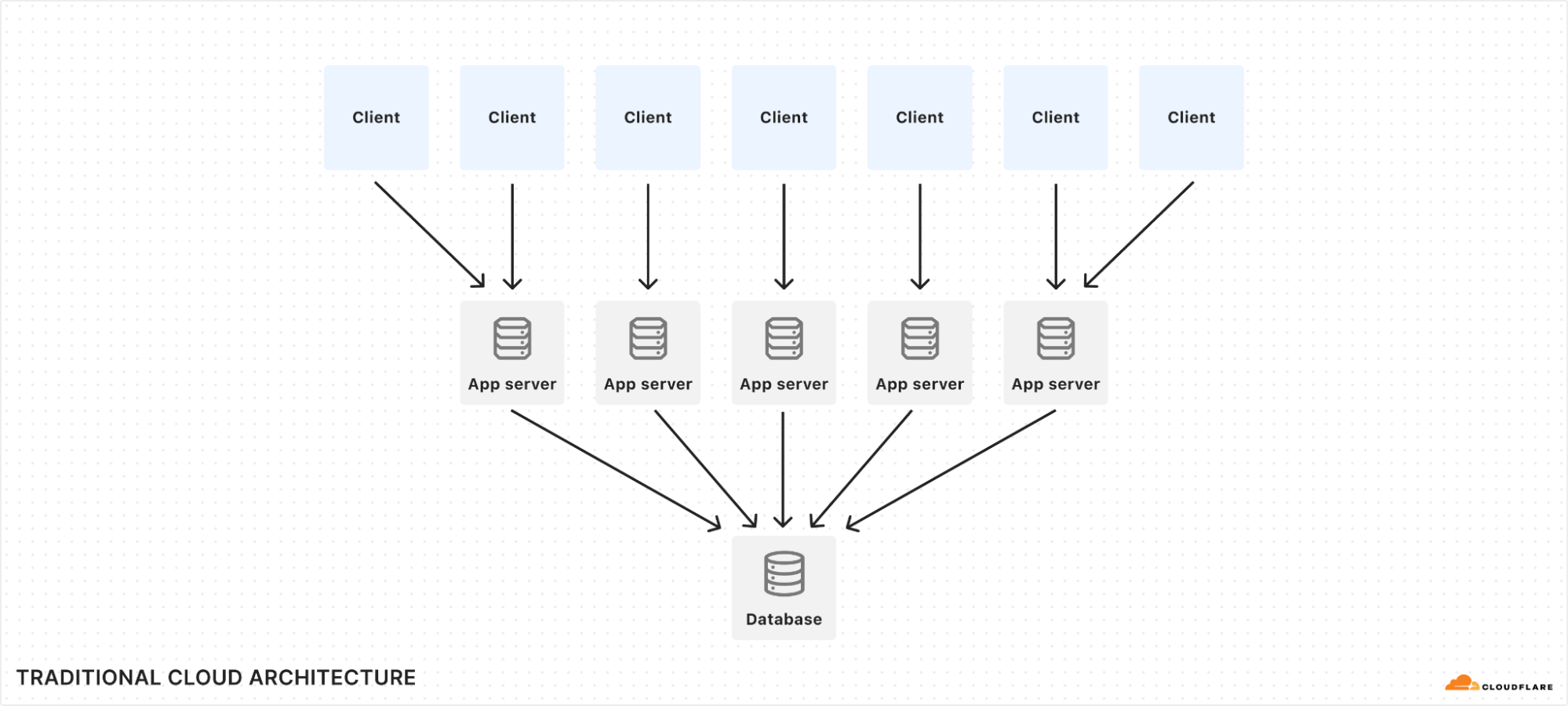
Traditional cloud storage is inherently slow, because it is normally accessed over a network and must carefully synchronize across many clients that could be accessing the same data. But what if we could instead put your application code deep into the storage layer, such that your code runs directly on the machine where the data is stored, and the database itself executes as a local library embedded inside your application?
