Cloudflare handles over 60 million HTTP requests per second globally, with approximately 70% received over TCP connections (the remaining are QUIC/UDP). Ideally, every new TCP connection to Cloudflare would carry at least one request that results in a successful data exchange, but that is far from the truth. In reality, we find that, globally, approximately 20% of new TCP connections to Cloudflare’s servers time out or are closed with a TCP “abort” message either before any request can be completed or immediately after an initial request.
This post explores those connections that, for various reasons, appear to our servers to have been halted unexpectedly before any useful data exchange occurs. Our work reveals that while connections are normally ended by clients, they can also be closed due to third-party interference. Today we’re excited to launch a new dashboard and API endpoint on Cloudflare Radar that shows a near real-time view of TCP connections to Cloudflare’s network that terminate within the first 10 ingress packets due to resets or timeouts, which we’ll refer to as anomalous TCP connections in this post. Analyzing this anomalous behavior provides insights into scanning, connection tampering, DoS attacks, connectivity issues, and other behaviors.
Our ability to generate and share this data via Radar follows from a global investigation into connection tampering. Readers are invited to read the technical details in the peer-review study, or see its corresponding presentation. Read on for a primer on how to use and interpret the data, as well as how we designed and deployed our detection mechanisms so that others might replicate our approach.
To begin, let’s discuss our classification of normal vs anomalous TCP connections.
TCP connections from establishment to close
The Transmission Control Protocol (TCP) is a protocol for reliably transmitting data between two hosts on the Internet (RFC 9293). A TCP connection passes through several distinct stages, from connection establishment, to data transfer, to connection close.
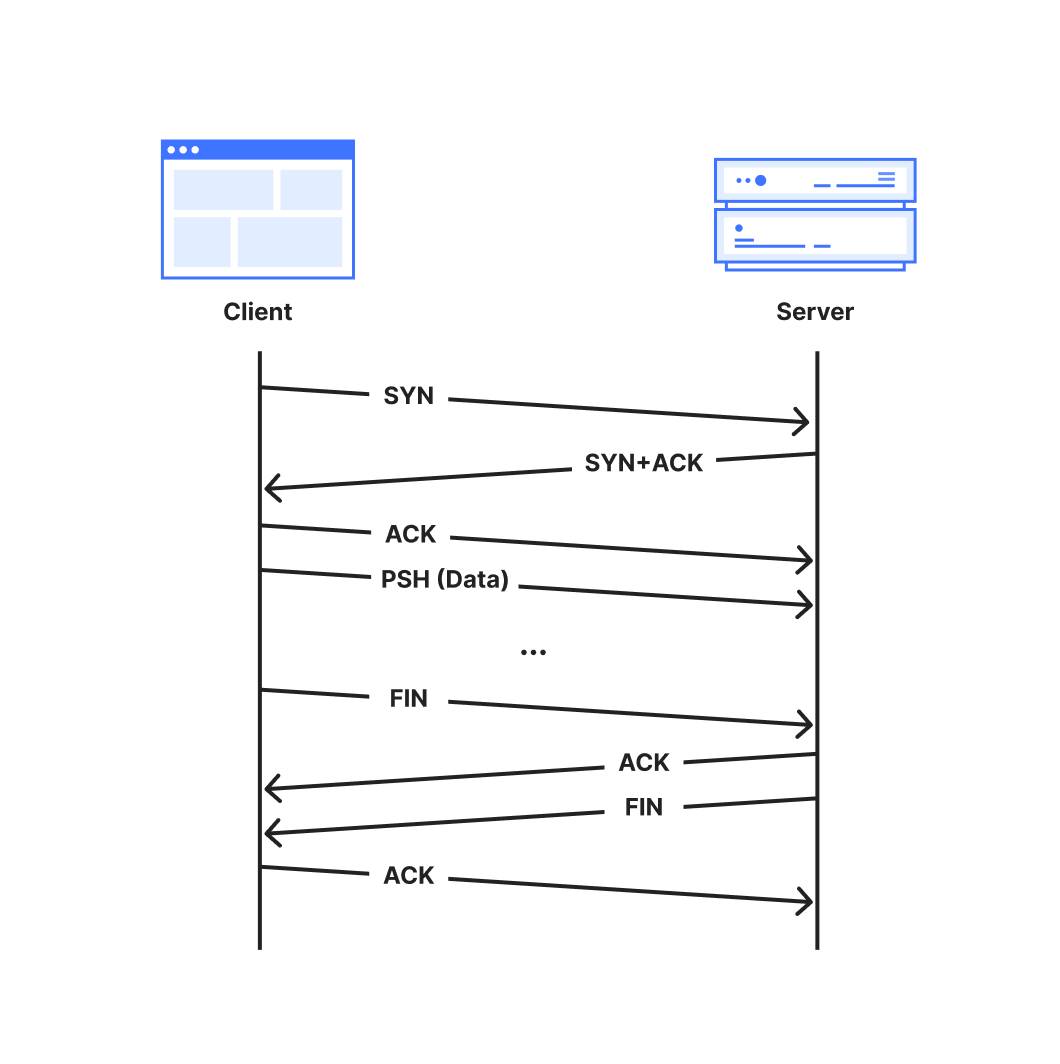
A TCP connection is established with a 3-way handshake. The handshake begins when one party, called the client, sends a packet marked with the ‘SYN’ flag to initialize the connection process. The server responds with a “SYN+ACK” packet where the ‘ACK’ flag acknowledges the client’s initialization ‘SYN’. Additional synchronization information is included in both the initialization packet and its acknowledgement. . Finally, the client acknowledges the server’s SYN+ACK packet with a final ACK packet to complete the handshake.
