudflare data center, providing services from many different places. Most Cloudflare services are provided globally, like the 1.1.1.1 public DNS Resolver, but a subset of services are specifically constrained to particular regions.
These services are part of our Data Localization Suite (DLS), which allows customers to configure Cloudflare in a variety of ways to meet their compliance needs across different countries and regions. One of the ways in which Cloudflare manages these different requirements is to make sure the right service’s IP addresses are Internet-reachable only where they need to be, so your traffic is handled correctly worldwide. A particular service has a matching “service topology” – that is, traffic for a service should be routed only to a particular set of locations.
On June 6, during a release to prepare a service topology for a future DLS service, a configuration error was introduced: the prefixes associated with the 1.1.1.1 Resolver service were inadvertently included alongside the prefixes that were intended for the new DLS service. This configuration error sat dormant in the production network as the new DLS service was not yet in use, but it set the stage for the outage on July 14. Since there was no immediate change to the production network there was no end-user impact, and because there was no impact, no alerts were fired.
Incident Timeline
Time (UTC)
Event
2025-06-06 17:38
ISSUE INTRODUCED – NO IMPACT
A configuration change was made for a DLS service that was not yet in production. This configuration change accidentally included a reference to the 1.1.1.1 Resolver service and, by extension, the prefixes associated with the 1.1.1.1 Resolver service.
This change did not result in a change of network configuration, and so routing for the 1.1.1.1 Resolver was not affected.
Since there was no change in traffic, no alerts fired, but the misconfiguration lay dormant for a future release.
2025-07-14 21:48
IMPACT START
A configuration change was made for the same DLS service. The change attached a test location to the non-production service; this location itself was not live, but the change triggered a refresh of network configuration globally.
Due to the earlier configuration error linking the 1.1.1.1 Resolver’s IP addresses to our non-production service, those 1.1.1.1 IPs were inadvertently included when we changed how the non-production service was set up.
The 1.1.1.1 Resolver prefixes started to be withdrawn from production Cloudflare data centers globally.
2025-07-14 21:52
DNS traffic to 1.1.1.1 Resolver service begins to drop globally
2025-07-14 21:54
Related, non-causal event: BGP origin hijack of 1.1.1.0/24 exposed by withdrawal of routes from Cloudflare. This was not a cause of the service failure, but an unrelated issue that was suddenly visible as that prefix was withdrawn by Cloudflare.
2025-07-14 22:01
IMPACT DETECTED
Internal service health alerts begin to fire for the 1.1.1.1 Resolver
2025-07-14 22:01
INCIDENT DECLARED
2025-07-14 22:20
FIX DEPLOYED
Revert was initiated to restore the previous configuration. To accelerate full restoration of service, a manually triggered action is validated in testing locations before being executed.
2025-07-14 22:54
IMPACT ENDS
Resolver alerts cleared and DNS traffic on Resolver prefixes return to normal levels
2025-07-14 22:55
INCIDENT RESOLVED
Impact
Any traffic coming to Cloudflare via 1.1.1.1 Resolver services on these IPs was impacted. Traffic to each of these addresses were also impacted on the corresponding routes.
