Each time a user visits your web page, they are initiating a race to receive content as quickly as possible. Performance is a critical factor that influences how visitors interact with your site. Some might think that moving content across the globe introduces significant latency, but for a while, network transmission speeds have approached their theoretical limits. To put this into perspective, data on Cloudflare can traverse the 11,000 kilometer round trip between New York and London in about 76 milliseconds – faster than the blink of an eye.
However, delays in loading web pages persist due to the complexities of processing requests, responses, and configurations. In addition to pushing advancements in connection establishment, compression, hardware, and software, we have built a new way to reduce page load latency by anticipating how visitors will interact with a given web page.
Today we are very excited to share the latest leap forward in speed: Speed Brain. It relies on the Speculation Rules API to prefetch the content of the user’s likely next navigations. The main goal of Speed Brain is to download a web page to the browser cache before a user navigates to it, allowing pages to load almost instantly when the actual navigation takes place.
Our initial approach uses a conservative model that prefetches static content for the next page when a user starts a touch or click event. Through the fourth quarter of 2024 and into 2025, we will offer more aggressive speculation models, such as speculatively prerendering (not just fetching the page before the navigation happens but rendering it completely) for an even faster experience. Eventually, Speed Brain will learn how to eliminate latency for your static website, without any configuration, and work with browsers to make sure that it loads as fast as possible.
To illustrate, imagine an ecommerce website selling clothing. Using the insights from our global request logs, we can predict with high accuracy that a typical visitor is likely to click on ‘Shirts’ when viewing the parent page ‘Mens > Clothes’. Based on this, we can start delivering static content, like images, before the shopper even clicks the ‘Shirts’ link. As a result, when they inevitably click, the page loads instantly. Recent lab testing of our aggressive loading model implementation has shown up to a 75% reduction in Largest Contentful Paint (LCP), the time it takes for the largest visible element (like an image, video, or text block) to load and render in the browser.
The best part? We are making Speed Brain available to all plan types immediately and at no cost. Simply toggle on the Speed Brain feature for your website from the dashboard or the API. It’ll feel like magic, but behind the scenes it’s a lot of clever engineering.
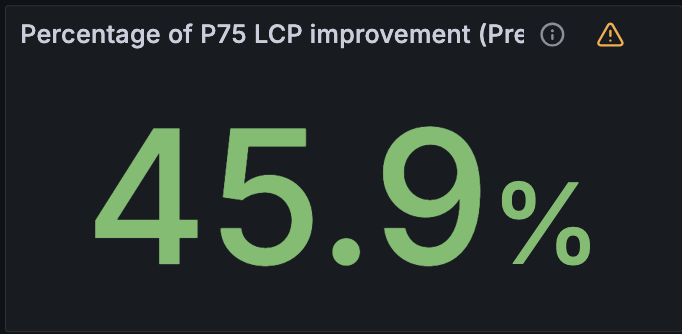
We have already enabled Speed Brain by default on all free domains and are seeing a reduction in LCP of 45% on successful prefetches. Pro, Business, and Enterprise domains need to enable Speed Brain manually. If you have not done so already, we strongly recommend also enabling Real User Measurements (RUM) via your dashboard so you can see your new and improved web page performance. As a bonus, enabling RUM for your domain will help us provide improved and customized prefetching and prerendering rules for your website in the near future!
How browsers work at a glance
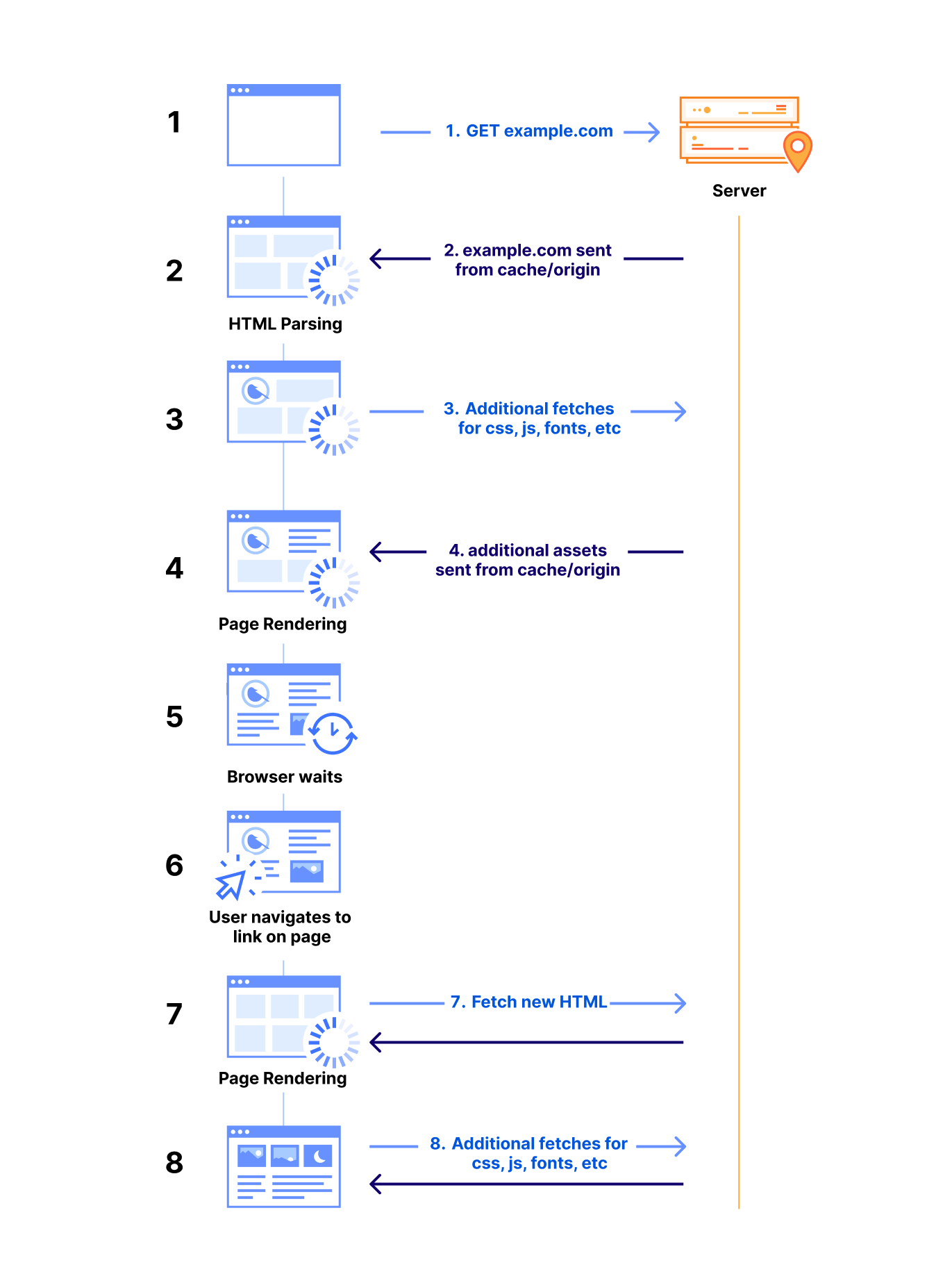
Before discussing how Speed Brain can help load content exceptionally fast, we need to take a step back to review the complexity of loading content on browsers. Every time a user navigates to your web page, a series of request and response cycles must be completed.
After the browser establishes a secure connection with a server, it sends an HTTP request to retrieve the base document of the web page. The server processes the request, constructs the necessary HTML document and sends it back to the browser in the response.