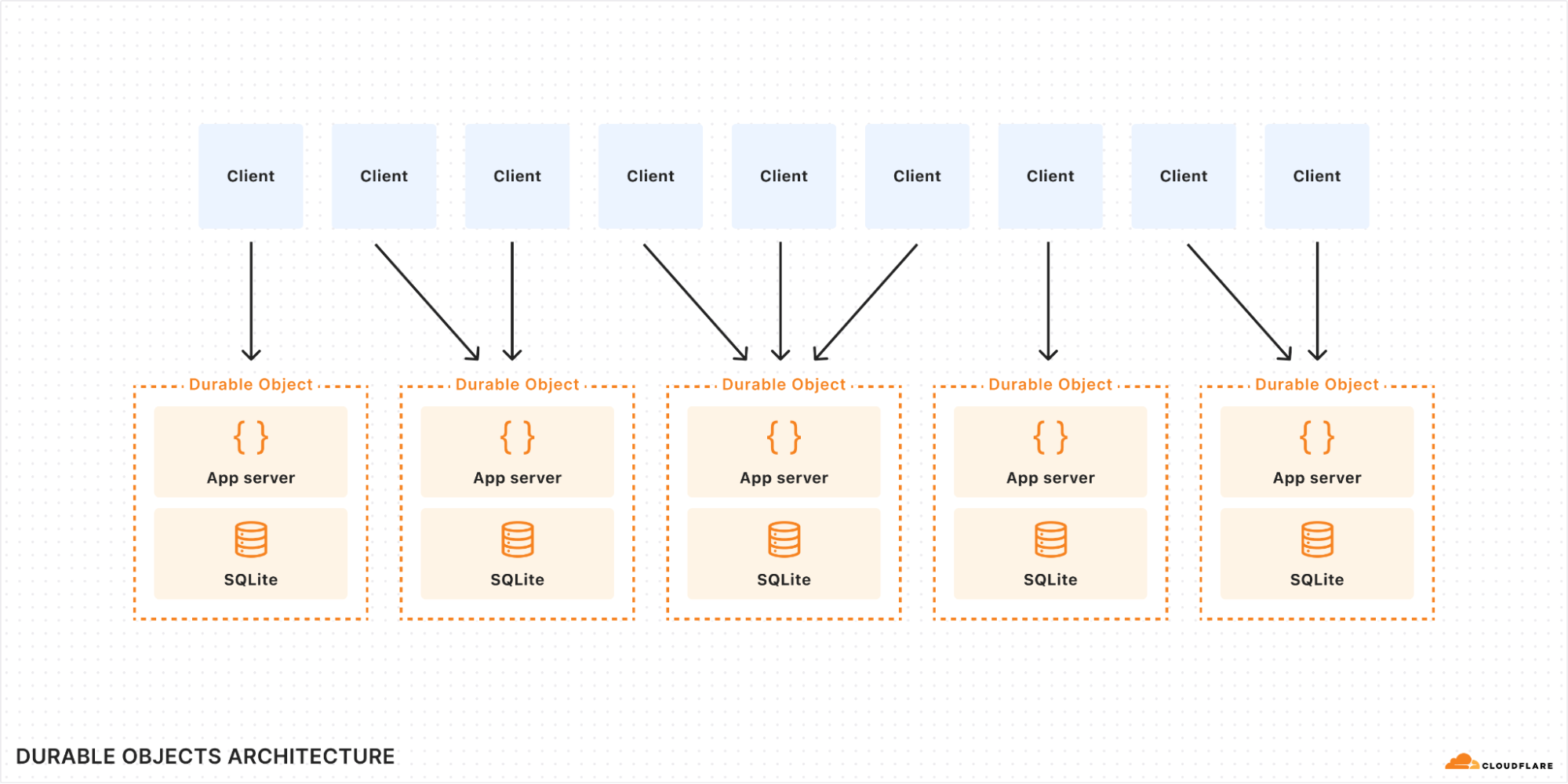
Durable Objects (DO) are a novel approach to cloud computing which accomplishes just that: Your application code runs exactly where the data is stored. Not just on the same machine: your storage lives in the same thread as the application, requiring not even a context switch to access. With proper use of caching, storage latency is essentially zero, while nevertheless being durable and consistent.
Until today, DOs only offered key/value oriented storage. But now, they support a full SQL query interface with tables and indexes, through the power of SQLite.
SQLite is the most-used SQL database implementation in the world, with billions of installations. It’s on practically every phone and desktop computer, and many embedded devices use it as well. It’s known to be blazingly fast and rock solid. But it’s been less common on the server. This is because traditional cloud architecture favors large distributed databases that live separately from application servers, while SQLite is designed to run as an embedded library. In this post, we’ll show you how Durable Objects turn this architecture on its head and unlock the full power of SQLite in the cloud.
Refresher: what are Durable Objects?
Durable Objects (DOs) are a part of the Cloudflare Workers serverless platform. A DO is essentially a small server that can be addressed by a unique name and can keep state both in-memory and on-disk. Workers running anywhere on Cloudflare’s network can send messages to a DO by its name, and all messages addressed to the same name — from anywhere in the world — will find their way to the same DO instance.
DOs are intended to be small and numerous. A single application can create billions of DOs distributed across our global network. Cloudflare automatically decides where a DO should live based on where it is accessed, automatically starts it up as needed when requests arrive, and shuts it down when idle. A DO has in-memory state while running and can also optionally store long-lived durable state. Since there is exactly one DO for each name, a DO can be used to coordinate between operations on the same logical object.
