Infrastructure planning for a network serving more than 81 million requests at peak and which is globally distributed across more than 330 cities in 120+ countries is complex. The capacity planning team at Cloudflare ensures there is enough capacity in place all over the world so that our customers have one less thing to worry about – our infrastructure, which should just work. Through our processes, the team puts careful consideration into “what-ifs”. What if something unexpected happens and one of our data centers fails? What if one of our largest customers triples, or quadruples their request count? Across a gamut of scenarios like these, the team works to understand where traffic will be served from and how the Cloudflare customer experience may change.
This blog post gives a look behind the curtain of how these scenarios are modeled at Cloudflare, and why it’s so critical for our customers.
Scenario planning and our customers
Cloudflare customers rely on the data centers that Cloudflare has deployed all over the world, placing us within 50 ms of approximately 95% of the Internet-connected population globally. But round-trip time to our end users means little if those data centers don’t have the capacity to serve requests. Cloudflare has invested deeply into systems that are working around the clock to optimize the requests flowing through our network because we know that failures happen all the time: the Internet can be a volatile place. See our blog post from August 2024 on how we handle this volatility in real time on our backbone, and our blog post from late 2023 about how another system, Traffic Manager, actively works in and between data centers, moving traffic to optimize the customer experience around constraints in our data centers. Both of these systems do a fantastic job in real time, but there is still a gap — what about over the long term?
Most of the volatility that the above systems are built to manage is resolved within shorter time scales than which we build plans for. (There are, of course, some failures that are exceptions.) Most scenarios we model still need to take into account the state of our data centers in the future, as well as what actions systems like Traffic Manager will take during those periods. But before getting into those constraints, it’s important to note how capacity planning measures things: in units of CPU Time, defined as the time that each request takes in the CPU. This is done for the same reasons that Traffic Manager uses CPU Time, in that it enables the team to 1) use a common unit across different types of customer workloads and 2) speak a common language with other teams and systems (like Traffic Manager). The same reasoning the Traffic Manager team cited in their own blog post is equally applicable for capacity planning:
…using requests per second as a metric isn’t accurate enough when actually moving traffic. The reason for this is that different customers have different resource costs to our service; a website served mainly from cache with the WAF deactivated is much cheaper CPU wise than a site with all WAF rules enabled and caching disabled. So we record the time that each request takes in the CPU. We can then aggregate the CPU time across each plan to find the CPU time usage per plan. We record the CPU time in ms, and take a per second value, resulting in a unit of milliseconds per second.
This is important for customers for the same reason that the Traffic Manager team cited in their blog post as well: we can correlate CPU time to performance, specifically latency.
Now that we know our unit of measurement is CPU time, we need to set up our models with the new constraints associated with the change that we’re trying to model. Specifically, there are a subset of constraints that we are particularly interested in because we know that they have the ability to impact our customers by impacting the availability of CPU in a data center. These are split into two main inputs in our models: Supply and Demand. We can think of these as “what-if” questions, such as the following examples:
Demand what-ifs
What if a new customer onboards to Cloudflare with a significant volume of requests and/or bytes?
What if an existing customer increased its volume of requests and/or bytes by some multiplier (i.e. 2x, 3x, nx), at peak, for the next three months?
What if the growth rate, in number of requests and bytes, of all of our data centers worldwide increased from X to Y two months from now, indefinitely?
What if the growth rate, in number of requests and bytes, of data center facility A increased from X to Y one month from now?
What if traffic egressing from Cloudflare to a last-mile network shifted from one location (such as Boston) to another (such as New York City) next week?
Supply what-ifs
What if data center facility A lost some or all of its available servers two months from now?
What if we added X servers to data center facility A today?
What if some or all of our connectivity to other ASNs (12,500 Networks/nearly 300 Tbps) failed now?
Output
For any one of these, or a combination of them, in our model’s output, we aim to provide answers to the following:
What will the overall capacity picture look like over time?
Where will the traffic go?
How will this impact our costs?
Will we need to deploy additional servers to handle the increased load?