When the browser receives an HTML document, it immediately begins parsing the content. During this process, it may encounter references to external resources such as CSS files, JavaScript, images, and fonts. These subresources are essential for rendering the page correctly, so the browser issues additional HTTP requests to fetch them. However, if these resources are available in the browser’s cache, the browser can retrieve them locally, significantly reducing network latency and improving page load times.
As the browser processes HTML, CSS, and JavaScript, the rendering engine begins to display content on the screen. Once the page’s visual elements are displayed, user interactions — like clicking a link — prompt the browser to restart much of this process to fetch new content for the next page. This workflow is typical of every browsing session: as users navigate, the browser continually fetches and renders new or uncached resources, introducing a delay before the new page fully loads.
Take the example of a user navigating the shopping site described above. As the shopper moves from the homepage to the ‘men’s’ section of the site to the ‘clothing’ section to the ‘shirts’ section, the time spent on retrieving each of those subsequent pages can add up and contribute to the shopper leaving the site before they complete the transaction.
Ideally, having prefetched and prerendered pages present in the browser at the time each of those links are clicked would eliminate much of the network latency impact, allowing the browser to load content instantly and providing a smoother user experience.
Wait, I’ve heard this story before (how did we get to Speed Brain?)
We know what you’re thinking. We’ve had prefetching for years. There have even been several speculative prefetching efforts in the past. You’ve heard this all before. How is this different now?
You’re right, of course. Over the years, there has been a constant effort by developers and browser vendors to optimize page load times and enhance user experience across the web. Numerous techniques have been developed, spanning various layers of the Internet stack — from optimizing network layer connectivity to preloading application content closer to the client.
Early prefetching: lack of data and flexibility
Web prefetching has been one such technique that has existed for more than a decade. It is based on the assumption that certain subresources are likely to be needed in the near future, so why not fetch them proactively? This could include anything from HTML pages to images, stylesheets, or scripts that the user might need as they navigate through a website. In fact, the core concept of speculative execution is not new, as it’s a general technique that’s been employed in various areas of computer science for years, with branch prediction in CPUs as a prime example.
In the early days of the web, several custom prefetching solutions emerged to enhance performance. For example, in 2005, Google introduced the Google Web Accelerator, a client-side application aimed at speeding up browsing for broadband users. Though innovative, the project was short-lived due to privacy and compatibility issues (we will describe how Speed Brain is different below). Predictive prefetching at that time lacked the data insights and API support for capturing user behavior, especially those handling sensitive actions like deletions or purchases.
Static lists and manual effort
Traditionally, prefetching has been accomplished through the use of the attribute as one of the Resource Hints. Developers had to manually specify the attribute on each page for each resource they wanted the browser to preemptively fetch and cache in memory. This manual effort has not only been laborious but developers often lacked insight into what resources should be prefetched, which reduced the quality of their specified hints.