The connection is then ready for data transmission. Typically, the client will set the PSH flag on the first data-containing packet to signal to the server’s TCP stack to forward the data immediately up to the application. Both parties continue to transfer data and acknowledge received data until the connection is no longer needed, at which point the connection is closed.
RFC 9293 describes two ways in which a TCP connection may be closed:
The normal and graceful TCP close sequence uses a FIN exchange. Either party can send a packet with the FIN flag set to indicate that they have no more data to transmit. Once the other party acknowledges that FIN packet, that direction of the connection is closed. When the acknowledging party is finished transmitting data, it transmits its own FIN packet to close, since each direction of the connection must be closed independently.
An abort or “reset” signal in which one party transmits RST packets, instructing the other party to immediately close and discard any connection state. Resets are generally sent when some unrecoverable error has occurred.
The full lifetime of a connection that closes gracefully with a FIN is captured in the following sequence diagram.
A normal TCP connection starts with a 3-way handshake and ends with a FIN handshake
Additionally, a TCP connection may be terminated by a timeout which specifies the maximum duration that a connection can be active without receiving data or acknowledgements. An inactive connection, for example, can be kept open with keepalive messages. Unless overridden, the global default duration specified in RFC 9293 is five minutes.
We consider TCP connections anomalous when they close via either a reset or timeout from the client side.
Sources of anomalous connections
Anomalous TCP connections may not themselves be problematic but they can be a symptom of larger issues, especially when occurring at early (pre-data) stages of TCP connections. Below is a non-exhaustive list of potential reasons that we might observe resets or timeouts:
Scanners: Internet scanners may send a SYN packet to probe if a server responds on a given port, but otherwise fail to clean up a connection once the probe has elicited a response from the server.
Sudden Application Shutdowns: Applications might abruptly close open connections if they are no longer required. For example, web browsers may send RSTs to terminate connections after a tab is closed, or connections can time out if devices lose power or connectivity.
Network Errors: Unstable network conditions (e.g., a severed cable connection could result in connection timeouts)
Attacks: A malicious client may send attack traffic that appears as anomalous connections. For instance, in a SYN flood (half-open) attack, an attacker repeatedly sends SYN packets to a target server in an attempt to overwhelm resources as it maintains these half-opened connections.
Tampering: Firewalls or other middleboxes capable of intercepting packets between a client and server may drop packets, causing timeouts at the communicating parties. Middleboxes capable of deep packet inspection (DPI) might also leverage the fact that the TCP protocol is unauthenticated and unencrypted to inject packets to disrupt the connection state. See our accompanying blog post for more details on connection tampering.
Understanding the scale and underlying reasons for anomalous connections can help us to mitigate failures and build a more robust and reliable network. We hope that sharing these insights publicly will help to improve transparency and accountability for networks worldwide.
How to use the dataset
In this section, we provide guidance and examples of how to interpret the TCP resets and timeouts dataset by broadly describing three use cases: confirming previously-known behaviors, exploring new targets for followup study, and longitudinal studies to capture changes in network behavior over time.
In each example, the plot lines correspond to the stage of the connection in which the anomalous connection closed, which provides valuable clues into what might have caused the anomaly. We place each incoming connection into one of the following stages:
Post-SYN (mid-handshake): Connection resets or timeouts after the server received a client’s SYN packet. Our servers will have replied, but no acknowledgement ACK packet has come back from the client before the reset or timeout. Packet spoofing is common at this connection stage, so geolocation information is especially unreliable.
Post-ACK (immediately post-handshake): Connection resets or timeouts after the handshake completes and the connection is established successfully. Any subsequent data, that may have been transmitted, never reached our servers.
Post-PSH (after first data packet): Connection resets or timeouts after the server received a packet with the PSH flag set. The PSH flag indicates that the TCP packet contains data (such as a TLS Client Hello message) that is ready to be delivered to the application.
Later (after multiple data packets): Connection resets within the first 10 packets from the client, but after the server has received multiple data packets.
None: All other connections.
To keep focus on legitimate connections, the dataset is constructed after connections are processed and filtered by Cloudflare’s attack mitigation systems. For more details on how we construct the dataset, see below.
Start with a self-evaluation
To start, we encourage readers to visit the dashboard on Radar to view the results worldwide, and for their own country and ISP.
Globally, as shown below, about 20% of new TCP connections to Cloudflare’s network are closed by a reset or timeout within the first 10 packets from the client. While this number seems astonishingly high, it is in-line with prior studies. As we’ll see, rates of resets and timeouts vary widely by country and network, and this variation is lost in the global averages.