1.1.1.0/24
1.0.0.0/24
2606:4700:4700::/48
162.159.36.0/24
162.159.46.0/24
172.64.36.0/24
172.64.37.0/24
172.64.100.0/24
172.64.101.0/24
2606:4700:4700::/48
2606:54c1:13::/48
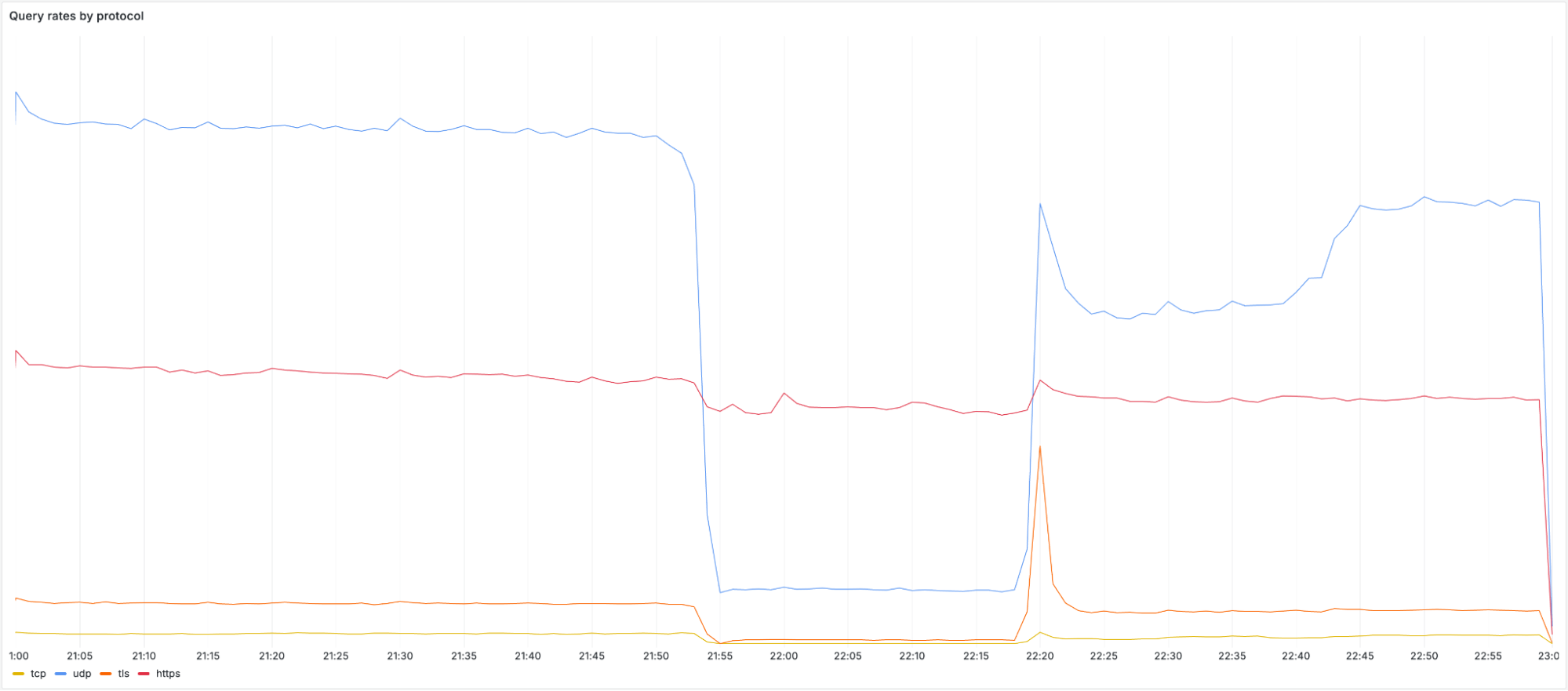
2a06:98c1:54::/48When the impact started we observed an immediate and significant drop in queries over UDP, TCP and DNS over TLS (DoT). Most users have 1.1.1.1, 1.0.0.1, 2606:4700:4700::1111, or 2606:4700:4700::1001 configured as their DNS server. Below you can see the query rate for each of the individual protocols and how they were impacted during the incident:
It’s worth noting that DoH (DNS-over-HTTPS) traffic remained relatively stable as most DoH users use the domain cloudflare-dns.com, configured manually or through their browser, to access the public DNS resolver, rather than by IP address. DoH remained available and traffic was mostly unaffected as cloudflare-dns.com uses a different set of IP addresses. Some DNS traffic over UDP that also used different IP addresses remained mostly unaffected as well.