For example, imagine a real-time collaborative document editor application. Many users may be editing the same document at the same time. Each user’s changes must be broadcast to other users in real time, and conflicts must be resolved. An application built on DOs would typically create one DO for each document. The DO would receive edits from users, resolve conflicts, broadcast the changes back out to other users, and keep the document content updated in its local storage.
DOs are especially good at real-time collaboration, but are by no means limited to this use case. They are general-purpose servers that can implement any logic you desire to serve requests. Even more generally, DOs are a basic building block for distributed systems.
When using Durable Objects, it’s important to remember that they are intended to scale out, not up. A single object is inherently limited in throughput since it runs on a single thread of a single machine. To handle more traffic, you create more objects. This is easiest when different objects can handle different logical units of state (like different documents, different users, or different “shards” of a database), where each unit of state has low enough traffic to be handled by a single object. But sometimes, a lot of traffic needs to modify the same state: consider a vote counter with a million users all trying to cast votes at once. To handle such cases with Durable Objects, you would need to create a set of objects that each handle a subset of traffic and then replicate state to each other. Perhaps they use CRDTs in a gossip network, or perhaps they implement a fan-in/fan-out approach to a single primary object. Whatever approach you take, Durable Objects make it fast and easy to create more stateful nodes as needed.
Why is SQLite-in-DO so fast?
In traditional cloud architecture, stateless application servers run business logic and communicate over the network to a database. Even if the network is local, database requests still incur latency, typically measured in milliseconds.
When a Durable Object uses SQLite, SQLite is invoked as a library. This means the database code runs not just on the same machine as the DO, not just in the same process, but in the very same thread. Latency is effectively zero, because there is no communication barrier between the application and SQLite. A query can complete in microseconds.
Reads and writes are synchronous
The SQL query API in DOs does not require you to await results — they are returned synchronously:
// No awaits!
let cursor = sql.exec("SELECT name, email FROM users");
for (let user of cursor) {
console.log(user.name, user.email);
}
This may come as a surprise to some. Querying a database is I/O, right? I/O should always be asynchronous, right? Isn’t this a violation of the natural order of JavaScript?
It’s OK! The database content is probably cached in memory already, and SQLite is being called as a library in the same thread as the application, so the query often actually won’t spend any time at all waiting for I/O. Even if it does have to go to disk, it’s a local SSD. You might as well consider the local disk as just another layer in the memory cache hierarchy: L5 cache, if you will. In any case, it will respond quickly.
Meanwhile, synchronous queries provide some big benefits. First, the logistics of asynchronous event loops have a cost, so in the common case where the data is already in memory, a synchronous query will actually complete faster than an async one.
More importantly, though, synchronous queries help you avoid subtle bugs. Any time your application awaits a promise, it’s possible that some other code executes while you wait. The state of the world may have changed by the time your await completes. Maybe even other SQL queries were executed. This can lead to subtle bugs that are hard to reproduce because they require events to happen at just the wrong time. With a synchronous API, though, none of that can happen. Your code always executes in the order you wrote it, uninterrupted.
Fast writes with Output Gates
Database experts might have a deeper objection to synchronous queries: Yes, caching may mean we can perform reads and writes very fast. However, in the case of a write, just writing to cache isn’t good enough. Before we return success to our client, we must confirm that the write is actually durable, that is, it has actually made it onto disk or network storage such that it cannot be lost if the power suddenly goes out.
Normally, a database would confirm all writes before returning to the application. So if the query is successful, it is confirmed. But confirming writes can be slow, because it requires waiting for the underlying storage medium to respond. Normally, this is OK because the write is performed asynchronously, so the program can go on and work on other things while it waits for the write to finish. It looks kind of like this:
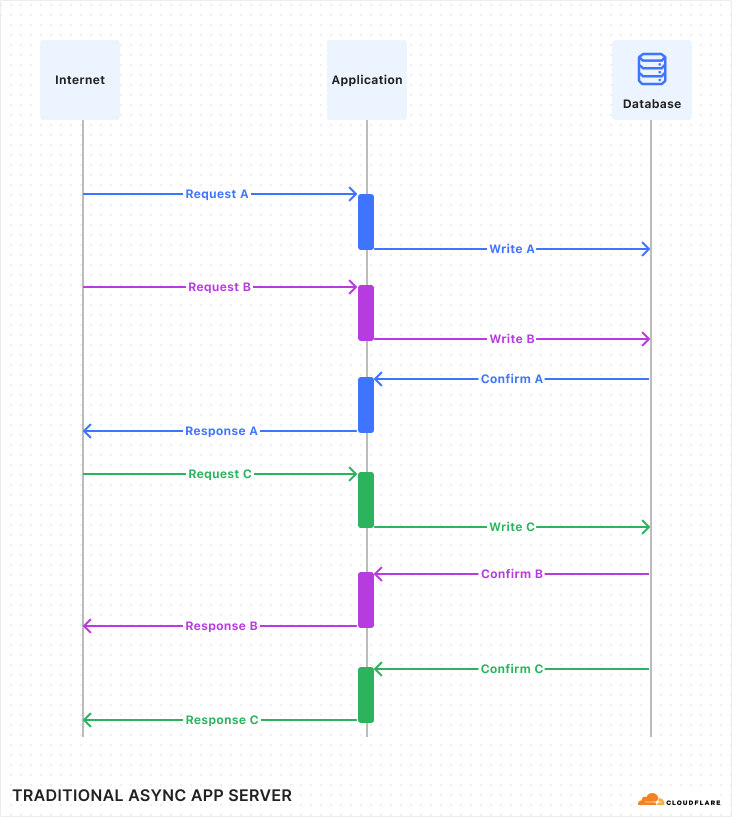
But I just told you that in Durable Objects, writes are synchronous. While a synchronous call is running, no other code in the program can run (because JavaScript does not have threads). This is convenient, as mentioned above, because it means you don’t need to worry that the state of the world may have changed while you were waiting. However, if write queries have to wait a while, and the whole program must pause and wait for them, then throughput will suffer.