In a similar vein, Cloudflare has offered a URL prefetching feature since 2015. Instead of prefetching in browser cache, Cloudflare allows customers to prefetch a static list of resources into the CDN cache. The feature allows prefetching resources in advance of when they are actually needed, usually during idle time or when network conditions are favorable. However, similar concerns apply for CDN prefetching, since customers have to manually decide on what resources are good candidates for prefetching for each page they own. If misconfigured, static link prefetching can be a footgun, causing the web page load time to actually slow down.
Server Push and its struggles
HTTP/2’s “server push” was another attempt to improve web performance by pushing resources to the client before they were requested. In theory, this would reduce latency by eliminating the need for additional round trips for future assets. However, the server-centric dictatorial nature of “pushing” resources to the client raised significant challenges, primarily due to lack of context about what was already cached in the browser. This not only wasted bandwidth but had the potential to slow down the delivery of critical resources, like base HTML and CSS, due to race conditions on browser fetches when rendering the page. The proposed solution of cache digests, which would have informed servers about client cache contents, never gained widespread implementation, leaving servers to push resources blindly. In October 2022, Google Chrome removed Server Push support, and in September 2024, Firefox followed suit.
A step forward with Early Hints
As a successor, Early Hints was specified in 2017 but not widely adopted until 2022, when we partnered with browsers and key customers to deploy it. It offers a more efficient alternative by “hinting” to clients which resources to load, allowing better prioritization based on what the browser needs. Specifically, the server sends a 103 Early Hints HTTP status code with a list of key page assets that the browser should start loading while the main response is still being prepared. This gives the browser a head start in fetching essential resources and avoids redundant preloading if assets are already cached. Although Early Hints doesn’t adapt to user behaviors or dynamic page conditions (yet), its use is primarily limited to preloading specific assets rather than full web pages — in particular, cases where there is a long server “think time” to produce HTML.
As the web evolves, tools that can handle complex, dynamic user interactions will become increasingly important to balance the performance gains of speculative execution with its potential drawbacks for end-users. For years Cloudflare has offered performance-based solutions that adapt to user behavior and work to balance the speed and correctness decisions across the Internet like Argo Smart Routing, Smart Tiered Cache, and Smart Placement. Today we take another step forward toward an adaptable framework for serving content lightning-fast.
Enter Speed Brain: what makes it different?
Speed Brain offers a robust approach for implementing predictive prefetching strategies directly within the browser based on the ruleset returned by our servers. By building on lessons from previous attempts, it shifts the responsibility for resource prediction to the client, enabling more dynamic and personalized optimizations based on user interaction – like hovering over a link, for example – and their device capabilities. Instead of the browser sitting idly waiting for the next web page to be requested by the user, it takes cues from how a user is interacting with a page and begins asking for the next web page before the user finishes clicking on a link.
Behind the scenes, all of this magic is made possible by the Speculation Rules API, which is an emerging standard in the web performance space from Google. When Cloudflare’s Speed Brain feature is enabled, an HTTP header called Speculation-Rules is added to web page responses. The value for this header is a URL that hosts an opinionated Rules configuration. This configuration instructs the browser to initiate prefetch requests for future navigations. Speed Brain does not improve page load time for the first page that is visited on a website, but it can improve it for subsequent web pages that are visited on the same site.
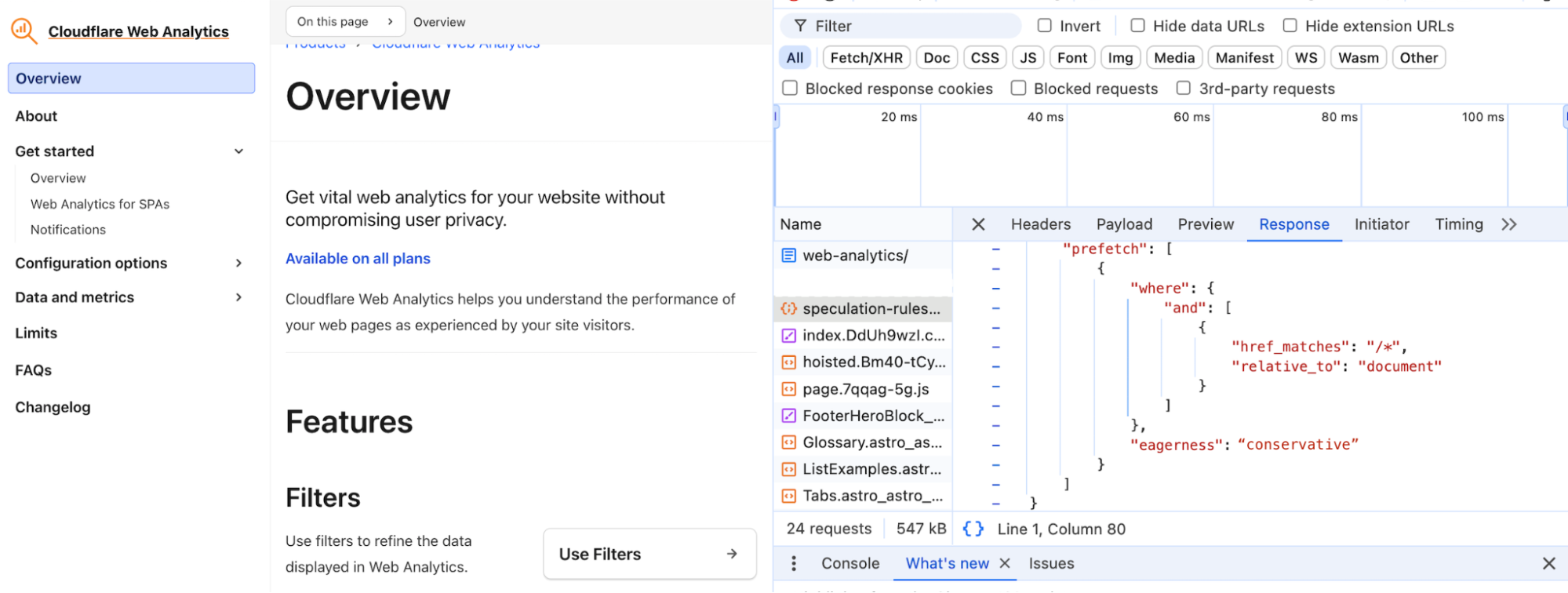
The idea seems simple enough, but prefetching comes with challenges, as some prefetched content may never end up being used. With the initial release of Speed Brain, we have designed a solution with guardrails that addresses two important but distinct issues that limited previous speculation efforts — stale prefetch configuration and incorrect prefetching. The Speculation Rules API configuration we have chosen for this initial release has been carefully designed to balance safety of prefetching while still maintaining broad applicability of rules for the entire site.