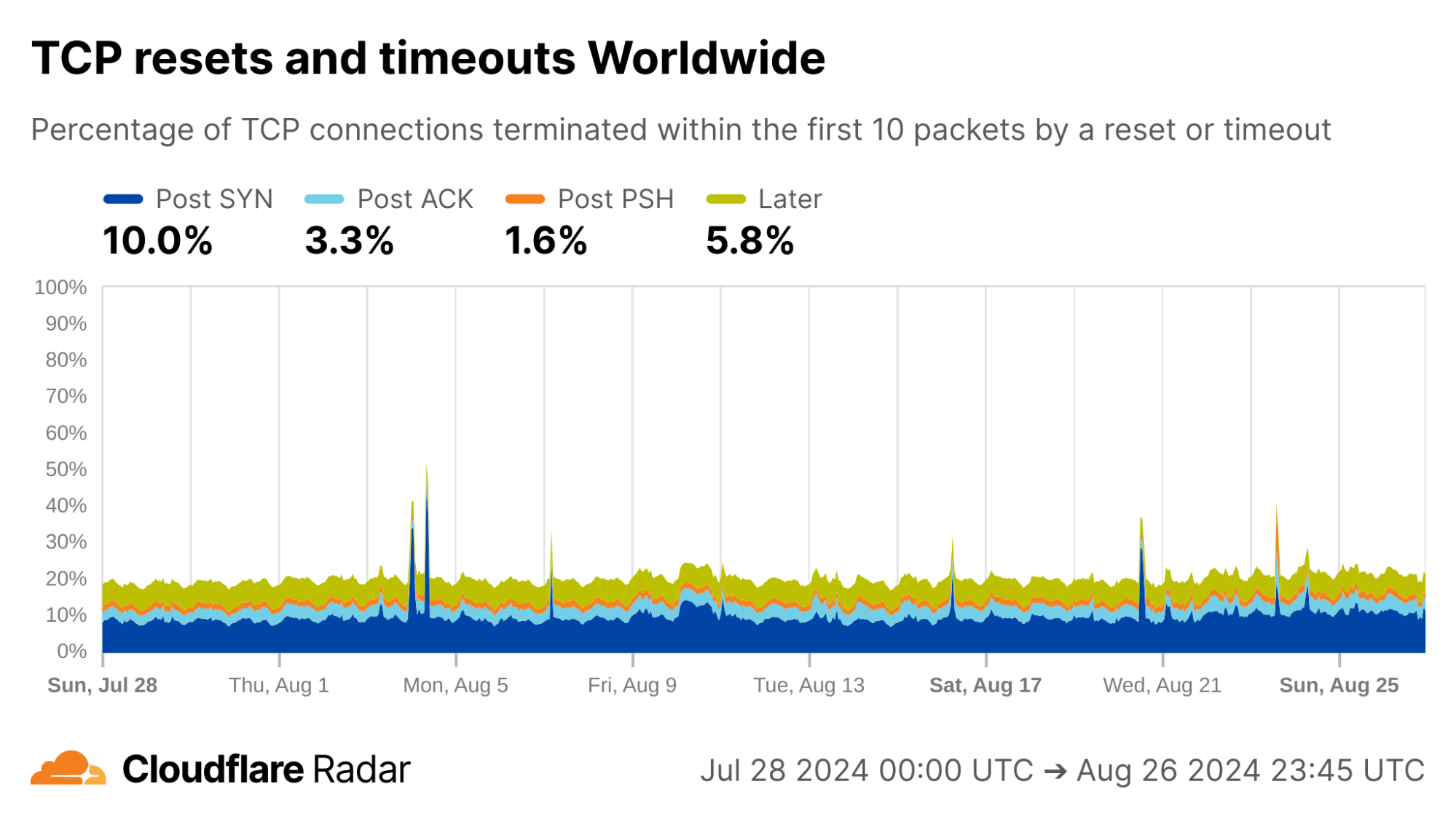
via Cloudflare Radar
The United States, my home country, shows anomalous connection rates slightly lower than the worldwide averages, largely due to lower rates for connections closing in the Post-ACK and Post-PSH stages (those stages are more reflective of middlebox tampering behavior). The elevated rates of Post-SYN are typical in most networks due to scanning, but may include packets that spoof the true client’s IP address. Similarly, high rates of connection resets in the Later connection stage (after the initial data exchange, but still within the first 10 packets) might be applications responding to human actions, such as browsers using RSTs to close unwanted TCP connections after a tab is closed.