Given these sets of questions and outputs, manually creating a model to answer each of these questions, or a combination of these questions, quickly becomes an operational burden for any team. This is what led us to launch “Scenario Planner”.
Scenario Planner
In August 2024, the infrastructure team finished building “Scenario Planner”, a system that enables anyone at Cloudflare to simulate “what-ifs”. This provides our team the opportunity to quickly model hypothetical changes to our demand and supply metrics across time and in any of Cloudflare’s data centers. The core functionality of the system has to do with the same questions we need to answer in the manual models discussed above. After we enter the changes we want to model, Scenario Planner converts from units that are commonly associated with each question to our common unit of measurement: CPU Time. These inputs are then used to model the updated capacity across all of our data centers, including how demand may be distributed in cases where capacity constraints may start impacting performance in a particular location. As we know, if that happens then it triggers Traffic Manager to serve some portion of those requests from a nearby location to minimize impact on customers and user experience.
Updated demand questions with inputs
Question: What if a new customer onboards to Cloudflare with a significant volume of requests?
Input: The new customer’s expected volume, geographic distribution, and timeframe of requests, converted to a count of virtual CPUs
Calculation(s): Scenario Planner converts from server count to CPU Time, and distributes the new demand across the regions selected according to the aggregate distribution of all customer usage.
Question: What if an existing customer increased its volume of requests and/or bytes by some multiplier (i.e. 2x, 3x, nx), at peak, for the next three months?
Input: Select the customer name, the multiplier, and the timeframe
Calculation(s): Scenario Planner already has how the selected customer’s traffic is distributed across all data centers globally, so this involves simply multiplying that value by the multiplier selected by the user
Question: What if the growth rate, in number of requests and bytes, of all of our data centers worldwide increased from X to Y two months from now, indefinitely?
Input: Enter a new global growth rate and timeframe
Calculation(s): Scenario Planner distributes this growth across all data centers globally according to their current growth rate. In other words, the global growth is an aggregation of all individual data center’s growth rates, and to apply a new “Global” growth rate, the system scales up each of the individual data center’s growth rates commensurate with the current distribution of growth.
Question: What if the growth rate, in number of requests and bytes, of data center facility A increased from X to Y one month from now?
Input: Select a data center facility, enter a new growth rate for that data center and the timeframe to apply that change across.
Calculation(s): Scenario Planner passes the new growth rate for the data center to the backend simulator, across the timeline specified by the user
Updated supply questions with inputs
Question: What if data center facility A lost some or all of its available servers two months from now?
Input: Select a data center, and enter the number of servers to remove, or select to remove all servers in that location, as well as the timeframe for when those servers will not be available
Calculation(s): Scenario Planner converts the server count entered (including all servers in a given location) to CPU Time before passing to the backend
Question: What if we added X servers to data center facility A today?
Input: Select a data center, and enter the number of servers to add, as well as the timeline for when those servers will first go live
Calculation(s): Scenario Planner converts the server count entered (including all servers in a given location) to CPU Time before passing to the backend
We made it simple for internal users to understand the impact of those changes because Scenario Planner outputs the same views that everyone who has seen our heatmaps and visual representations of our capacity status is familiar with. There are two main outputs the system provides: a heatmap and an “Expected Failovers” view. Below, we explore what these are, with some examples.
Heatmap
Capacity planning evaluates its success on its ability to predict demand: we generally produce a weekly, monthly, and quarterly forecast of 12 months to three years worth of demand, and nearly all of our infrastructure decisions are based on the output of this forecast. Scenario Planner provides a view of the results of those forecasts that are implemented via a heatmap: it shows our current state, as well as future planned server additions that are scheduled based on the forecast.
