Multiple Cloudflare services, including R2 object storage, experienced an elevated rate of errors for 1 hour and 7 minutes on March 21, 2025 (starting at 21:38 UTC and ending 22:45 UTC). During the incident window, 100% of write operations failed and approximately 35% of read operations to R2 failed globally. Although this incident started with R2, it impacted other Cloudflare services including Cache Reserve, Images, Log Delivery, Stream, and Vectorize.
While rotating credentials used by the R2 Gateway service (R2’s API frontend) to authenticate with our storage infrastructure, the R2 engineering team inadvertently deployed the new credentials (ID and key pair) to a development instance of the service instead of production. When the old credentials were deleted from our storage infrastructure (as part of the key rotation process), the production R2 Gateway service did not have access to the new credentials. This ultimately resulted in R2’s Gateway service being able to authenticate with our storage backend. There was no data loss or corruption that occurred as part of this incident: any in-flight uploads or mutations that returned successful HTTP status codes were persisted.
Once the root cause was identified and we realized we hadn’t deployed the new credentials to the production R2 Gateway service, we deployed the updated credentials and service availability was restored.
This incident happened because of human error and lasted longer than it should have because we didn’t have proper visibility into which credentials were being used by the Gateway Worker to authenticate with our storage infrastructure.
We’re deeply sorry for this incident and the disruption it may have caused to you or your users. We hold ourselves to a high standard and this is not acceptable. This blog post exactly explains the impact, what happened and when, and the steps we are taking to make sure this failure (and others like it) doesn’t happen again.
What was impacted?
The primary incident window occurred between 21:38 UTC and 22:45 UTC.
The following table details the specific impact to R2 and Cloudflare services that depend on, or interact with, R2:
Product/Service
Impact
R2
All customers using Cloudflare R2 would have experienced an elevated error rate during the primary incident window. Specifically:
* Object write operations had a 100% error rate.
* Object reads had an approximate error rate of 35% globally. Individual customer error rate varied during this window depending on access patterns. Customers accessing public assets through custom domains would have seen a reduced error rate as cached object reads were not impacted.
* Operations involving metadata only (e.g., head and list operations) were not impacted.
There was no data loss or risk to data integrity within R2’s storage subsystem. This incident was limited to a temporary authentication issue between R2’s API frontend and our storage infrastructure.
Billing
Billing uses R2 to store customer invoices. During the primary incident window, customers may have experienced errors when attempting to download/access past Cloudflare invoices.
Cache Reserve
Cache Reserve customers observed an increase in requests to their origin during the incident window as an increased percentage of reads to R2 failed. This resulted in an increase in requests to origins to fetch assets unavailable in Cache Reserve during this period.
User-facing requests for assets to sites with Cache Reserve did not observe failures as cache misses failed over to the origin.
Email Security
Email Security depends on R2 for customer-facing metrics. During the primary incident window, customer-facing metrics would not have updated.
Images
All (100% of) uploads failed during the primary incident window. Successful delivery of stored images dropped to approximately 25%.
Key Transparency Auditor
All (100% of) operations failed during the primary incident window due to dependence on R2 writes and/or reads. Once the incident was resolved, service returned to normal operation immediately.
Log Delivery
Log delivery (for Logpush and Logpull) was delayed during the primary incident window, resulting in significant delays (up to 70 minutes) in log processing. All logs were delivered after incident resolution.
Stream
All (100% of) uploads failed during the primary incident window. Successful Stream video segment delivery dropped to 94%. Viewers may have seen video stalls every minute or so, although actual impact would have varied.
Stream Live was down during the primary incident window as it depends on object writes.
Vectorize
Queries and operations against Vectorize indexes were impacted during the incident window. During the incident window, Vectorize customers would have seen an increased error rate for read queries to indexes and all (100% of) insert and upsert operation failed as Vectorize depends on R2 for persistent storage.
Incident timeline
All timestamps referenced are in Coordinated Universal Time (UTC).
Time
Event
Mar 21, 2025 – 19:49 UTC
The R2 engineering team started the credential rotation process. A new set of credentials (ID and key pair) for storage infrastructure was created. Old credentials were maintained to avoid downtime during credential change over.
Mar 21, 2025 – 20:19 UTC
Set updated production secret (wrangler secret put) and executed wrangler deploy command to deploy R2 Gateway service with updated credentials.
Note: We later discovered the –env parameter was inadvertently omitted for both Wrangler commands. This resulted in credentials being deployed to the Worker assigned to the default environment instead of the Worker assigned to the production environment.
Mar 21, 2025 – 20:20 UTC
The R2 Gateway service Worker assigned to the default environment is now using the updated storage infrastructure credentials.
Note: This was the wrong Worker, the production environment should have been explicitly set. But, at this point, we incorrectly believed the credentials were updated on the correct production Worker.
Mar 21, 2025 – 20:37 UTC
Old credentials were removed from our storage infrastructure to complete the credential rotation process.
