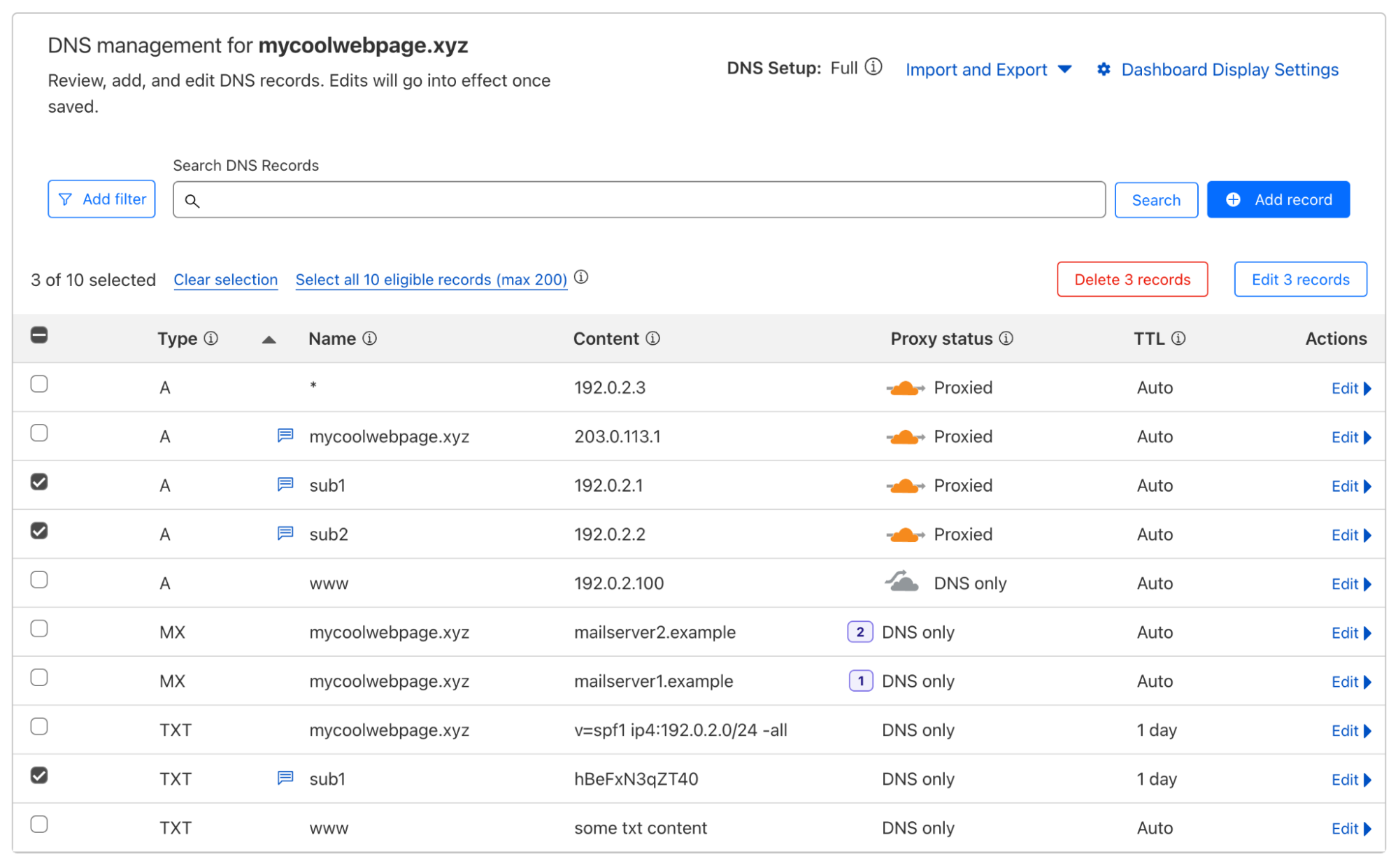
Customers that use Cloudflare to manage their DNS often need to create a whole batch of records, enable proxying on many records, update many records to point to a new target at the same time, or even delete all of their records. Historically, customers had to resort to bespoke scripts to make these changes, which came with their own set of issues. In response to customer demand, we are excited to announce support for batched API calls to the DNS records API starting today. This lets customers make large changes to their zones much more efficiently than before. Whether sending a POST, PUT, PATCH or DELETE, users can now execute these four different HTTP methods, and multiple HTTP requests all at the same time.
