Today, we’re launching the open beta of Pipelines, our streaming ingestion product. Pipelines allows you to ingest high volumes of structured, real-time data, and load it into our object storage service, R2. You don’t have to manage any of the underlying infrastructure, worry about scaling shards or metadata services, and you pay for the data processed (and not by the hour). Anyone on a Workers paid plan can start using it to ingest and batch data — at tens of thousands of requests per second (RPS) — directly into R2.
But this is just the tip of the iceberg: you often want to transform the data you’re ingesting, hydrate it on-the-fly from other sources, and write it to an open table format (such as Apache Iceberg), so that you can efficiently query that data once you’ve landed it in object storage.
The good news is that we’ve thought about that too, and we’re excited to announce that we’ve acquired Arroyo, a cloud-native, distributed stream processing engine, to make that happen.
With Arroyo and our just announced R2 Data Catalog, we’re getting increasingly serious about building a data platform that allows you to ingest data across the planet, store it at scale, and run compute over it.
To get started, you can dive into the Pipelines developer docs or just run this Wrangler command to create your first pipeline:
$ npx wrangler@latest pipelines create my-clickstream-pipeline --r2-bucket my-bucket
...
✅ Successfully created Pipeline my-clickstream-pipeline with ID 0e00c5ff09b34d018152af98d06f5a1xv… and then write your first record(s):
$ curl -d '[{"payload": [],"id":"abc-def"}]'
"https://0e00c5ff09b34d018152af98d06f5a1xvc.pipelines.cloudflarestorage.com/"However, the true power comes from the processing of data streams between ingestion and when they’re written to sinks like R2. Being able to write SQL that acts on windows of data as it’s being ingested, that can transform & aggregate it, and even extract insights from the data in real-time, turns out to be extremely powerful.
This is where Arroyo comes in, and we’re going to be bringing the best parts of Arroyo into Pipelines and deeply integrate it with Workers, R2, and the rest of our Developer Platform.
The Arroyo origin story
(By Micah Wylde, founder of Arroyo)
We started Arroyo in 2023 to bring real-time (stream) processing to everyone who works with data. Modern companies rely on data pipelines to power their applications and businesses — from user customization, recommendations, and anti-fraud, to the emerging world of AI agents.
But today, most of these pipelines operate in batch, running once per hour, day, or even month. After spending many years working on stream processing at companies like Lyft and Splunk, it was no mystery why: it was just too hard for developers and data scientists to build correct, performant, and reliable pipelines. Large tech companies hire streaming experts to build and operate these systems, but everyone else is stuck waiting for batches to arrive.
When we started, the dominant solution for streaming pipelines — and what we ran at Lyft and Splunk — was Apache Flink. Flink was the first system that successfully combined a fault-tolerant (able to recover consistently from failures), distributed (across multiple machines), stateful (and remember data about past events) dataflow with a graph-construction API. This combination of features meant that we could finally build powerful real-time data applications, with capabilities like windows, aggregations, and joins. But while Flink had the necessary power, in practice the API proved too hard and low-level for non-expert users, and the stateful nature of the resulting services required endless operations.
We realized we would need to build a new streaming engine — one with the power of Flink, but designed for product engineers and data scientists and to run on modern cloud infrastructure. We started with SQL as our API because it’s easy to use, widely known, and declarative. We built it in Rust for speed and operational simplicity (no JVM tuning required!). We constructed an object-storage-native state backend, simplifying the challenge of running stateful pipelines — which each are like a weird, specialized database. And then in the summer of 2023, we open-sourced it. Today, dozens of companies are running Arroyo pipelines with use cases including data ingestion, anti-fraud, IoT observability, and financial trading.
But we always knew that the engine was just one piece of the puzzle. To make streaming as easy as batch, users need to be able to develop and test query logic, backfill on historical data, and deploy serverlessly without having to worry about cluster sizing or ongoing operations. Democratizing streaming ultimately meant building a complete data platform. And when we started talking with Cloudflare, we realized they already had all of the pieces in place: R2 provides object storage for state and data at rest, Cloudflare Queues for data in transit, and Workers to safely and efficiently run user code. And Cloudflare, uniquely, allows us to push these systems all the way to the edge, enabling a new paradigm of local stream processing that will be key for a future of data sovereignty and AI.
That’s why we’re incredibly excited to join with the Cloudflare team to make this vision a reality.
Ingestion at scale
While transformations and a streaming SQL API are on the way for Pipelines, it already solves two critical parts of the data journey: globally distributed, high-throughput ingestion and efficient loading into object storage.
Creating a pipeline is as simple as running one command:
$ npx wrangler@latest pipelines create my-clickstream-pipeline --r2-bucket my-bucket
🌀 Creating pipeline named "my-clickstream-pipeline"
✅ Successfully created pipeline my-clickstream-pipeline with ID
0e00c5ff09b34d018152af98d06f5a1xvc
Id: 0e00c5ff09b34d018152af98d06f5a1xvc
Name: my-clickstream-pipeline
Sources:
HTTP:
Endpoint: https://0e00c5ff09b34d018152af98d06f5a1xvc.pipelines.cloudflare.com/
Authentication: off
Format: JSON
Worker:
Format: JSON
Destination:
Type: R2
Bucket: my-bucket
Format: newline-delimited JSON
Compression: GZIP
Batch hints:
Max bytes: 100 MB
Max duration: 300 seconds
Max records: 100,000
🎉 You can now send data to your pipeline!