Mar 21, 2025 – 21:38 UTC
– IMPACT BEGINS –
R2 availability metrics begin to show signs of service degradation. The impact to R2 availability metrics was gradual and not immediately obvious because there was a delay in the propagation of the previous credential deletion to storage infrastructure.
Mar 21, 2025 – 21:45 UTC
R2 global availability alerts are triggered (indicating 2% of error budget burn rate).
The R2 engineering team began looking at operational dashboards and logs to understand impact.
Mar 21, 2025 – 21:50 UTC
Internal incident declared.
Mar 21, 2025 – 21:51 UTC
R2 engineering team observes gradual but consistent decline in R2 availability metrics for both read and write operations. Operations involving metadata only (e.g., head and list operations) were not impacted.
Given gradual decline in availability metrics, R2 engineering team suspected a potential regression in propagation of new credentials in storage infrastructure.
Mar 21, 2025 – 22:05 UTC
Public incident status page published.
Mar 21, 2025 – 22:15 UTC
R2 engineering team created a new set of credentials (ID and key pair) for storage infrastructure in an attempt to force re-propagation.
Continued monitoring operational dashboards and logs.
Mar 21, 2025 – 22:20 UTC
R2 engineering team saw no improvement in availability metrics. Continued investigating other potential root causes.
Mar 21, 2025 – 22:30 UTC
R2 engineering team deployed a new set of credentials (ID and key pair) to R2 Gateway service Worker. This was to validate whether there was an issue with the credentials we had pushed to gateway service.
Environment parameter was still omitted in the deploy and secret put commands, so this deployment was still to the wrong non-production Worker.
Mar 21, 2025 – 22:36 UTC
– ROOT CAUSE IDENTIFIED –
The R2 engineering team discovered that credentials had been deployed to a non-production Worker by reviewing production Worker release history.
Mar 21, 2025 – 22:45 UTC
– IMPACT ENDS –
Deployed credentials to correct production Worker. R2 availability recovered.
Mar 21, 2025 – 22:54 UTC
The incident is considered resolved.
Analysis
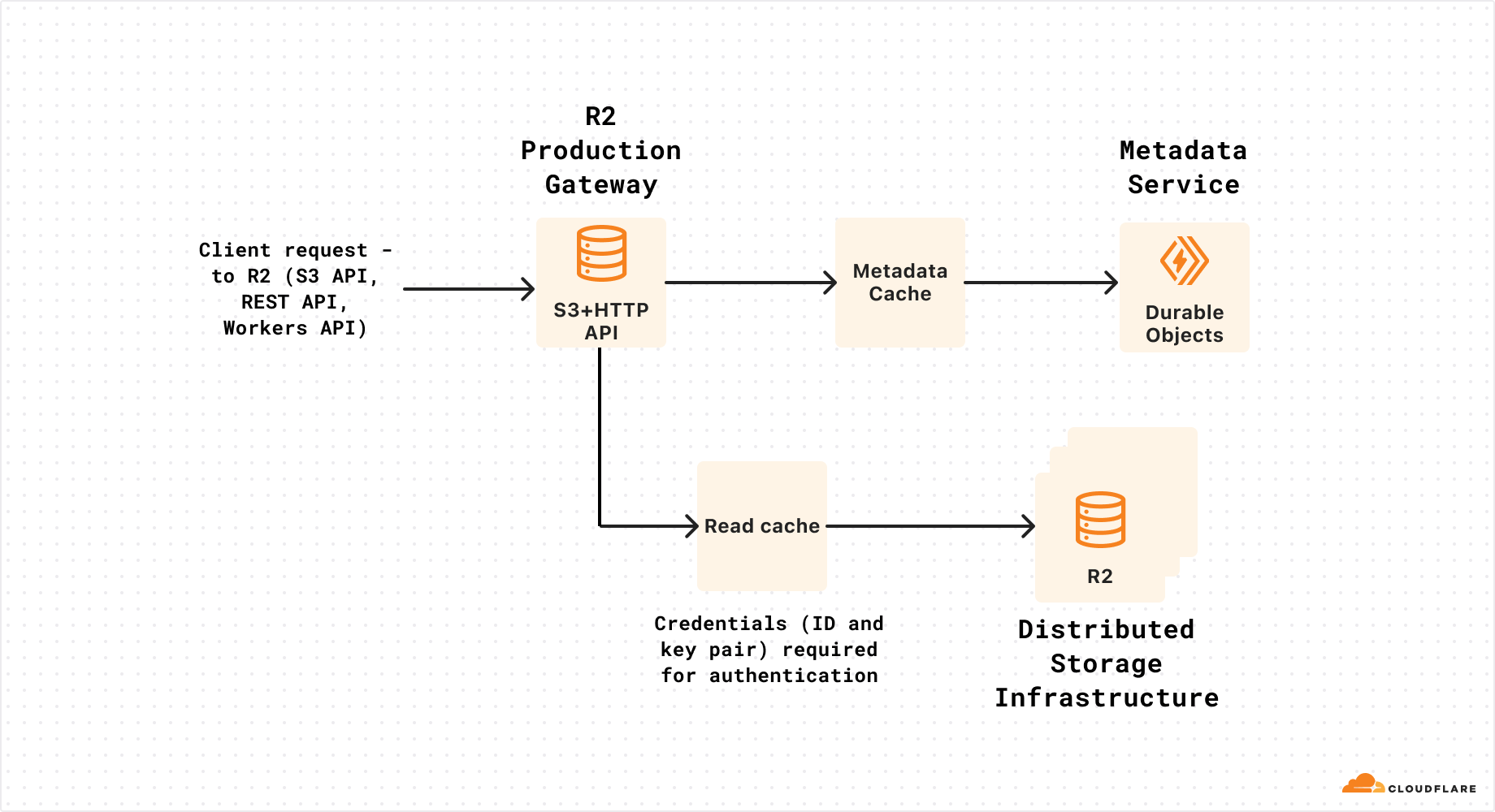
R2’s architecture is primarily composed of three parts: R2 production gateway Worker (serves requests from S3 API, REST API, Workers API), metadata service, and storage infrastructure (stores encrypted object data).