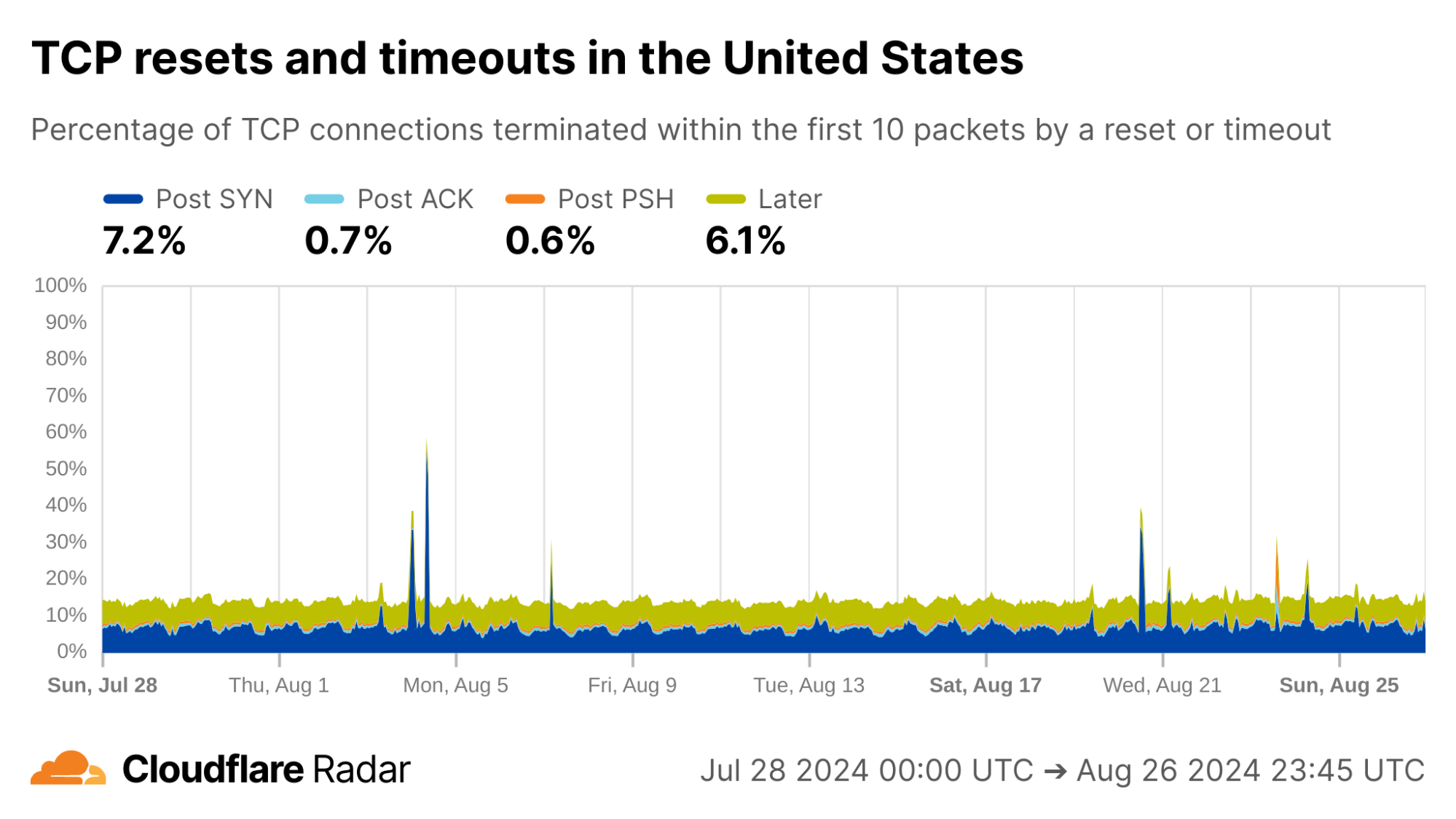
via Cloudflare Radar
My home ISP AS22773 (Cox Communications) shows rates comparable to the US as a whole. This is typical of most residential ISPs operating in the United States.
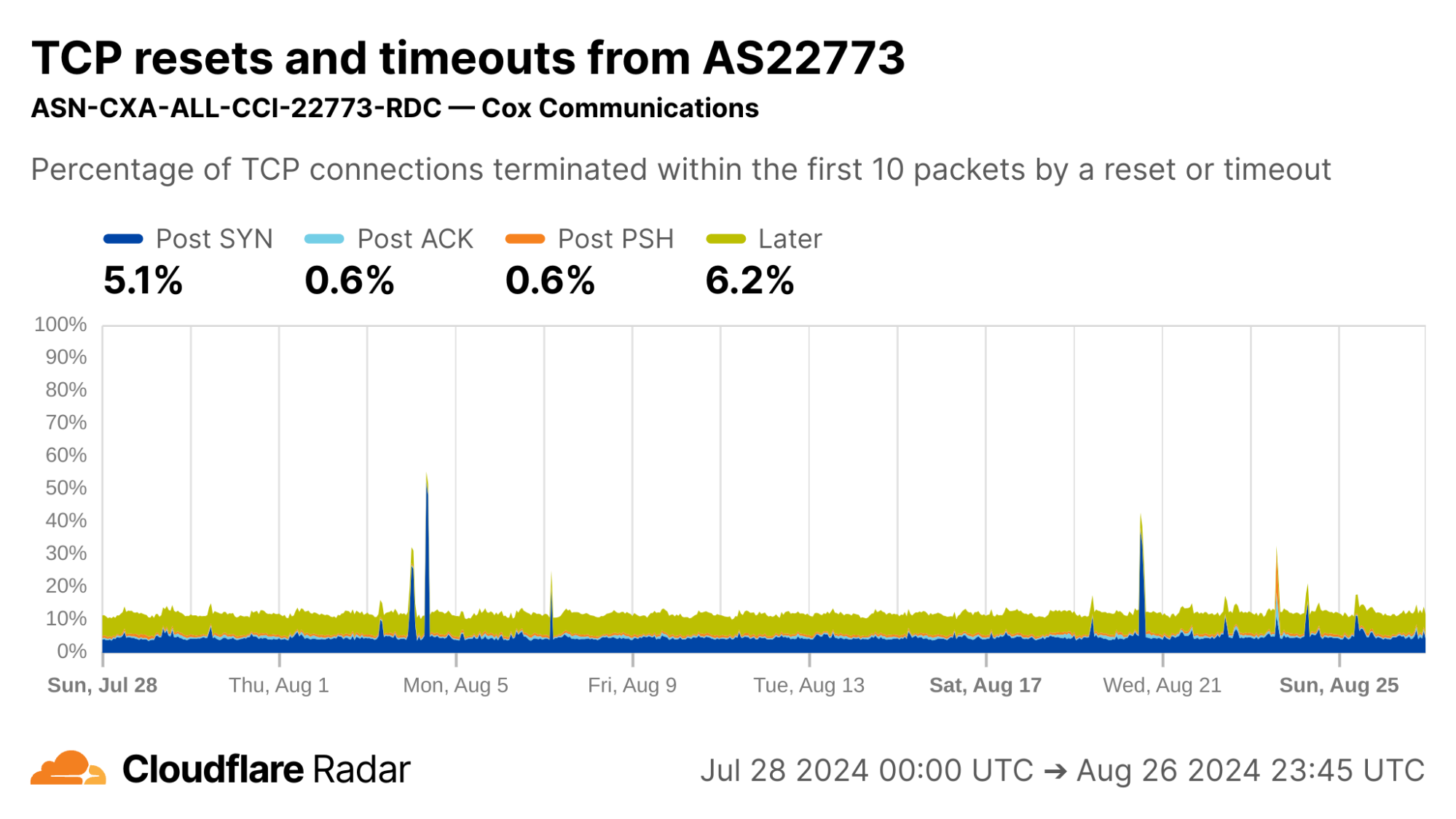
via Cloudflare Radar
Contrast this against AS15169 (Google LLC), which originates many of Google’s crawlers and fetchers. This network shows significantly