Stale prefetch configuration
As websites inevitably change over time, static prefetch configurations often become outdated, leading to inefficient or ineffective prefetching. This has been especially true for techniques like the rel=prefetch attribute or static CDN prefetching URL sets, which have required developers to manually maintain relevant prefetchable URL lists for each page of their website. Most static prefetch lists are based on developer intuition rather than real user navigation data, potentially missing important prefetch opportunities or wasting resources on unnecessary prefetches.
Incorrect prefetching
Since prefetch requests are just like normal requests except with a `sec-purpose` HTTP request header, they incur the same overhead on the client, network, and server. However, the crucial difference is that prefetch requests anticipate user behavior and the response might not end up being used, so all that overhead might be wasted. This makes prefetch accuracy extremely important — that is, maximizing the percentage of prefetched pages that end up being viewed by the user. Incorrect prefetching can lead to inefficiencies and unneeded costs, such as caching resources that aren’t requested, or wasting bandwidth and network resources, which is especially critical on metered mobile networks or in low-bandwidth environments.
Guardrails
With the initial release of Speed Brain, we have designed a solution with important side effect prevention guardrails that completely removes the chance of stale prefetch configuration, and minimizes the risk of incorrect prefetching. This opinionated configuration is achieved by leveraging the document rules and eagerness settings from the Speculation Rules API. Our chosen configuration looks like the following:
{
"prefetch": [{
"source": "document",
"where": {
"and": [
{ "href_matches": "/*", "relative_to": "document" },
]
},
"eagerness": "conservative"
}]
}
Document Rules
Document Rules, indicated by “source”: “document” and the “where” key in the configuration, allows prefetching to be applied dynamically over the entire web page. This eliminates the need for a predefined static URL list for prefetching. Hence, we remove the problem of stale prefetch configuration as prefetch candidate links are determined based on the active page structure.
Our use of “relative_to”: “document” in the where clause instructs the browser to limit prefetching to same-site links. This has the added bonus of allowing our implementation to avoid cross-origin prefetches to avoid any privacy implications for users, as it doesn’t follow them around the web.
Eagerness
Eagerness controls how aggressively the browser prefetches content. There are four possible settings:
immediate: Used as soon as possible on page load — generally as soon as the rule value is seen by the browser, it starts prefetching the next page.
eager: Identical to immediate setting above, but the prefetch trigger additionally relies on slight user interaction events, such as moving the cursor towards the link (coming soon).
moderate: Prefetches if you hold the pointer over a link for more than 200 milliseconds (or on the pointerdown event if that is sooner, and on mobile where there is no hover event).
conservative: Prefetches on pointer or touch down on the link.
Our initial release of Speed Brain makes use of the conservative eagerness value to minimize the risk of incorrect prefetching, which can lead to unintended resource waste while making your websites noticeably faster. While we lose out on the potential performance improvements that the more aggressive eagerness settings offer, we chose this cautious approach to prioritize safety for our users. Looking ahead, we plan to explore more dynamic eagerness settings for sites that could benefit from a more liberal setting, and we’ll also expand our rules to include prerendering.
Another important safeguard we implement is to only accept prefetch requests for static content that is already stored in our CDN cache. If the content isn’t in the cache, we reject the prefetch request. Retrieving content directly from our CDN cache for prefetching requests lets us bypass concerns about their cache eligibility. The rationale for this is straightforward: if a page is not eligible for caching, we don’t want it to be prefetched in the browser cache, as it could lead to unintended consequences and increased origin load. For instance, prefetching a logout page might log the user out prematurely before the user actually finishes their action. Stateful prefetching or prerendering requests can have unpredictable effects, potentially altering the server’s state for actions the client has not confirmed. By only allowing prefetching for pages already in our CDN cache, we have confidence those pages will not negatively impact the user experience.