Efficient zone management matters
DNS records are an essential part of most web applications and websites, and they serve many different purposes. The most common use case for a DNS record is to have a hostname point to an IPv4 address, this is called an A record:
example.com 59 IN A 198.51.100.0
blog.example.com 59 IN A 198.51.100.1
ask.example.com 59 IN A 198.51.100.2
In its most simple form, this enables Internet users to connect to websites without needing to memorize their IP address.
Often, our customers need to be able to do things like create a whole batch of records, or enable proxying on many records, or update many records to point to a new target at the same time, or even delete all of their records. Unfortunately, for most of these cases, we were asking customers to write their own custom scripts or programs to do these tasks for them, a number of which are open sourced and whose content has not been checked by us. These scripts are often used to avoid needing to repeatedly make the same API calls manually. This takes time, not only for the development of the scripts, but also to simply execute all the API calls, not to mention it can leave the zone in a bad state if some changes fail while others succeed.
Introducing /batch
Starting today, everyone with a Cloudflare zone will have access to this endpoint, with free tier customers getting access to 200 changes in one batch, and paid plans getting access to 3,500 changes in one batch. We have successfully tested up to 100,000 changes in one call. The API is simple, expecting a POST request to be made to the new API endpoint /dns_records/batch, which passes in a JSON object in the body in the format:
{
deletes:[]Record
patches:[]Record
puts:[]Record
posts:[]Record
}
Each list of records []Record will follow the same requirements as the regular API, except that the record ID on deletes, patches, and puts will be required within the Record object itself. Here is a simple example:
{
"deletes": [
{
"id": "143004ef463b464a504bde5a5be9f94a"
},
{
"id": "165e9ef6f325460c9ca0eca6170a7a23"
}
],
"patches": [
{
"id": "16ac0161141a4e62a79c50e0341de5c6",
"content": "192.0.2.45"
},
{
"id": "6c929ea329514731bcd8384dd05e3a55",
"name": "update.example.com",
"proxied": true
}
],
"puts": [
{
"id": "ee93eec55e9e45f4ae3cb6941ffd6064",
"content": "192.0.2.50",
"name": "no-change.example.com",
"proxied": false,
"ttl:": 1
},
{
"id": "eab237b5a67e41319159660bc6cfd80b",
"content": "192.0.2.45",
"name": "no-change.example.com",
"proxied": false,
"ttl:": 3000
}
],
"posts": [
{
"name": "@",
"type": "A",
"content": "192.0.2.45",
"proxied": false,
"ttl": 3000
},
{
"name": "a.example.com",
"type": "A",
"content": "192.0.2.45",
"proxied": true
}
]
}Our API will then parse this and execute these calls in the following order:
deletes
patches
puts
posts
Each of these respective lists will be executed in the order given. This ordering system is important because it removes the need for our clients to worry about conflicts, such as if they need to create a CNAME on the same hostname as a to-be-deleted A record, which is not allowed in RFC 1912. In the event that any of these individual actions fail, the entire API call will fail and return the first error it sees. The batch request will also be executed inside a single database transaction, which will roll back in the event of failure.
After the batch request has been successfully executed in our database, we then propagate the changes to our edge via Quicksilver, our distributed KV store. Each of the individual record changes inside the batch request is treated as a single key-value pair, and database transactions are not supported. As such, we cannot guarantee that the propagation to our edge servers will be atomic. For example, if replacing a delegation with an A record, some resolvers may see the NS record removed before the A record is added.