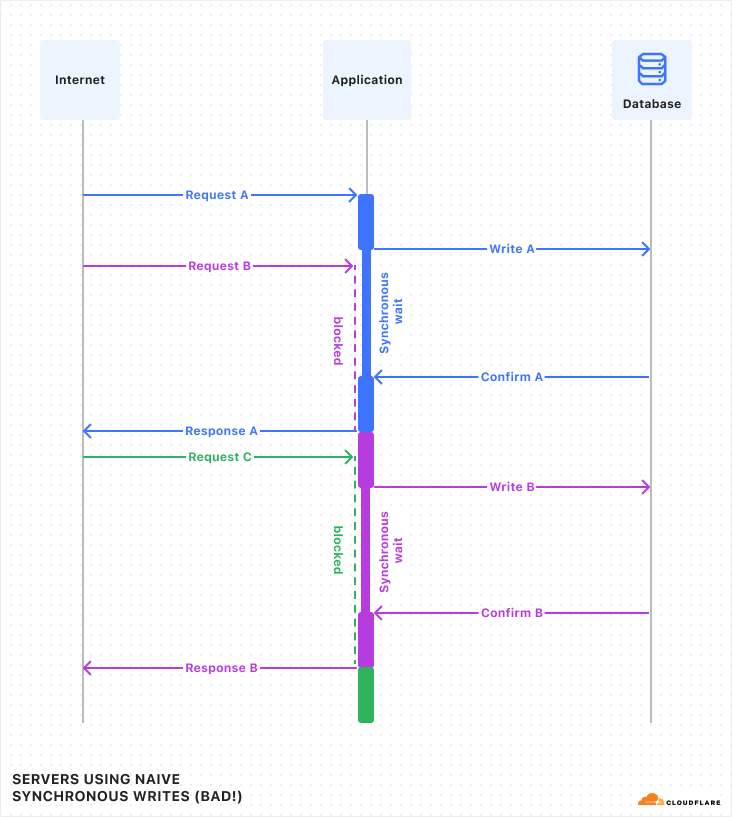
Luckily, in Durable Objects, writes do not have to wait, due to a little trick we call “Output Gates”.
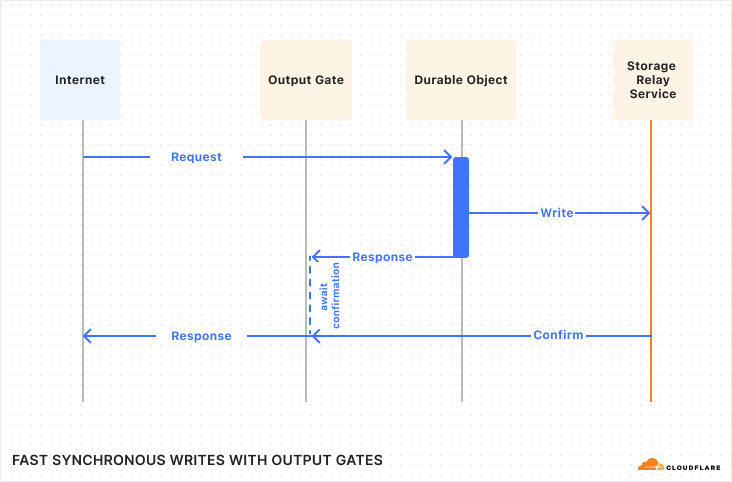
In DOs, when the application issues a write, it continues executing without waiting for confirmation. However, when the DO then responds to the client, the response is blocked by the “Output Gate”. This system holds the response until all storage writes relevant to the response have been confirmed, then sends the response on its way. In the rare case that the write fails, the response will be replaced with an error and the Durable Object itself will restart. So, even though the application constructed a “success” response, nobody can ever see that this happened, and thus nobody can be misled into believing that the data was stored.