These guardrails were implemented to work in performance-sensitive environments. We measured the impact of our baseline conservative deployment model on all pages across Cloudflare’s developer documentation in early July 2024. We found that we were able to prefetch the correct content, content that would in fact be navigated to by the users, 94% of the time. We did this while improving the performance of the navigation by reducing LCP at p75 quantile by 40% without inducing any unintended side effects. The results were amazing!
Explaining Cloudflare’s implementation
Our global network spans over 330 cities and operates within 50 milliseconds of 95% of the Internet-connected population. This extensive reach allows us to significantly improve the performance of cacheable assets for our customers. By leveraging this network for smart prefetching with Speed Brain, Cloudflare can serve prefetched content directly from the CDN cache, reducing network latency to practically instant.
Our unique position on the network provides us the leverage to automatically enable Speed Brain without requiring any changes from our customers to their origin server configurations. It’s as simple as flipping a switch! Our first version of Speed Brain is now live.
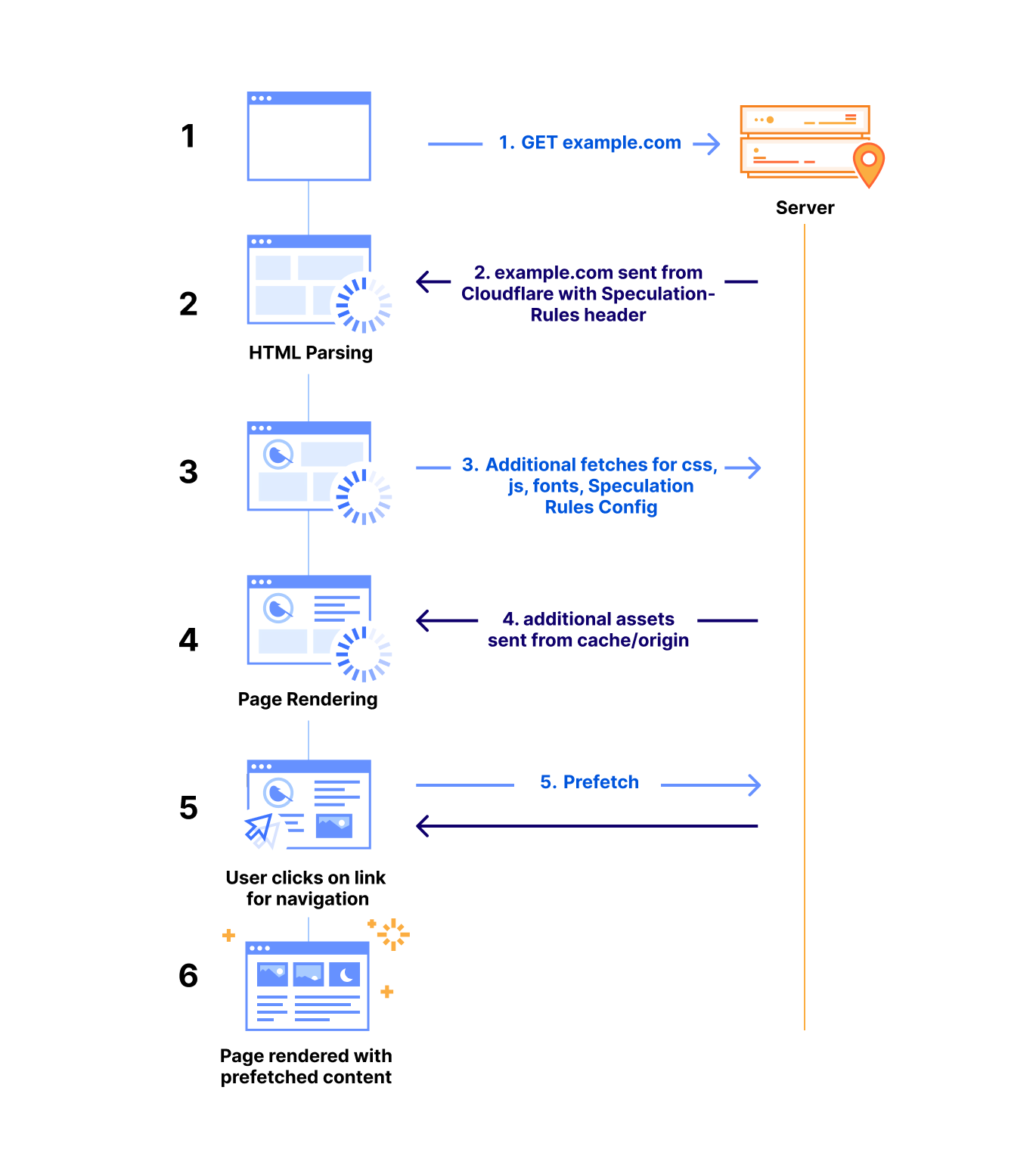
Upon receiving a request for a web page with Speed Brain enabled, the Cloudflare server returns an additional “Speculation-Rules” HTTP response header. The value for this header is a URL that hosts an opinionated Rules configuration (as mentioned above).