The response will follow the same format as the request. Patches and puts that result in no changes will be placed at the end of their respective lists.
We are also introducing some new changes to the Cloudflare dashboard, allowing users to select multiple records and subsequently:
Delete all selected records
Change the proxy status of all selected records
We plan to continue improving the dashboard to support more batch actions based on your feedback.
The journey
Although at the surface, this batch endpoint may seem like a fairly simple change, behind the scenes it is the culmination of a multi-year, multi-team effort. Over the past several years, we have been working hard to improve the DNS pipeline that takes our customers’ records and pushes them to Quicksilver, our distributed database. As part of this effort, we have been improving our DNS Records API to reduce the overall latency. The DNS Records API is Cloudflare’s most used API externally, serving twice as many requests as any other API at peak. In addition, the DNS Records API supports over 20 internal services, many of which touch very important areas such as DNSSEC, TLS, Email, Tunnels, Workers, Spectrum, and R2 storage. Therefore, it was important to build something that scales.
To improve API performance, we first needed to understand the complexities of the entire stack. At Cloudflare, we use Jaeger tracing to debug our systems. It gives us granular insights into a sample of requests that are coming into our APIs. When looking at API request latency, the span that stood out was the time spent on each individual database lookup. The latency here can vary anywhere from ~1ms to ~5ms.


Jaeger trace showing variable database latency
Given this variability in database query latency, we wanted to understand exactly what was going on within each DNS Records API request. When we first started on this journey, the breakdown of database lookups for each action was as follows:
Action
Database Queries
Reason
POST
2
One to write and one to read the new record.
PUT
3
One to collect, one to write, and one to read back the new record.
PATCH
3
One to collect, one to write, and one to read back the new record.
DELETE
2
One to read and one to delete.
The reason we needed to read the newly created records on POST, PUT, and PATCH was because the record contains information filled in by the database which we cannot infer in the API.
Let’s imagine that a customer needed to edit 1,000 records. If each database lookup took 3ms to complete, that was 3ms * 3 lookups * 1,000 records = 9 seconds spent on database queries alone, not taking into account the round trip time to and from our API or any other processing latency. It’s clear that we needed to reduce the number of overall queries and ideally minimize per query latency variation. Let’s tackle the variation in latency first.
Each of these calls is not a simple INSERT, UPDATE, or DELETE, because we have functions wrapping these database calls for sanitization purposes. In order to understand the variable latency, we enlisted the help of PostgreSQL’s “auto_explain”. This module gives a breakdown of execution times for each statement without needing to EXPLAIN each one by hand. We used the following settings:
A handful of queries showed durations like the one below, which took an order of magnitude longer than other queries.

We noticed that in several locations we were doing queries like:
IF (EXISTS (SELECT id FROM table WHERE row_hash = __new_row_hash))
If you are trying to insert into very large zones, such queries could mean even longer database query times, potentially explaining the discrepancy between 1ms and 5ms in our tracing images above. Upon further investigation, we already had a unique index on that exact hash. Unique indexes in PostgreSQL enforce the uniqueness of one or more column values, which means we can safely remove those existence checks without risk of inserting duplicate rows.
The next task was to introduce database batching into our DNS Records API. In any API, external calls such as SQL queries are going to add substantial latency to the request. Database batching allows the DNS Records API to execute multiple SQL queries within one single network call, subsequently lowering the number of database round trips our system needs to make.
According to the table above, each database write also corresponded to a read after it had completed the query. This was needed to collect information like creation/modification timestamps and new IDs. To improve this, we tweaked our database functions to now return the newly created DNS record itself, removing a full round trip to the database. Here is the updated table:
Action
Database Queries
Reason
POST
1
One to write
PUT
2
One to read, one to write.
PATCH
2
One to read, one to write.
DELETE
2
One to read, one to delete.
We have room for improvement here, however we cannot easily reduce this further due to some restrictions around auditing and other sanitization logic.