Let’s see what this looks like with multiple requests:
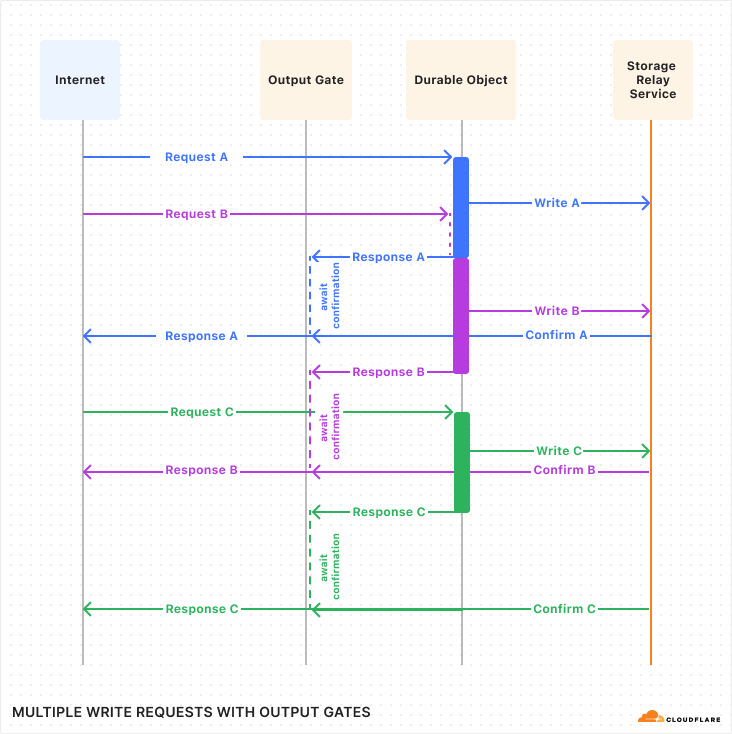
If you compare this against the first diagram above, you should notice a few things:
The timing of requests and confirmations are the same.
But, all responses were sent to the client sooner than in the first diagram. Latency was reduced! This is because the application is able to work on constructing the response in parallel with the storage layer confirming the write.
Request handling is no longer interleaved between the three requests. Instead, each request runs to completion before the next begins. The application does not need to worry, during the handling of one request, that its state might change unexpectedly due to a concurrent request.
With Output Gates, we get the ease-of-use of synchronous writes, while also getting lower latency and no loss of throughput.
N+1 selects? No problem.
Zero-latency queries aren’t just faster, they allow you to structure your code differently, often making it simpler. A classic example is the “N+1 selects” or “N+1 queries” problem. Let’s illustrate this problem with an example:
// N+1 SELECTs example
// Get the 100 most-recently-modified docs.
let docs = sql.exec(`
SELECT title, authorId FROM documents
ORDER BY lastModified DESC
LIMIT 100
`).toArray();
// For each returned document, get the author name from the users table.
for (let doc of docs) {
doc.authorName = sql.exec(
"SELECT name FROM users WHERE id = ?", doc.authorId).one().name;
}
If you are an experienced SQL user, you are probably cringing at this code, and for good reason: this code does 101 queries! If the application is talking to the database across a network with 5ms latency, this will take 505ms to run, which is slow enough for humans to notice.
// Do it all in one query with a join?
let docs = sql.exec(`
SELECT documents.title, users.name
FROM documents JOIN users ON documents.authorId = users.id
ORDER BY documents.lastModified DESC
LIMIT 100
`).toArray();
Here we’ve used SQL features to turn our 101 queries into one query. Great! Except, what does it mean? We used an inner join, which is not to be confused with a left, right, or cross join. What’s the difference? Honestly, I have no idea! I had to look up joins just to write this example and I’m already confused.
Well, good news: You don’t need to figure it out. Because when using SQLite as a library, the first example above works just fine. It’ll perform about the same as the second fancy version.
More generally, when using SQLite as a library, you don’t have to learn how to do fancy things in SQL syntax. Your logic can be in regular old application code in your programming language of choice, orchestrating the most basic SQL queries that are easy to learn. It’s fine. The creators of SQLite have made this point themselves.
Point-in-Time Recovery
While not necessarily related to speed, SQLite-backed Durable Objects offer another feature: any object can be reverted to the state it had at any point in time in the last 30 days. So if you accidentally execute a buggy query that corrupts all your data, don’t worry: you can recover. There’s no need to opt into this feature in advance; it’s on by default for all SQLite-backed DOs. See the docs for details.