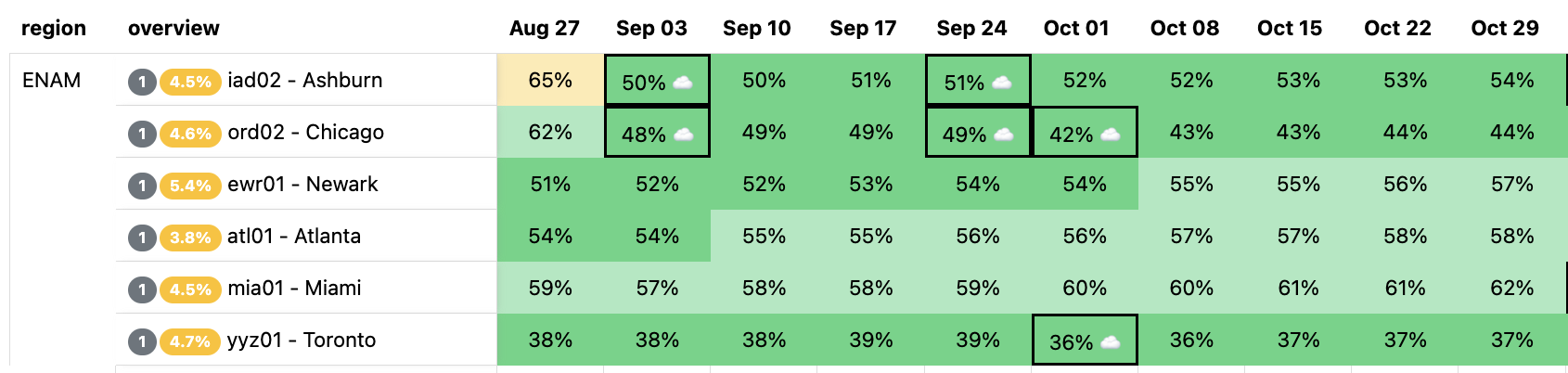
Here is an example of our heatmap, showing some of our largest data centers in Eastern North America (ENAM). Ashburn is showing as yellow, briefly, because our capacity planning threshold for adding more server capacity to our data centers is 65% utilization (based on CPU time supply and demand): this gives the Cloudflare teams time to procure additional servers, ship them, install them, and bring them live before customers will be impacted and systems like Traffic Manager would begin triggering. The little cloud icons indicate planned upgrades of varying sizes to get ahead of forecasted future demand well ahead of time to avoid customer performance degradation.
The question Scenario Planner answers then is how this view changes with a hypothetical scenario: What if our Ashburn, Miami, and Atlanta facilities shut down completely? This