When the browser begins parsing the response header, it fetches our Speculation-Rules configuration, and loads it as part of the web page.
The configuration guides the browser on when to prefetch the next likely page from Cloudflare that the visitor may navigate to, based on how the visitor is engaging with the page.
When a user action (such as mouse down event on the next page link) triggers the Rules application, the browser sends a prefetch request for that page with the “sec-purpose: prefetch” HTTP request header.
Our server parses the request header to identify the prefetch request. If the requested content is present in our cache, we return it; otherwise, we return a 503 HTTP status code and deny the prefetch request. This removes the risk of unsafe side-effects of sending requests to origins or Cloudflare Workers that are unaware of prefetching. Only content present exclusively in the cache is returned.
On a success response, the browser successfully prefetches the content in memory, and when the visitor navigates to that page, the browser directly loads the web page from the browser cache for immediate rendering.
Common troubleshooting patterns
Support for Speed Brain relies on the Speculation Rules API, an emerging web standard. As of September 2024, support for this emerging standard is limited to Chromium-based browsers (version 121 or later), such as Google Chrome and Microsoft Edge. As the web community reaches consensus on API standardization, we hope to see wider adoption across other browser vendors.
Prefetching by nature does not apply to dynamic content, as the state of such content can change, potentially leading to stale or outdated data being delivered to the end user as well as increased origin load. Therefore, Speed Brain will only work for non-dynamic pages of your website that are cached on our network. It has no impact on the loading of dynamic pages. To get the most benefit out of Speed Brain, we suggest making use of cache rules to ensure that all static content (especially HTML content) on your site is eligible for caching.
When the browser receives a 503 HTTP status code in response to a speculative prefetch request (marked by the sec-purpose: prefetch header), it cancels the prefetch attempt. Although a 503 error appearing in the browser’s console may seem alarming, it is completely harmless for prefetch request cancellation. In our early tests, the 503 response code has caused some site owners concern. We are working with our partners to iterate on this to improve the client experience, but for now follow the specification guidance, which suggests a 503 response for the browser to safely discard the speculative request. We’re in active discussions with Chrome, based on feedback from early beta testers, and believe a new non-error dedicated response code would be more appropriate, and cause less confusion. In the meantime, 503 response logs for prefetch requests related to Speed Brain are harmless. If your tooling makes ignoring these requests difficult, you can temporarily disable Speed Brain until we work out something better with the Chrome Team.
Additionally, when a website uses both its own custom Speculation Rules and Cloudflare’s Speed Brain feature, both rule sets can operate simultaneously. Cloudflare’s guardrails will limit speculation rules to cacheable pages, which may be an unexpected limitation for those with existing implementations. If you observe such behavior, consider disabling one of the implementations for your site to ensure consistency in behavior. Note that if your origin server responses include the Speculation-Rules header, it will not be overridden. Therefore, the potential for ruleset conflicts primarily applies to predefined in-line speculation rules.
How can I see the impact of Speed Brain?
In general, we suggest that you use Speed Brain and most other Cloudflare performance features with our RUM performance measurement tool enabled. Our RUM feature helps developers and website operators understand how their end users are experiencing the performance of their application, providing visibility into:
Loading: How long did it take for content to become available?
Interactivity: How responsive is the website when users interact with it?
Visual stability: How much does the page move around while loading?
With RUM enabled, you can navigate to the Web Analytics section in the dashboard to see important information about how Speed Brain is helping reduce latency in your core web vitals metrics like Largest Contentful Paint (LCP) and load time.
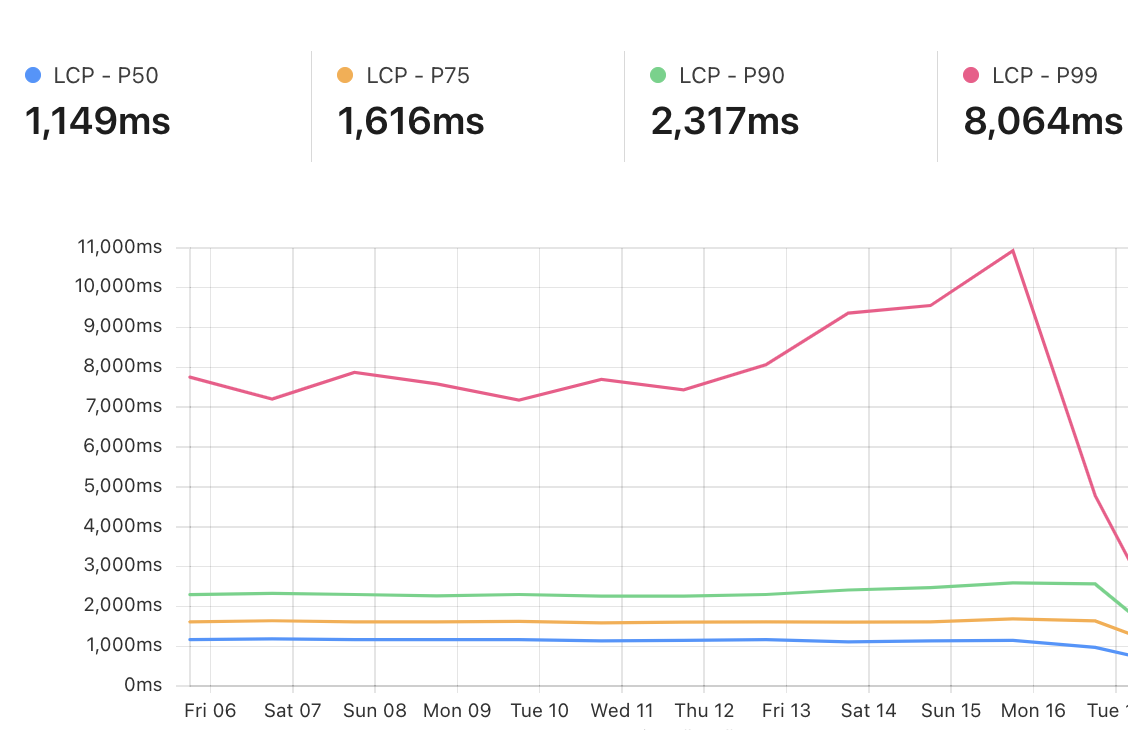
Example RUM dashboard for a website with a high amount of prefetchable content that enabled Speed Brain around September 16.