Send data to your pipeline's HTTP endpoint:
curl "https://0e00c5ff09b34d018152af98d06f5a1xvc.pipelines.cloudflare.com/" -d '[{ ...JSON_DATA... }]'By default, a pipeline can ingest data from two sources – Workers and an HTTP endpoint – and load batched events into an R2 bucket. This gives you an out-of-the-box solution for streaming raw event data into object storage. If the defaults don’t work, you can configure pipelines during creation or anytime after. Options include: adding authentication to the HTTP endpoint, configuring CORS to allow browsers to make cross-origin requests, and specifying output file compression and batch settings.
We’ve built Pipelines for high ingestion volumes from day 1. Each pipeline can scale to ~100,000 records per second (and we’re just getting started here). Once records are written to a Pipeline, they are then durably stored, batched, and written out as files in an R2 bucket. Batching is critical here: if you’re going to act on and query that data, you don’t want your query engine querying millions (or tens of millions) of tiny files. It’s slow (per-file & request overheads), inefficient (more files to read), and costly (more operations). Instead, you want to find the right balance between batch size for your query engine and latency (not waiting too long for a batch): Pipelines allows you to configure this.
To further optimize queries, output files are partitioned by date and time, using the standard Hive partitioning scheme. This can optimize queries even further, because your query engine can just skip data that is irrelevant to the query you’re running. The output in your R2 bucket might look like this:
Hive-partioned files from Pipelines in an R2 bucket
Output files are stored as new-line delimited JSON (NDJSON) — which makes it easy to materialize a stream from these files (hint: in the future you’ll be able to use R2 as a pipeline source too). Finally, the file names are ULIDs – so they’re sorted by time by default.
First you shard, then you shard some more
What makes Pipelines so horizontally scalable and able to acknowledge writes quickly is how we built it: we use Durable Objects and the embedded, zero-latency SQLite storage within each Durable Object to immediately persist data as it’s written, before then processing it and writing it to R2.
For example: imagine you’re an e-commerce or SaaS site and need to ingest website usage data (known as clickstream data), and make it available to your data science team to query. The infrastructure which handles this workload has to be resilient to several failure scenarios. The ingestion service needs to maintain high availability in the face of bursts in traffic. Once ingested, the data needs to be buffered, to minimize downstream invocations and thus downstream cost. Finally, the buffered data needs to be delivered to a sink, with appropriate retry & failure handling if the sink is unavailable. Each step of this process needs to signal backpressure upstream when overloaded. It also needs to scale: up during major sales or events, and down during the quieter periods of the day.
Data engineers reading this post might be familiar with the status quo of using Kafka and the associated ecosystem to handle this. But if you’re an application engineer: you use Pipelines to build an ingestion service without learning about Kafka, Zookeeper, and Kafka streams.
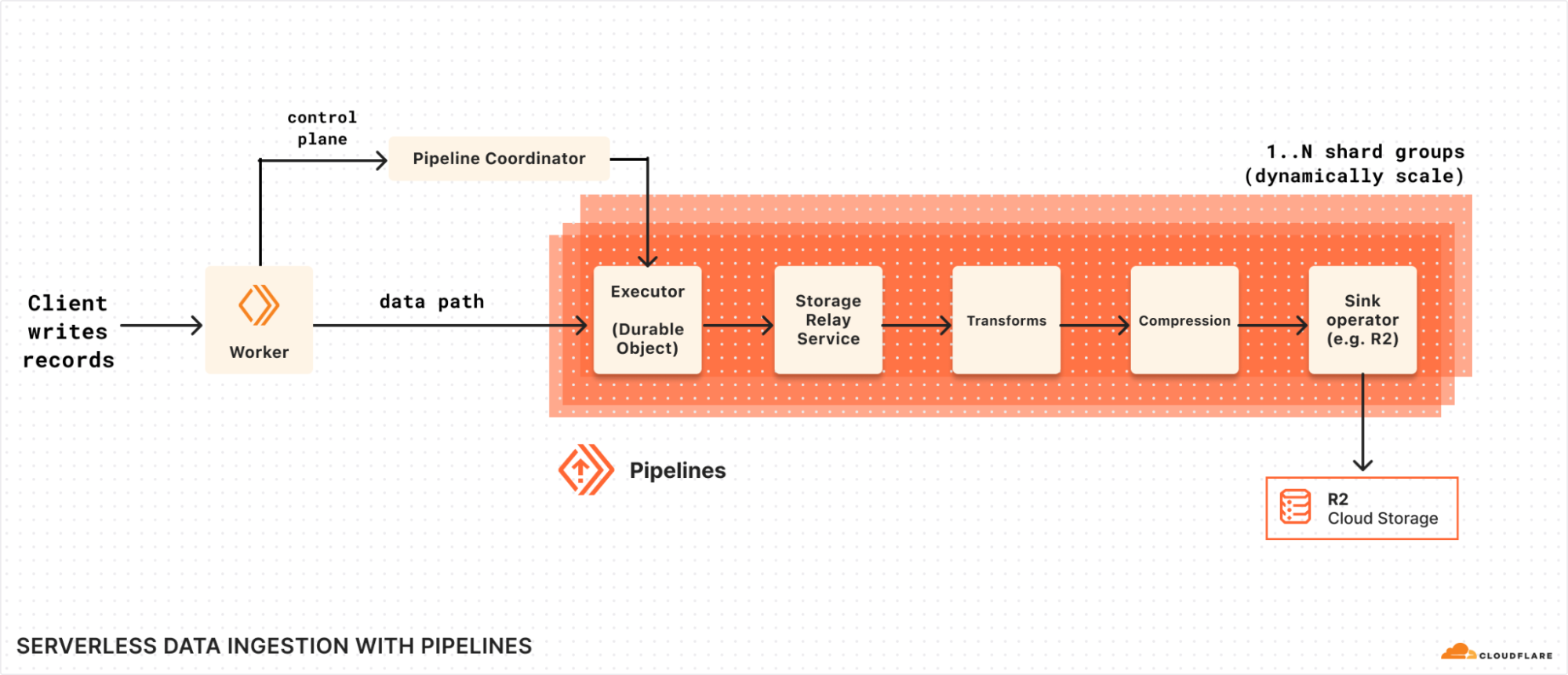
Pipelines horizontal sharding
The diagram above shows how Pipelines splits the control plane, which is responsible for accounting, tracking shards, and Pipelines lifecycle events, and the data path, which is a scalable group of Durable Objects shards.
When a record (or batch of records) is written to Pipelines:
The Pipelines Worker receives the records either through the fetch handler or worker binding.
Contacts the Coordinator, based upon the pipeline_id to get the execution plan: subsequent reads are cached to reduce pressure on the coordinator.
Executes the plan, which first shards to a set of Executors, while are primarily serving to scale read request handling
These then re-shard to another set of executors that are actually handling the writes, beginning with persisting to Durable Object storage, which will be replicated for durability and availability by the Storage Relay Service (SRS).
After SRS, we pass to any configured Transform Workers to customize the data.
The data is batched, written to output files, and compressed (if applicable).
The files are compressed, data is packaged into the final batches, and written to the configured R2 bucket.
Each step of this pipeline can signal backpressure upstream. We do this by leveraging ReadableStreams and responding with 429s when the total number of bytes awaiting write exceeds a threshold. Each ReadableStream is able to cross Durable Object boundaries by using JSRPC calls between Durable Objects. To improve performance, we use RPC stubs for connection reuse between Durable Objects. Each step is also able to retry operations, to handle any temporary unavailability in the Durable Objects or R2.
We also guarantee delivery even while updating an existing pipeline. When you update an existing pipeline, we create a new deployment, including all the shards and Durable Objects described above. Requests are gracefully re-routed to the new pipeline. The old pipeline continues to write data into R2, until all the Durable Object storage is drained. We spin down the old pipeline only after all the data has been written out. This way, you won’t lose data even while updating a pipeline.
You’ll notice there’s one interesting part in here — the Transform Workers — which we haven’t yet exposed. As we work to integrate Arroyo’s streaming engine with Pipelines, this will be a key part of how we hand over data for Arroyo to process.
So, what’s it cost?
During the first phase of the open beta, there will be no additional charges beyond standard R2 storage and operation costs incurred when loading and accessing data. And as always, egress directly from R2 buckets is free, so you can process and query your data from any cloud or region without worrying about data transfer costs adding up.
In the future, we plan to introduce pricing based on volume of data ingested into Pipelines and delivered from Pipelines:
Workers Paid ($5 / month)
Ingestion
First 50 GB per month included
$0.02 per additional GB
Delivery to R2
First 50 GB per month included
$0.02 per additional GB
We’re also planning to make Pipelines available on the Workers Free plan as the beta progresses.
We’ll be sharing more as we bring transformations and additional sinks to Pipelines. We’ll provide at least 30 days notice before we make any changes or start charging for usage, which we expect to do by September 15, 2025.
What’s next?
There’s a lot to build here, and we’re keen to build on a lot of the powerful components that Arroyo has built: integrating Workers as UDFs (User-Defined Functions), adding new sources like Kafka clients, and extending Pipelines with new sinks (beyond R2).
We’ll also be integrating Pipelines with our just-launched R2 Data Catalog: enabling you ingest streams of data directly into Iceberg tables and immediately query them, without needing to rely on other systems.
In the meantime, you can:
Get started and create your first Pipeline
Read the docs
Join the
#pipelines-betachannel on our Developer Discord
… or deploy the example project directly:
$ npm create cloudflare@latest -- pipelines-starter
--template="cloudflare/pipelines-starter"Source:: CloudFlare