lower rates of resets in the “Later” connection stage, which may be explained by the larger proportion of automated traffic, not driven by human user actions (such as closing browser tabs).
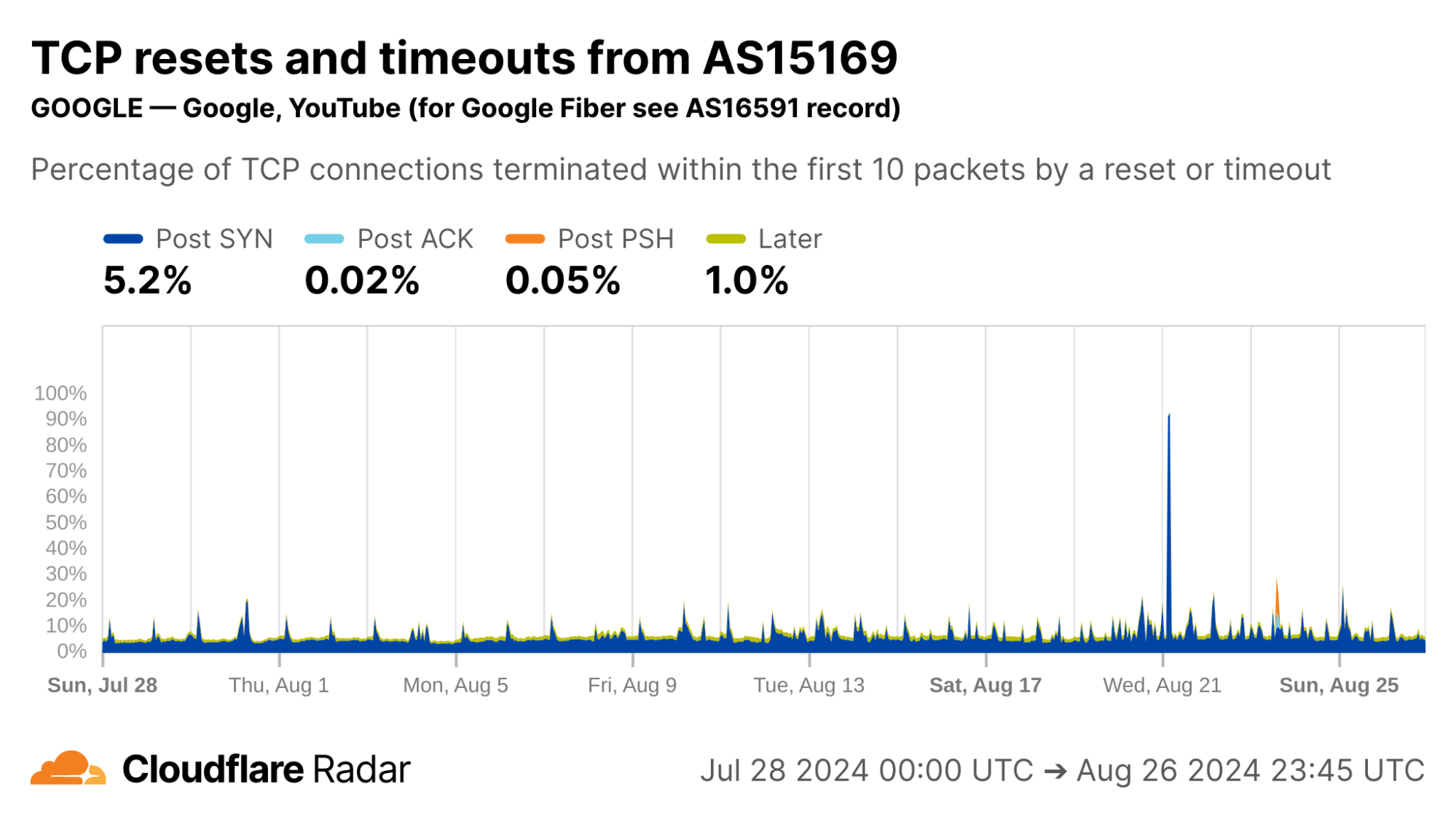
via Cloudflare Radar
Indeed, our bot detection system classifies over 99% of HTTP requests from AS15169 as automated. This shows the value of collating different types of data on Radar.