How do I use it?
Let’s say we’re an airline, and we are implementing a way for users to choose their seats on a flight. We will create a new Durable Object for each flight. Within that DO, we will use a SQL table to track the assignments of seats to passengers. The code might look something like this:
import {DurableObject} from "cloudflare:workers";
// Manages seat assignment for a flight.
//
// This is an RPC interface. The methods can be called remotely by other Workers
// running anywhere in the world. All Workers that specify same object ID
// (probably based on the flight number and date) will reach the same instance of
// FlightSeating.
export class FlightSeating extends DurableObject {
sql = this.ctx.storage.sql;
// Application calls this when the flight is first created to set up the seat map.
initializeFlight(seatList) {
this.sql.exec(`
CREATE TABLE seats (
seatId TEXT PRIMARY KEY, -- e.g. "3B"
occupant TEXT -- null if available
)
`);
for (let seat of seatList) {
this.sql.exec(`INSERT INTO seats VALUES (?, null)`, seat);
}
}
// Get a list of available seats.
getAvailable() {
let results = [];
// Query returns a cursor.
let cursor = this.sql.exec(`SELECT seatId FROM seats WHERE occupant IS NULL`);
// Cursors are iterable.
for (let row of cursor) {
// Each row is an object with a property for each column.
results.push(row.seatId);
}
return results;
}
// Assign passenger to a seat.
assignSeat(seatId, occupant) {
// Check that seat isn't occupied.
let cursor = this.sql.exec(`SELECT occupant FROM seats WHERE seatId = ?`, seatId);
let result = [...cursor][0]; // Get the first result from the cursor.
if (!result) {
throw new Error("No such seat: " + seatId);
}
if (result.occupant !== null) {
throw new Error("Seat is occupied: " + seatId);
}
// If the occupant is already in a different seat, remove them.
this.sql.exec(`UPDATE seats SET occupant = null WHERE occupant = ?`, occupant);
// Assign the seat. Note: We don't have to worry that a concurrent request may
// have grabbed the seat between the two queries, because the code is synchronous
// (no `await`s) and the database is private to this Durable Object. Nothing else
// could have changed since we checked that the seat was available earlier!
this.sql.exec(`UPDATE seats SET occupant = ? WHERE seatId = ?`, occupant, seatId);
}
}
(With just a little more code, we could extend this example to allow clients to subscribe to seat changes with WebSockets, so that if multiple people are choosing their seats at the same time, they can see in real time as seats become unavailable. But, that’s outside the scope of this blog post, which is just about SQL storage.)
Then in wrangler.toml, define a migration setting up your DO class like usual, but instead of using new_classes, use new_sqlite_classes:
[[migrations]]
tag = "v1"
new_sqlite_classes = ["FlightSeating"]
SQLite-backed objects also support the existing key/value-based storage API: KV data is stored into a hidden table in the SQLite database. So, existing applications built on DOs will work when deployed using SQLite-backed objects.
However, because SQLite-backed objects are based on an all-new storage backend, it is currently not possible to switch an existing deployed DO class to use SQLite. You must ask for SQLite when initially deploying the new DO class; you cannot change it later. We plan to begin migrating existing DOs to the new storage backend in 2025.
Pricing
We’ve kept pricing for SQLite-in-DO similar to D1, Cloudflare’s serverless SQL database, by billing for SQL queries (based on rows) and SQL storage. SQL storage per object is limited to 1 GB during the beta period, and will be increased to 10 GB on general availability. DO requests and duration billing are unchanged and apply to all DOs regardless of storage backend.
During the initial beta, billing is not enabled for SQL queries (rows read and rows written) and SQL storage. SQLite-backed objects will incur charges for requests and duration. We plan to enable SQL billing in the first half of 2025 with advance notice.
Workers Paid
Rows read
First 25 billion / month included + $0.001 / million rows
Rows written
First 50 million / month included + $1.00 / million rows
SQL storage
5 GB-month + $0.20/ GB-month
For more on how to use SQLite-in-Durable Objects, check out the documentation.
What about D1?
Cloudflare Workers already offers another SQLite-backed database product: D1. In fact, D1 is itself built on SQLite-in-DO. So, what’s the difference? Why use one or the other?
In short, you should think of D1 as a more “managed” database product, while SQLite-in-DO is more of a lower-level “compute with storage” building block.
D1 fits into a more traditional cloud architecture, where stateless application servers talk to a separate database over the network. Those application servers are typically Workers, but could also be clients running outside of Cloudflare. D1 also comes with a pre-built HTTP API and managed observability features like query insights. With D1, where your application code and SQL database queries are not colocated like in SQLite-in-DO, Workers has Smart Placement to dynamically run your Worker in the best location to reduce total request latency, considering everything your Worker talks to, including D1. By the end of 2024, D1 will support automatic read replication for scalability and low-latency access around the world. If this managed model appeals to you, use D1.