is unlikely to happen, but we would expect to see enormous impact on the remaining largest facilities in ENAM. We’ll simulate all three of these failing at the same time, taking them offline indefinitely:
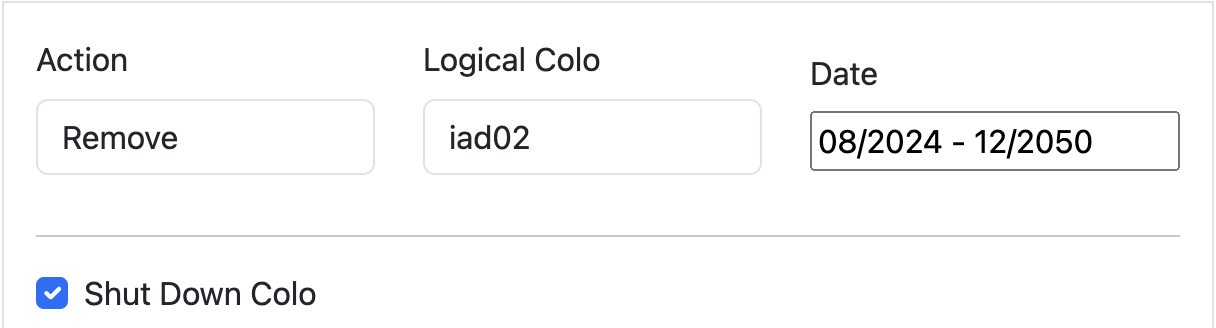
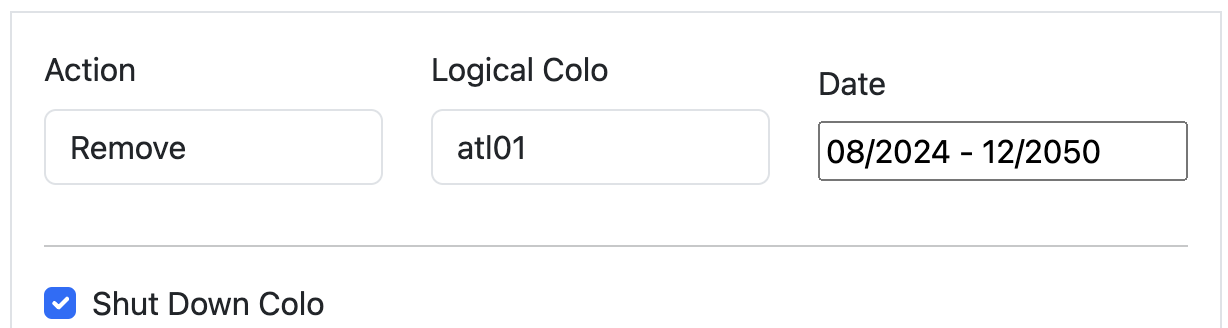
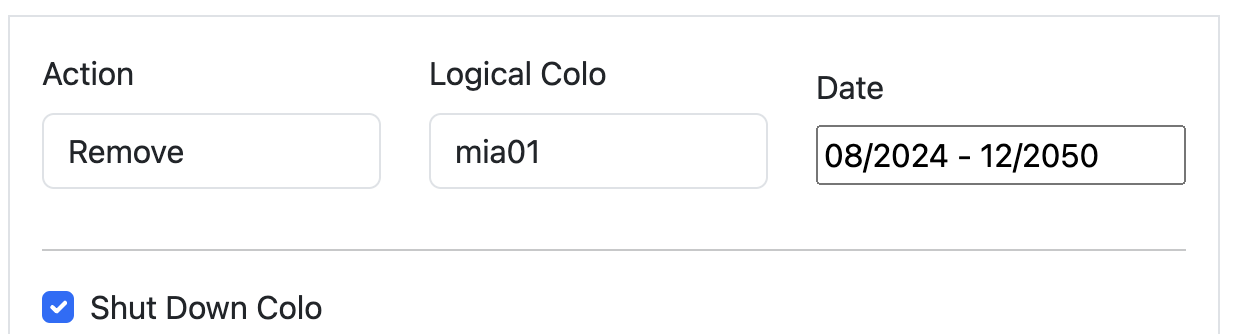
This results in a view of our capacity through the rest of the year in the remaining large data centers in ENAM — capacity is clearly constrained: Traffic Manager will be working hard to mitigate any impact to customer performance if this were to happen. Our capacity view in the heatmap is capped at 75%: this is because Traffic Manager typically engages around this level of CPU utilization. Beyond 75%, Cloudflare customers may begin to experience increased latency, though this is dependent on the product and workload, and is in reality much more dynamic.