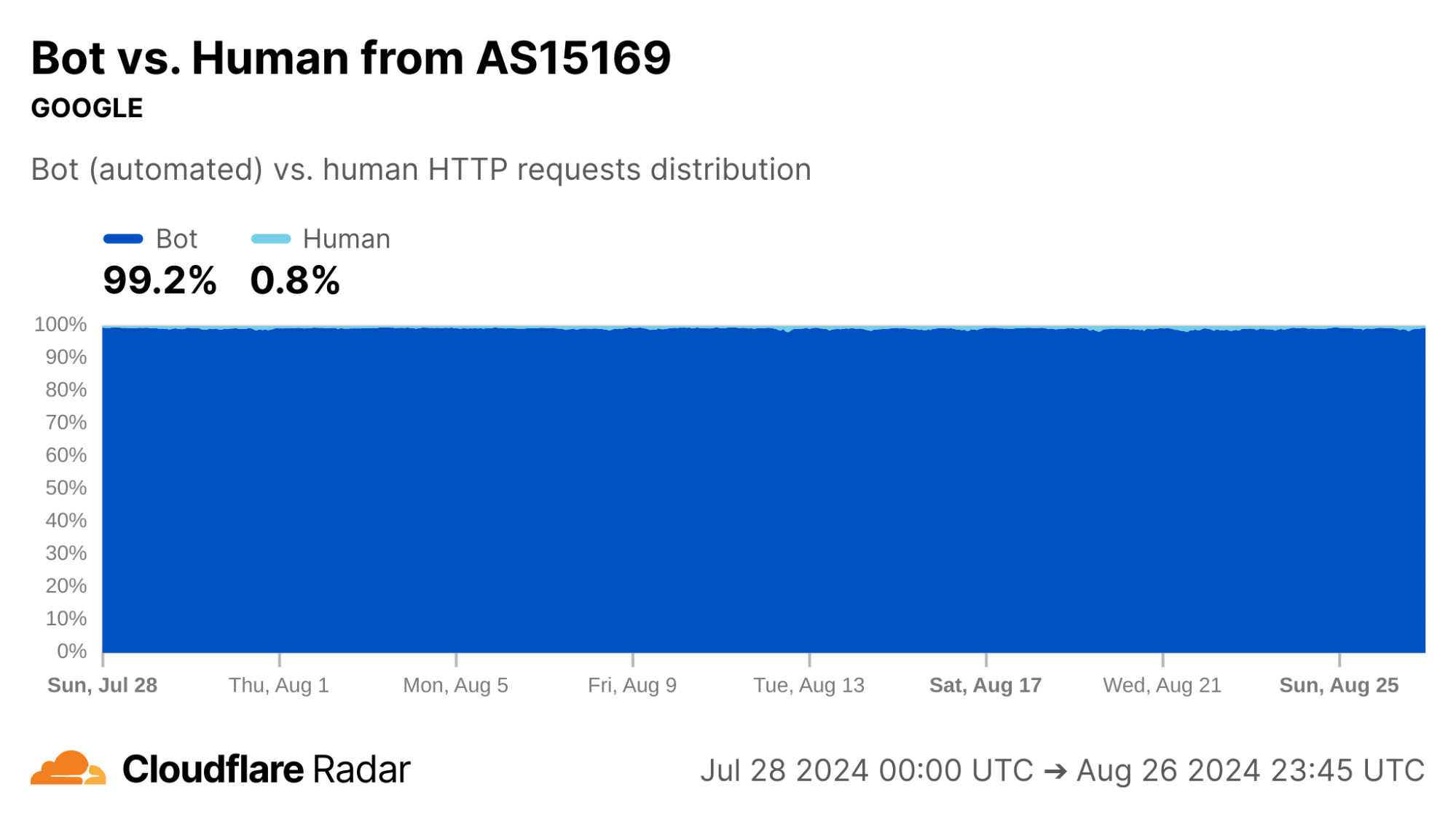
via Cloudflare Radar
The new anomalous connections dataset, like most that appear on Radar, is passive – it only reports on observable events, not what causes them. In this spirit, the graphs above for Google’s network reinforce the reason for corroborating observations, as we discuss next.
One view for a signal, more views for corroboration
Our passive measurement approach works at Cloudflare scale. However, it does not identify root causes or ground truth on its own. There are many plausible explanations for why a connection closed in a particular stage, especially when the closure is due to reset packets and timeouts. Attempts to explain by relying solely on this data source can only lead to speculation.