Durable Objects require a bit more effort, but in return, give you more power. With DO, you have two pieces of code that run in different places: a front-end Worker which routes incoming requests from the Internet to the correct DO, and the DO itself, which runs on the same machine as the SQLite database. You may need to think carefully about which code to run where, and you may need to build some of your own tooling that exists out-of-the-box with D1. But because you are in full control, you can tailor the solution to your application’s needs and potentially achieve more.
Under the hood: Storage Relay Service
When Durable Objects first launched in 2020, it offered only a simple key/value-based interface for durable storage. Under the hood, these keys and values were stored in a well-known off-the-shelf database, with regional instances of this database deployed to locations in our data centers around the world. Durable Objects in each region would store their data to the regional database.
For SQLite-backed Durable Objects, we have completely replaced the persistence layer with a new system built from scratch, called Storage Relay Service, or SRS. SRS has already been powering D1 for over a year, and can now be used more directly by applications through Durable Objects.
SRS is based on a simple idea:
Local disk is fast and randomly-accessible, but expensive and prone to disk failures. Object storage (like R2) is cheap and durable, but much slower than local disk and not designed for database-like access patterns. Can we get the best of both worlds by using a local disk as a cache on top of object storage?
So, how does it work?
The mismatch in functionality between local disk and object storage
A SQLite database on disk tends to undergo many small changes in rapid succession. Any row of the database might be updated by any particular query, but the database is designed to avoid rewriting parts that didn’t change. Read queries may randomly access any part of the database. Assuming the right indexes exist to support the query, they should not require reading parts of the database that aren’t relevant to the results, and should complete in microseconds.
Object storage, on the other hand, is designed for an entirely different usage model: you upload an entire “object” (blob of bytes) at a time, and download an entire blob at a time. Each blob has a different name. For maximum efficiency, blobs should be fairly large, from hundreds of kilobytes to gigabytes in size. Latency is relatively high, measured in tens or hundreds of milliseconds.
So how do we back up our SQLite database to object storage? An obviously naive strategy would be to simply make a copy of the database files from time to time and upload it as a new “object”. But, uploading the database on every change — and making the application wait for the upload to complete — would obviously be way too slow. We could choose to upload the database only occasionally — say, every 10 minutes — but this means in the case of a disk failure, we could lose up to 10 minutes of changes. Data loss is, uh, bad! And even then, for most databases, it’s likely that most of the data doesn’t change every 10 minutes, so we’d be uploading the same data over and over again.
Trick one: Upload a log of changes
Instead of uploading the entire database, SRS records a log of changes, and uploads those.
Conveniently, SQLite itself already has a concept of a change log: the Write-Ahead Log, or WAL. SRS always configures SQLite to use WAL mode. In this mode, any changes made to the database are first written to a separate log file. From time to time, the database is “checkpointed”, merging the changes back into the main database file. The WAL format is well-documented and easy to understand: it’s just a sequence of “frames”, where each frame is an instruction to write some bytes to a particular offset in the database file.
SRS monitors changes to the WAL file (by hooking SQLite’s VFS to intercept file writes) to discover the changes being made to the database, and uploads those to object storage.
Unfortunately, SRS cannot simply upload every single change as a separate “object”, as this would result in too many objects, each of which would be inefficiently small. Instead, SRS batches changes over a period of up to 10 seconds, or up to 16 MB worth, whichever happens first, then uploads the whole batch as a single object.
When reconstructing a database from object storage, we must download the series of change batches and replay them in order. Of course, if the database has undergone many changes over a long period of time, this can get expensive. In order to limit how far back it needs to look, SRS also occasionally uploads a snapshot of the entire content of the database. SRS will decide to upload a snapshot any time that the total size of logs since the last snapshot exceeds the size of the database itself. This heuristic implies that the total amount of data that SRS must download to reconstruct a database is limited to no more than twice the size of the database. Since we can delete data from object storage that is older than the latest snapshot, this also means that our total stored data is capped to 2x the database size.
Credit where credit is due: This idea — uploading WAL batches and snapshots to object storage — was inspired by Litestream, although our implementation is different.