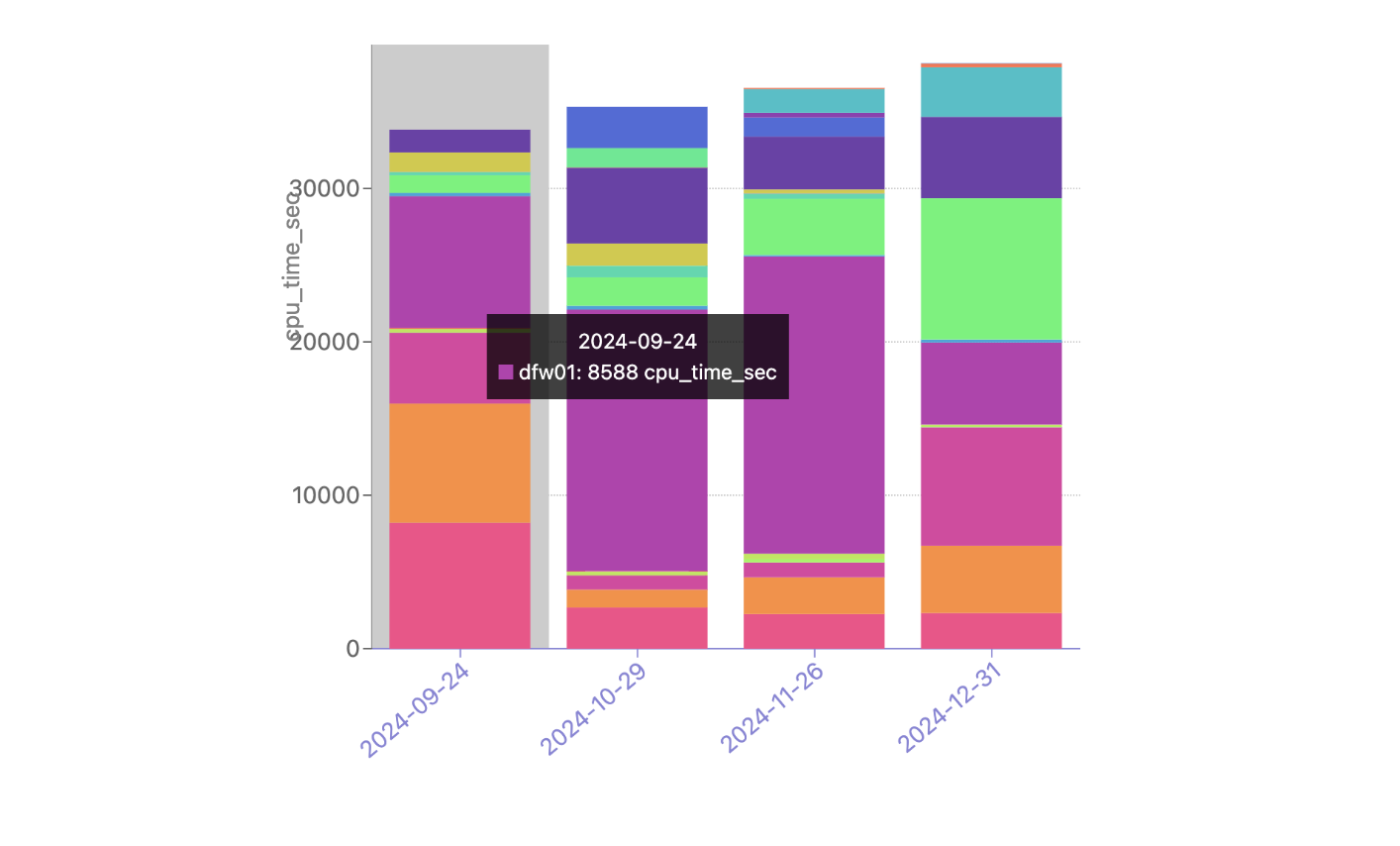
This outcome in the heatmap is not unexpected. But now we typically get a follow-up question: clearly this traffic won’t fit in just Newark, Chicago, and Toronto, so where do all these requests get served from? Enter the failover simulator: Capacity Planning has been simulating how Traffic Manager may work in the long term for quite a while, and for Scenario Planner, it was simple to extend this functionality to answer exactly this question.
There is currently no traffic being moved by Traffic Manager from these data centers, but our simulation shows a significant portion of the Atlanta CPU time being served from our DFW/Dallas data center as well as Newark (bottom pink), and Chicago (orange) through the rest of the year, during this hypothetical failure. With Scenario Planner, Capacity Planning can take this information and simulate multiple failures all over the world to understand the impact to customers, taking action to ensure that customers trusting Cloudflare with their web properties can expect high performance even in instances of major data center failures.
Planning with uncertainty
Capacity planning a large global network comes with plenty of uncertainties. Scenario Planner is one example of the work the Capacity Planning team is doing to ensure that the millions of web properties our customers entrust to Cloudflare can expect consistent, top tier performance all over the world.
The Capacity Planning team is hiring — check out the Cloudflare careers page and search for open roles on the Capacity Planning team.
Source:: CloudFlare