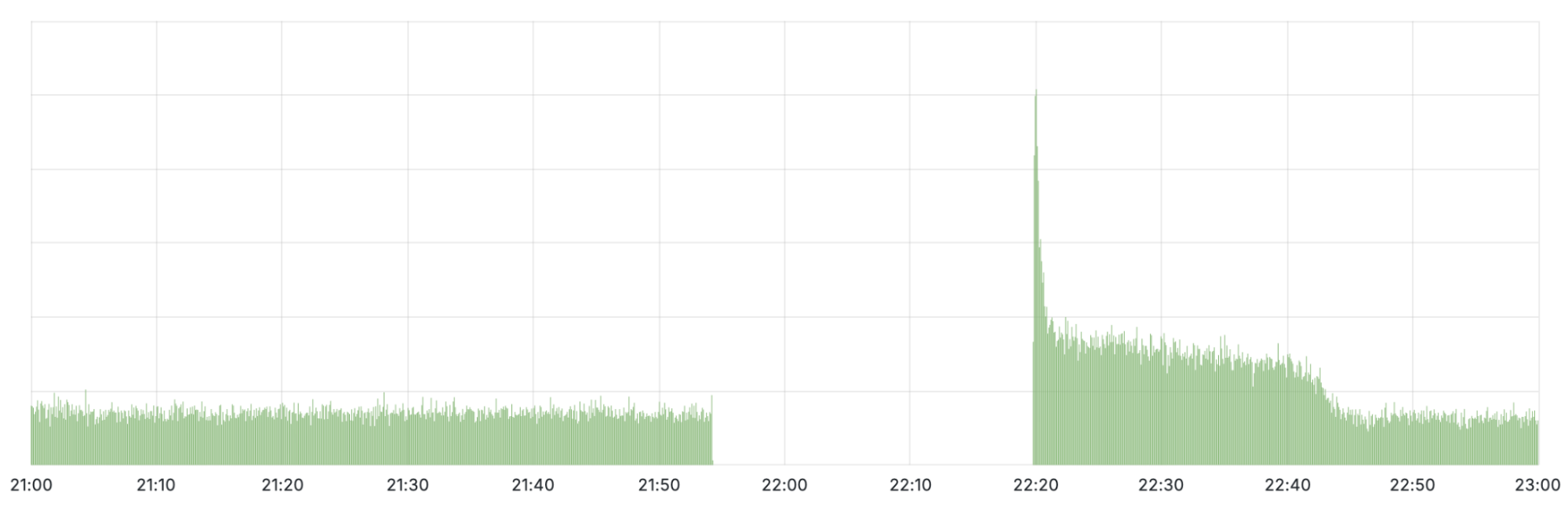
As the corresponding prefixes were withdrawn, no traffic sent to those addresses could reach Cloudflare. We can see this in the timeline for the BGP announcements for 1.1.1.0/24:

Pictured above is the timeline for BGP withdrawal and re-announcement of 1.1.1.0/24 globally
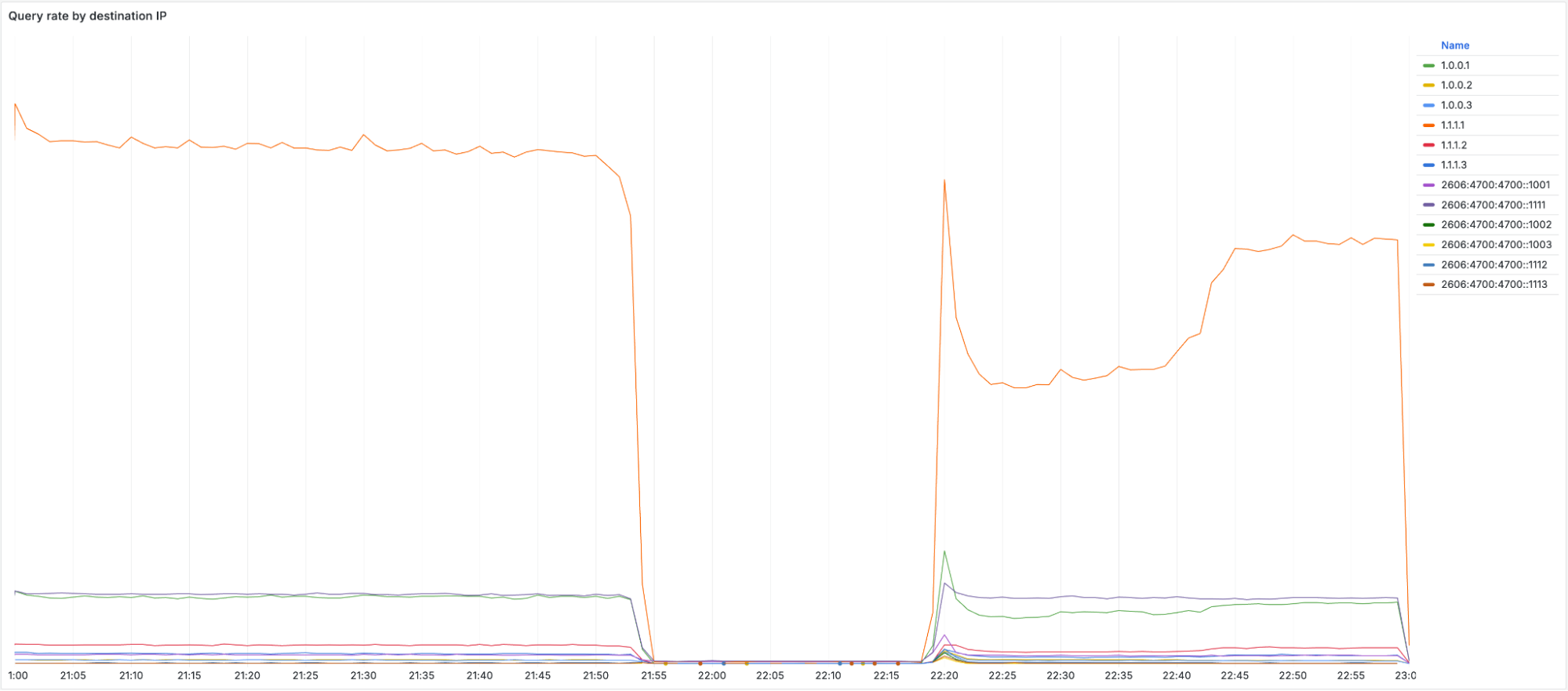
When looking at the query rate of the withdrawn IPs it can be observed that almost no traffic arrives during the impact window. When the initial fix was applied at 22:20 UTC, a large spike in traffic can be seen before it drops off again. This spike is due to clients retrying their queries. When we started announcing the withdrawn prefixes again, queries were able to reach Cloudflare once more. It took until 22:54 UTC before routing was restored in all locations and traffic returned to mostly normal levels.