However, this limitation can be overcome by combining with other data sources such as active measurements. For example, corroborating with reports from OONI or Censored Planet, or with on-the-ground reports, can give a more complete story. Thus, one of the major use cases for the TCP resets and timeouts dataset is to understand the scale and impact of previously-documented phenomena.
Corroborating Internet-scale measurement projects
Looking at AS398324 would suggest something terribly wrong, with more than half of connections showing up as anomalous in the Post-SYN stage. However, this network turns out to be CENSYS-ARIN-01, from Internet scanning company Censys. Post-SYN anomalies can be the result of network-layer scanning, where the scanner sends a single SYN packet to probe the server, but does not complete the TCP handshake. There are also high rates of Later anomalies, which could be indicative of application-layer scanning, as indicated by the near 100% proportion of connections being classified as automated.
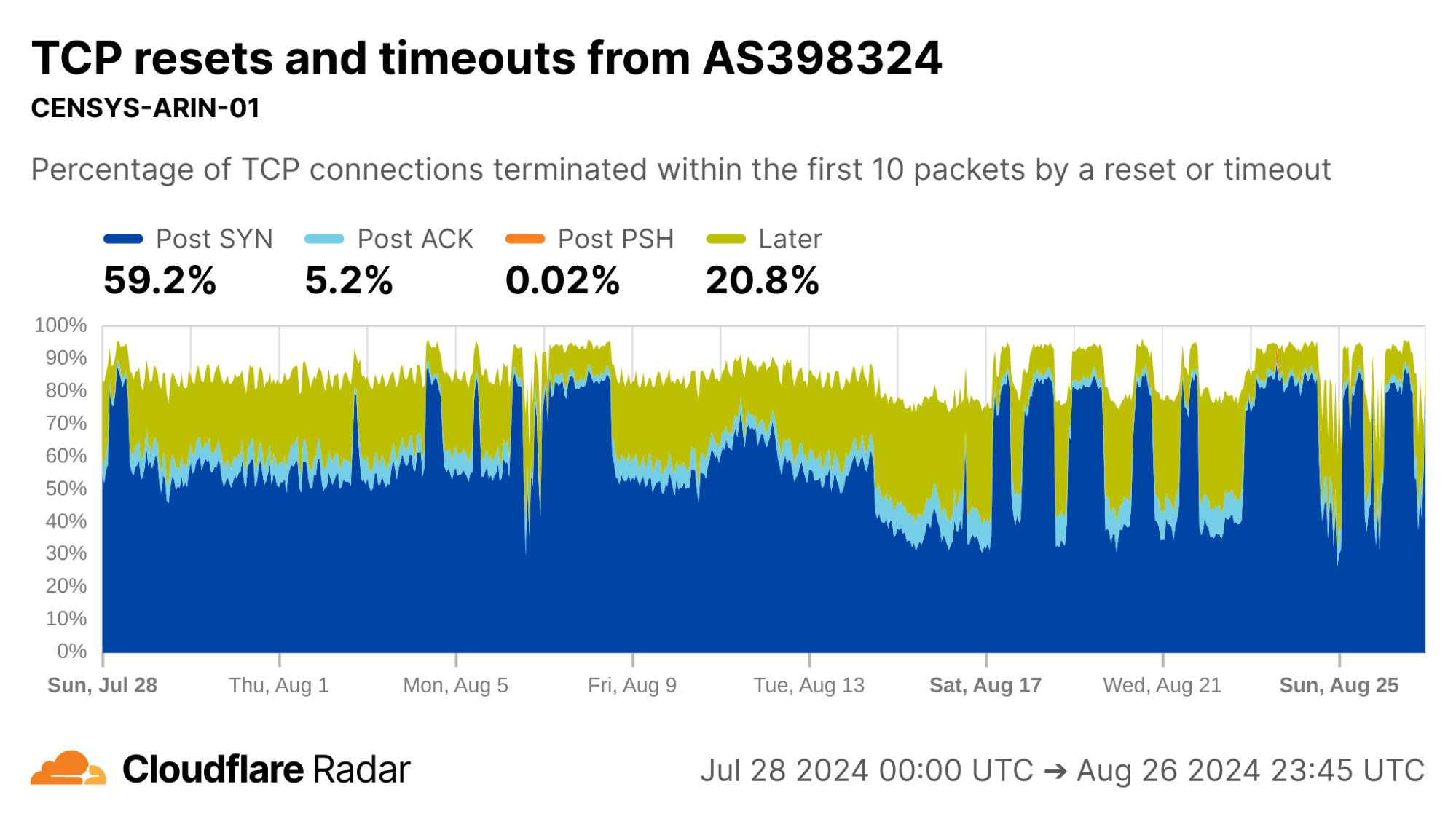
via Cloudflare Radar
Indeed, similar to AS15169, we classify over 99% of requests from AS398324 as automated.