Trick two: Relay through other servers in our global network
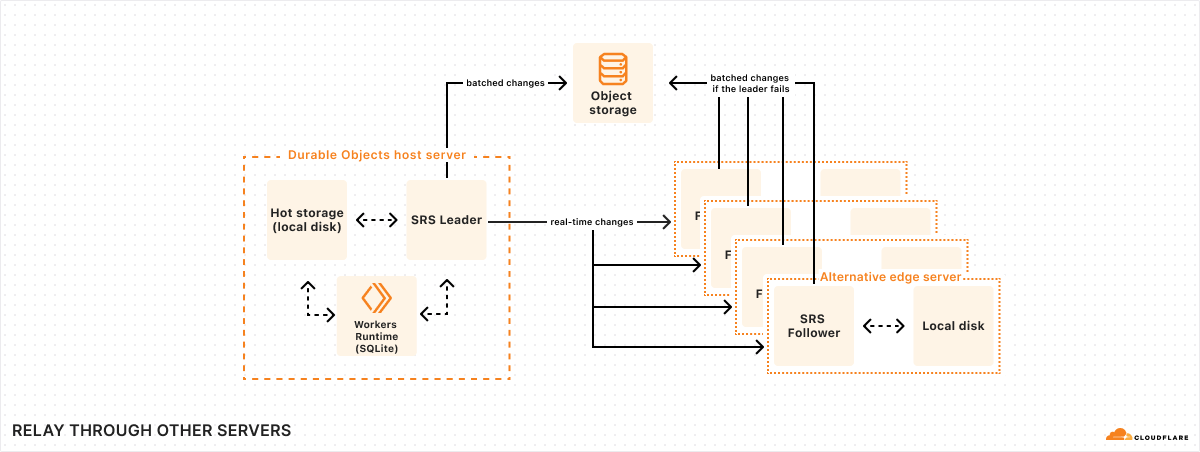
Batches are only uploaded to object storage every 10 seconds. But obviously, we cannot make the application wait for 10 whole seconds just to confirm a write. So what happens if the application writes some data, returns a success message to the user, and then the machine fails 9 seconds later, losing the data?
To solve this problem, we take advantage of our global network. Every time SQLite commits a transaction, SRS will immediately forward the change log to five “follower” machines across our network. Once at least three of these followers respond that they have received the change, SRS informs the application that the write is confirmed. (As discussed earlier, the write confirmation opens the Durable Object’s “output gate”, unblocking network communications to the rest of the world.)
When a follower receives a change, it temporarily stores it in a buffer on local disk, and then awaits further instructions. Later on, once SRS has successfully uploaded the change to object storage as part of a batch, it informs each follower that the change has been persisted. At that point, the follower can simply delete the change from its buffer.
However, if the follower never receives the persisted notification, then, after some timeout, the follower itself will upload the change to object storage. Thus, if the machine running the database suddenly fails, as long as at least one follower is still running, it will ensure that all confirmed writes are safely persisted.
Each of a database’s five followers is located in a different physical data center. Cloudflare’s network consists of hundreds of data centers around the world, which means it is always easy for us to find four other data centers nearby any Durable Object (in addition to the one it is running in). In order for a confirmed write to be lost, then, at least four different machines in at least three different physical buildings would have to fail simultaneously (three of the five followers, plus the Durable Object’s host machine). Of course, anything can happen, but this is exceedingly unlikely.
Followers also come in handy when a Durable Object’s host machine is unresponsive. We may not know for sure if the machine has died completely, or if it is still running and responding to some clients but not others. We cannot start up a new instance of the DO until we know for sure that the previous instance is dead – or, at least, that it can no longer confirm writes, since the old and new instances could then confirm contradictory writes. To deal with this situation, if we can’t reach the DO’s host, we can instead try to contact its followers. If we can contact at least three of the five followers, and tell them to stop confirming writes for the unreachable DO instance, then we know that instance is unable to confirm any more writes going forward. We can then safely start up a new instance to replace the unreachable one.
Bonus feature: Point-in-Time Recovery
I mentioned earlier that SQLite-backed Durable Objects can be asked to revert their state to any time in the last 30 days. How does this work?
This was actually an accidental feature that fell out of SRS’s design. Since SRS stores a complete log of changes made to the database, we can restore to any point in time by replaying the change log from the last snapshot. The only thing we have to do is make sure we don’t delete those logs too soon.
Normally, whenever a snapshot is uploaded, all previous logs and snapshots can then be deleted. But instead of deleting them immediately, SRS merely marks them for deletion 30 days later. In the meantime, if a point-in-time recovery is requested, the data is still there to work from.
For a database with a high volume of writes, this may mean we store a lot of data for a lot longer than needed. As it turns out, though, once data has been written at all, keeping it around for an extra month is pretty cheap — typically cheaper, even, than writing it in the first place. It’s a small price to pay for always-on disaster recovery.
Get started with SQLite-in-DO
SQLite-backed DOs are available in beta starting today. You can start building with SQLite-in-DO by visiting developer documentation and provide beta feedback via the #durable-objects channel on our Developer Discord.
Do distributed systems like SRS excite you? Would you like to be part of building them at Cloudflare? We’re hiring!
Source:: CloudFlare