Technical description of the error and how it happened
Failure of 1.1.1.1 Resolver Service
As described above, a configuration change on June 6 introduced an error in the service topology for a pre-production, DLS service. On July 14, a second change to that service was made: an offline data center location was added to the service topology for the pre-production DNS service in order to allow for some internal testing. This change triggered a refresh of the global configuration of the associated routes, and it was at this point that the impact from the earlier configuration error was felt. The service topology for the 1.1.1.1 Resolver’s prefixes was reduced from all locations down to a single, offline location. The effect was to trigger the global and immediate withdrawal of all 1.1.1.1 prefixes.
As routes to 1.1.1.1 were withdrawn, the 1.1.1.1 service itself became unavailable. Alerts fired and an incident was declared.
Technical Investigation and Analysis
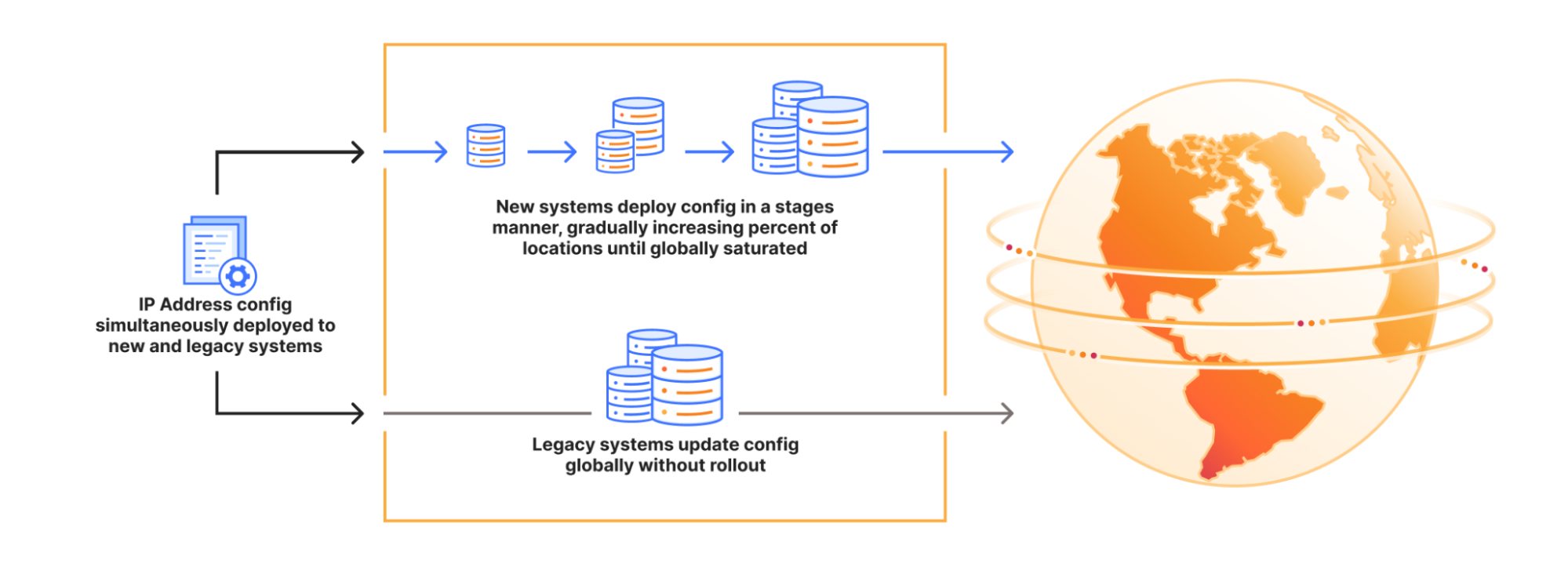
The way that Cloudflare manages service topologies has been refined over time and currently consist of a combination of a legacy and a strategic system that are synced. Cloudflare’s IP ranges are currently bound and configured across these systems that dictate where an IP range should be announced (in terms of datacenter location) on the edge network. The legacy approach of hard-coding explicit lists of data center locations and attaching them to particular prefixes has proved error-prone, since (for example) bringing a new data center online requires many different lists to be updated and synced consistently. This model also has a significant flaw in that updates to the configuration do not follow a progressive deployment methodology: Even though this release was peer-reviewed by multiple engineers, the change didn’t go through a series of canary deployments before reaching every Cloudflare data center. Our newer approach is to describe service topologies without needing to hard-code IP addresses, which better accommodate expansions to new locations and customer scenarios while also allowing for a staged deployment model, so changes can propagate slowly with health monitoring. During the migration between these approaches, we need to maintain both systems and synchronize data between them, which looks like this:
Initial alerts were triggered for the DNS Resolver at 22:01, indicating query, proxy, and data center failures. While investigating the alerts, we noted traffic toward the Resolver prefixes had drastically dropped and was no longer being received at our edge data centers. Internally, we use BGP to control route advertisements, and we found the Resolver routes from servers were completely missing.