What have we seen in our rollout so far?
We have enabled this feature by default on all free plans and have observed the following:
Domains
Cloudflare currently has tens of millions of domains using Speed Brain. We have measured the LCP at the 75th quantile (p75) for these sites and found an improvement for these sites between 40% and 50% (average around 45%).
We found this improvement by comparing navigational prefetches to normal (non-prefetched) page loads for the same set of domains.
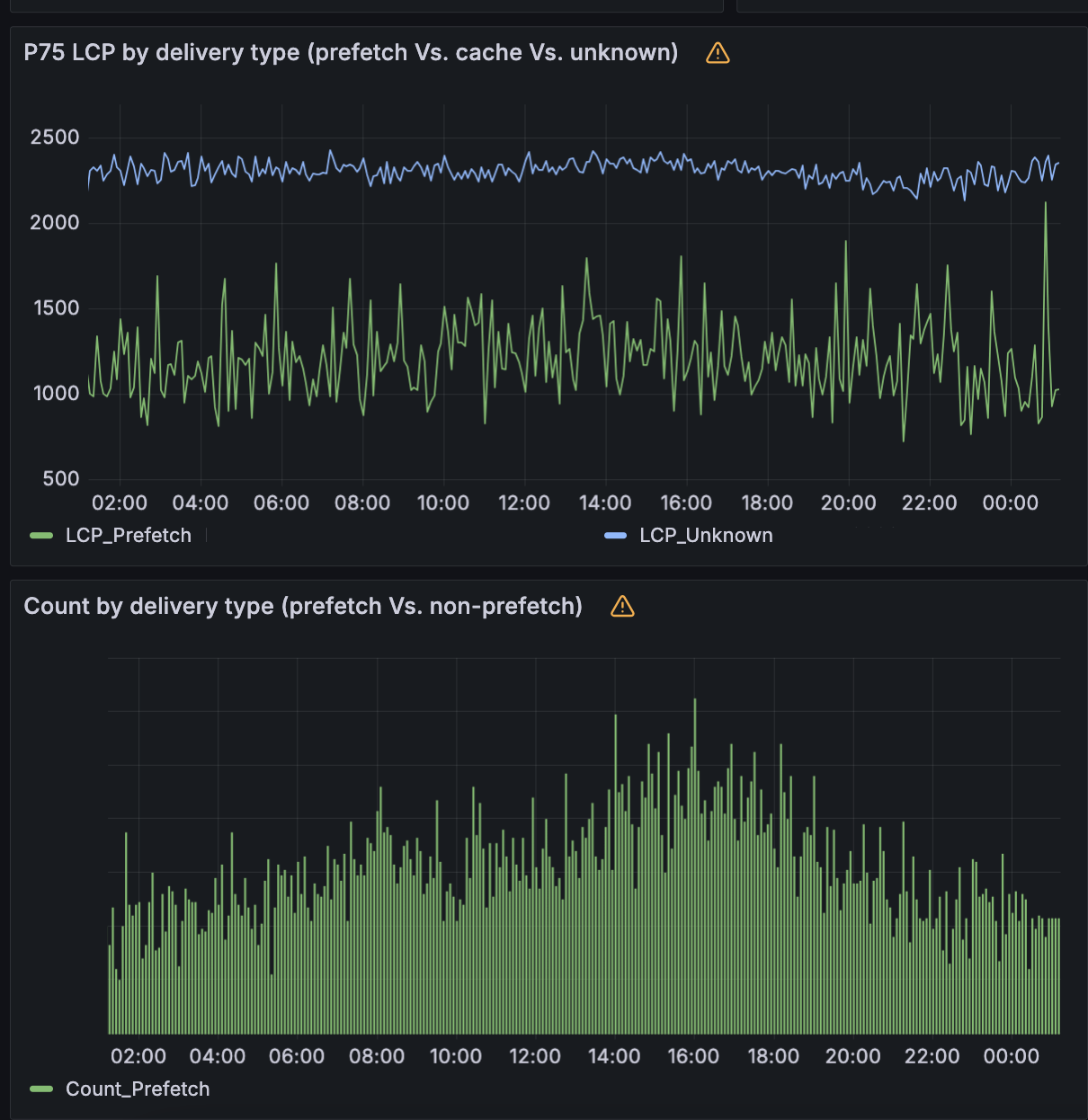
Requests
Before Speed Brain is enabled, the p75 of free websites on Cloudflare experience an LCP around 2.2 seconds. With Speed Brain enabled, these sites see significant latency savings on LCP. In aggregate, Speed Brain saves about 0.88 seconds on the low end and up to 1.1 seconds on each successful prefetch!