The R2 Gateway Worker uses credentials (ID and key pair) to securely authenticate with our distributed storage infrastructure. We rotate these credentials regularly as a best practice security precaution.
Our key rotation process involves the following high-level steps:
Create a new set of credentials (ID and key pair) for our storage infrastructure. At this point, the old credentials are maintained to avoid downtime during credential change over.
Set the new credential secret for the R2 production gateway Worker using the wrangler secret put command.
Set the new updated credential ID as an environment variable in the R2 production gateway Worker using the wrangler deploy command. At this point, new storage credentials start being used by the gateway Worker.
Remove previous credentials from our storage infrastructure to complete the credential rotation process.
Monitor operational dashboards and logs to validate change over.
The R2 engineering team uses Workers environments to separate production and development environments for the R2 Gateway Worker. Each environment defines a separate isolated Cloudflare Worker with separate environment variables and secrets.
Critically, both wrangler secret put and wrangler deploy commands default to the default environment if the –env command line parameter is not included. In this case, due to human error, we inadvertently omitted the –env parameter and deployed the new storage credentials to the wrong Worker (default environment instead of production). To correctly deploy storage credentials to the production R2 Gateway Worker, we need to specify --env production.
The action we took on step 4 above to remove the old credentials from our storage infrastructure caused authentication errors, as the R2 Gateway production Worker still had the old credentials. This is ultimately what resulted in degraded availability.
The decline in R2 availability metrics was gradual and not immediately obvious because there was a delay in the propagation of the previous credential deletion to storage infrastructure. This accounted for a delay in our initial discovery of the problem. Instead of relying on availability metrics after updating the old set of credentials, we should have explicitly validated which token was being used by the R2 Gateway service to authenticate with R2’s storage infrastructure.
Overall, the impact on read availability was significantly mitigated by our intermediate cache that sits in front of storage and continued to serve requests.
Resolution
Once we identified the root cause, we were able to resolve the incident quickly by deploying the new credentials to the production R2 Gateway Worker. This resulted in an immediate recovery of R2 availability.
Next steps
This incident happened because of human error and lasted longer than it should have because we didn’t have proper visibility into which credentials were being used by the R2 Gateway Worker to authenticate with our storage infrastructure.
We have taken immediate steps to prevent this failure (and others like it) from happening again:
Added logging tags that include the suffix of the credential ID the R2 Gateway Worker uses to authenticate with our storage infrastructure. With this change, we can explicitly confirm which credential is being used.
Related to the above step, our internal processes now require explicit confirmation that the suffix of the new token ID matches logs from our storage infrastructure before deleting the previous token.
Require that key rotation takes place through our hotfix release tooling instead of relying on manual wrangler command entry which introduces human error. Our hotfix release deploy tooling explicitly enforces the environment configuration and contains other safety checks.
While it’s been an implicit standard that this process involves at least two humans to validate the changes ahead as we progress, we’ve updated our relevant SOPs (standard operating procedures) to include this explicitly.
In Progress: Extend our existing closed loop health check system that monitors our endpoints to test new keys, automate reporting of their status through our alerting platform, and ensure global propagation prior to releasing the gateway Worker.
In Progress: To expedite triage on any future issues with our distributed storage endpoints, we are updating our observability platform to include views of upstream success rates that bypass caching to give clearer indication of issues serving requests for any reason.
The list above is not exhaustive: as we work through the above items, we will likely uncover other improvements to our systems, controls, and processes that we’ll be applying to improve R2’s resiliency, on top of our business-as-usual efforts. We are confident that this set of changes will prevent this failure, and related credential rotation failure modes, from occurring again. Again, we sincerely apologize for this incident and deeply regret any disruption it has caused you or your users.
Source:: CloudFlare