Once our configuration error had been exposed and Cloudflare systems had withdrawn the routes from our routing table, all of the 1.1.1.1 routes should have disappeared entirely from the global Internet routing table. However, this isn’t what happened with the prefix 1.1.1.0/24. Instead, we got reports from Cloudflare Radar that Tata Communications India (AS4755) had started advertising 1.1.1.0/24: from the perspective of the routing system, this looked exactly like a prefix hijack. This was unexpected to see while we were troubleshooting the routing problem, but to be perfectly clear: this BGP hijack was not the cause of the outage. We are following up with Tata Communications.
Restoring the 1.1.1.1 Service
We reverted to the previous configuration at 22:20 UTC. Near instantly, we began readvertising the BGP prefixes which were previously withdrawn from the routers, including 1.1.1.0/24. This restored 1.1.1.1 traffic levels to roughly 77% of what they were prior to the incident. However, during the period since withdrawal, approximately 23% of the fleet of edge servers had been automatically reconfigured to remove required IP bindings as a result of the topology change. To add the configurations back, these servers needed to be reconfigured with our change management system which is not an instantaneous process by default for safety.
The process by which the IP bindings can be restored normally takes some time, as the network in individual locations is designed to be updated over a course of multiple hours. We implement a progressive rollout, rather than on all nodes at once to ensure we don’t introduce additional impact. However, given the severity of the incident, we accelerated the rollout of the fix after verifying the changes in testing locations to restore service as quickly and safely as possible. Normal traffic levels were observed at 22:54 UTC.
Remediation and follow-up steps
We take incidents like this seriously, and we recognise the impact that this incident had. Though this specific issue has been resolved, we have identified several steps we can take to mitigate the risk of a similar problem occurring in the future. We are implementing the following plan as a result of this incident:
Staging Addressing Deployments: Legacy components do not leverage a gradual, staged deployment methodology. Cloudflare will deprecate these systems which enables modern progressive and health mediated deployment processes to provide earlier indication in a staged manner and rollback accordingly.
Deprecating Legacy Systems: We are currently in an intermediate state in which current and legacy components need to be updated concurrently, so we will be migrating addressing systems away from risky deployment methodologies like this one. We will accelerate our deprecation of the legacy systems in order to provide higher standards for documentation and test coverage.
Conclusion
Cloudflare’s 1.1.1.1 DNS Resolver service fell victim to an internal configuration error.
We are sorry for the disruption this incident caused for our customers. We are actively making these improvements to ensure improved stability moving forward and to prevent this problem from happening again.
Source:: CloudFlare