Results:
Action
Average database time before
Average database time after
Percentage Decrease
POST
3.38ms
0.967ms
71.4%
PUT
4.47ms
2.31ms
48.4%
PATCH
4.41ms
2.24ms
49.3%
DELETE
1.21ms
1.21ms
0%
These are some pretty good improvements! Not only did we reduce the API latency, we also reduced the database query load, benefiting other systems as well.
Weren’t we talking about batching?
I previously mentioned that the /batch endpoint is fully atomic, making use of a single database transaction. However, a single transaction may still require multiple database network calls, and from the table above, that can add up to a significant amount of time when dealing with large batches. To optimize this, we are making use of pgx/batch, a Golang object that allows us to write and subsequently read multiple queries in a single network call. Here is a high level of how the batch endpoint works:
Collect all the records for the PUTs, PATCHes and DELETEs.
Apply any per record differences as requested by the PATCHes and PUTs.
Format the batch SQL query to include each of the actions.
Execute the batch SQL query in the database.
Parse each database response and return any errors if needed.
Audit each change.
This takes at most only two database calls per batch. One to fetch, and one to write/delete. If the batch contains only POSTs, this will be further reduced to a single database call. Given all of this, we should expect to see a significant improvement in latency when making multiple changes, which we do when observing how these various endpoints perform:
Note: Each of these queries was run from multiple locations around the world and the median of the response times are shown here. The server responding to queries is located in Portland, Oregon, United States. Latencies are subject to change depending on geographical location.
Create only:
10 Records
100 Records
1,000 Records
10,000 Records
Regular API
7.55s
74.23s
757.32s
7,877.14s
Batch API – Without database batching
0.85s
1.47s
4.32s
16.58s
Batch API – with database batching
0.67s
1.21s
3.09s
10.33s
Delete only:
10 Records
100 Records
1,000 Records
10,000 Records
Regular API
7.28s
67.35s
658.11s
7,471.30s
Batch API – without database batching
0.79s
1.32s
3.18s
17.49s
Batch API – with database batching
0.66s
0.78s
1.68s
7.73s
Create/Update/Delete:
10 Records
100 Records
1,000 Records
10,000 Records
Regular API
7.11s
72.41s
715.36s
7,298.17s
Batch API – without database batching
0.79s
1.36s
3.05s
18.27s
Batch API – with database batching
0.74s
1.06s
2.17s
8.48s
Overall Average:
10 Records
100 Records
1,000 Records
10,000 Records
Regular API
7.31s
71.33s
710.26s
7,548.87s
Batch API – without database batching
0.81s
1.38s
3.51s
17.44s
Batch API – with database batching
0.69s
1.02s
2.31s
8.85s
We can see that on average, the new batching API is significantly faster than the regular API trying to do the same actions, and it’s also nearly twice as fast as the batching API without batched database calls. We can see that at 10,000 records, the batching API is a staggering 850x faster than the regular API. As mentioned above, these numbers are likely to change for a number of different reasons, but it’s clear that making several round trips to and from the API adds substantial latency, regardless of the region.
Batch overload
Making our API faster is awesome, but we don’t operate in an isolated environment. Each of these records needs to be processed and pushed to Quicksilver, our distributed database. If we have customers creating tens of thousands of records every 10 seconds, we need to be able to handle this downstream so that we don’t overwhelm our system. In a May 2022 blog post titled How we improved DNS record build speed by more than 4,000x, I noted that:
We plan to introduce a batching system that will collect record changes into groups to minimize the number of queries we make to our database and Quicksilver.
This task has since been completed, and our propagation pipeline is now able to batch thousands of record changes into a single database query which can then be published to Quicksilver in order to be propagated to our global network.
Next steps
We have a couple more improvements we may want to bring into the API. We also intend to improve the UI to bring more usability improvements to the dashboard to more easily manage zones. We would love to hear your feedback, so please let us know what you think and if you have any suggestions for improvements.
For more details on how to use the new /batch API endpoint, head over to our developer documentation and API reference.
Source:: CloudFlare