Applicable browsers
Currently, the Speculation Rules API is only available in Chromium browsers. From Cloudflare Radar, we can see that approximately 70% of requests from visitors are from Chromium (Chrome, Edge, etc) browsers.
Across the network
Cloudflare sees hundreds of billions of requests for HTML content each day. Of these requests, about half are cached (make sure your HTML is cacheable!). Around 1% of those requests are for navigational prefetching made by the visitors. This represents significant savings every day for visitors to websites with Speed Brain enabled. Every 24 hours, Speed Brain can save more than 82 years worth of latency!
What’s next?
What we’re offering today for Speed Brain is only the beginning. Heading into 2025, we have a number of exciting additions to explore and ship.
Leveraging Machine Learning
Our unique position on the Internet provides us valuable insights into web browsing patterns, which we can leverage for improving web performance while maintaining individual user privacy. By employing a generalized data-driven machine learning approach, we can define more accurate and site-specific prefetch predictors for users’ pages.
We are in the process of developing an adaptive speculative model that significantly improves upon our current conservative offering. This model uses a privacy-preserving method to generate a user traversal graph for each site based on same-site Referrer headers. For any two pages connected by a navigational hop, our model predicts the likelihood of a typical user moving between them, using insights extracted from our aggregated traffic data.
This model enables us to tailor rule sets with custom eagerness values to each relevant next page link on your site. For pages where the model predicts high confidence in user navigation, the system will aggressively prefetch or prerender them. If the model does not provide a rule for a page, it defaults to our existing conservative approach, maintaining the benefits of baseline Speed Brain model. These signals guide browsers in prefetching and prerendering the appropriate pages, which helps speed up navigation for users, while maintaining our current safety guardrails.
In lab tests, our ML model improved LCP latency by 75% and predicted visitor navigation with ~98% accuracy, ensuring the correct pages were being prefetched to prevent resource waste for users. As we move toward scaling this solution, we are focused on periodic training of the model to adapt to varying user behaviors and evolving websites. Using an online machine learning approach will drastically reduce the need for any manual update, and content drifts, while maintaining high accuracy — the Speed Brain load solution that gets smarter over time!
Finer observability via RUM
As we’ve mentioned, we believe that our RUM tools offer the best insights for how Speed Brain is helping the performance of your website. In the future, we plan on offering the ability to filter RUM tooling by navigation type so that you can compare the browser rendering of prefetched content versus non-prefetched content.
Prerendering
We are currently offering the ability for prefetching on cacheable content. Prefetching downloads the main document resource of the page before the user’s navigation, but it does not instruct the browser to prerender the page or download any additional subresources.
In the future, Cloudflare’s Speed Brain offering will prefetch content into our CDN cache and then work with browsers to know what are the best prospects for prerendering. This will help get static content even closer to instant rendering.
Argo Smart Browsing: Speed Brain & Smart Routing
Speed Brain, in its initial implementation, provides an incredible performance boost whilst still remaining conservative in its implementation; both from an eagerness, and a resource consumption perspective.
As was outlined earlier in the post, lab testing of a more aggressive model, powered by machine-learning and a higher eagerness, yielded a 75% reduction in LCP. We are investigating bundling this more aggressive, additional implementation of Speed Brain with Argo Smart Routing into a product called “Argo Smart Browsing”.
Cloudflare customers will be free to continue using Speed Brain, however those who want even more performance improvement will be able to enable Argo Smart Browsing with a single button click. With Argo Smart Browsing, not only will cacheable static content load up to 75% faster in the browser, thanks to the more aggressive models, however in times when content can’t be cached, and the request must go forward to an origin server, it will be sent over the most performant network path resulting in an average 33% performance increase. Performance optimizations are being applied to almost every segment of the request lifecycle regardless if the content is static or dynamic, cached or not.
Conclusion
To get started with Speed Brain, navigate to Speed > Optimization > Content Optimization > Speed Brain in the Cloudflare Dashboard and enable it. That’s all! The feature can also be enabled via API. Free plan domains have had Speed Brain enabled by default.
We strongly recommend that customers also enable RUM, found in the same section of the dashboard, to give visibility into the performance improvements provided by Speed Brain and other Cloudflare features and products.
We’re excited to continue to build products and features that make web performance reliably fast. If you’re an engineer interested in improving the performance of the web for all, come join us!

Source:: CloudFlare