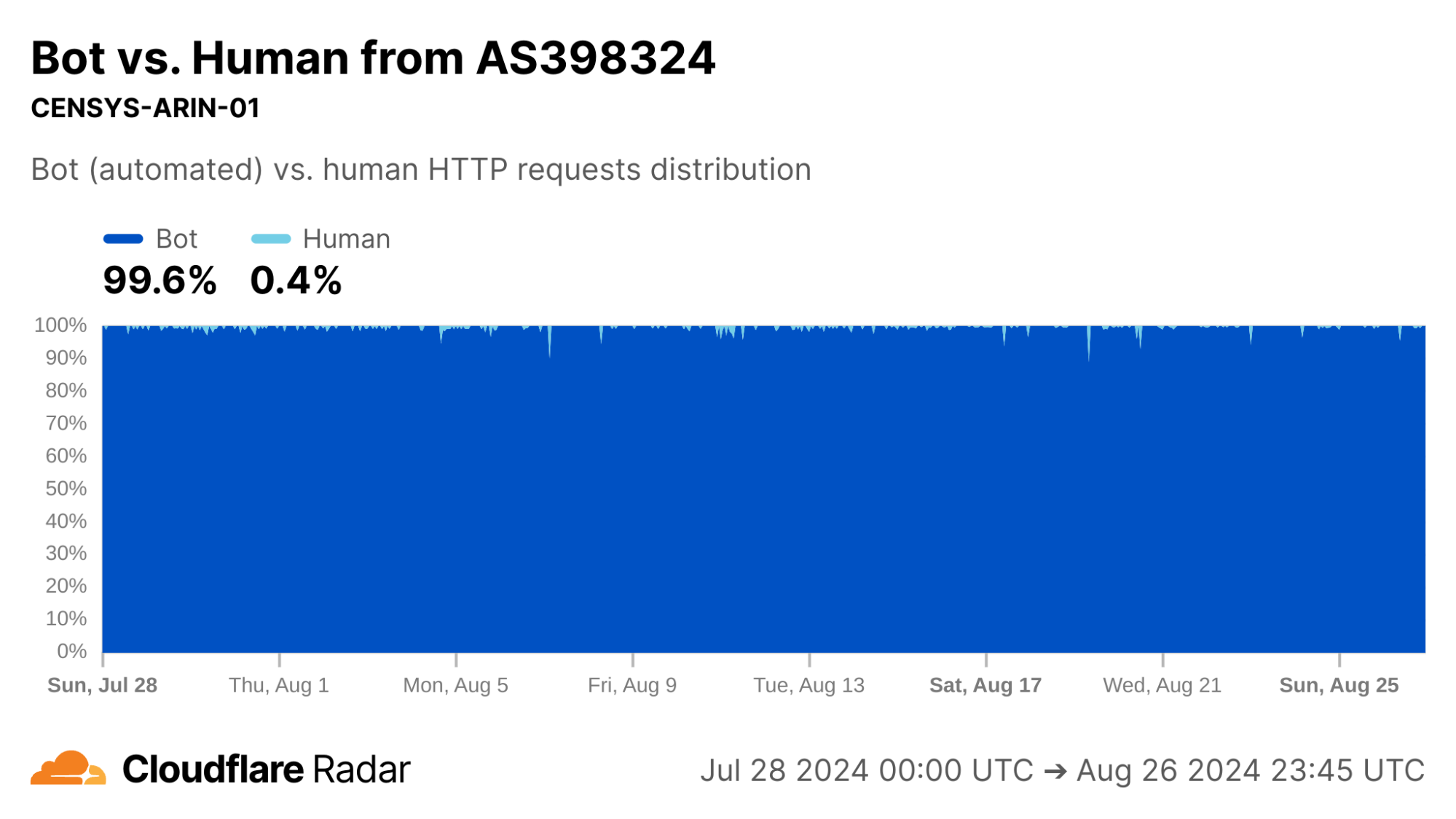
via Cloudflare Radar
So far, we’ve looked at networks that generate high volumes of scripted or automated traffic. It’s time to look further afield.
Corroborating connection tampering
The starting point of this dataset was a research project to understand and detect active connection tampering, in a similar spirit to our work on HTTPS interception. The reasons we set out to do are explained in detail in our accompanying blog post.
A well-documented technique in the wild to force connections to close is reset injection. With reset injection, middleboxes on the path to the destination inspect data portions of packets. When the middlebox sees a packet to a forbidden domain name, it injects forged TCP Reset (RST) packets to one or both communicating parties to cause them to abort the connection. If the middlebox did not drop the forbidden packet first, then the server will receive both the client packet that triggered the middlebox tampering – perhaps containing a TLS Client Hello message with a Server Name Indication (SNI) field – followed soon afterwards by the forged RST packet.
In the TCP resets and timeouts dataset, a connection disrupted via reset injection would typically appear as a Post-ACK, Post-PSH, or Later anomaly (but, as a reminder, not all anomalies are due to reset injection).
As an example, the reset injection technique is known and commonly associated with the so-called Great Firewall of China (GFW). Indeed, looking at Post-PSH anomalies in connections originating from IPs geolocated to China, we see higher rates than the worldwide average. However, looking at individual networks in China, the Post-PSH rates vary widely, perhaps due to the types of traffic carried or different implementations of the technique. In contrast, rates of Post-SYN anomalies are consistently high across most major Chinese ASes; this may be scanners, spoofed SYN flood attacks, or residual blocking with collateral impact.
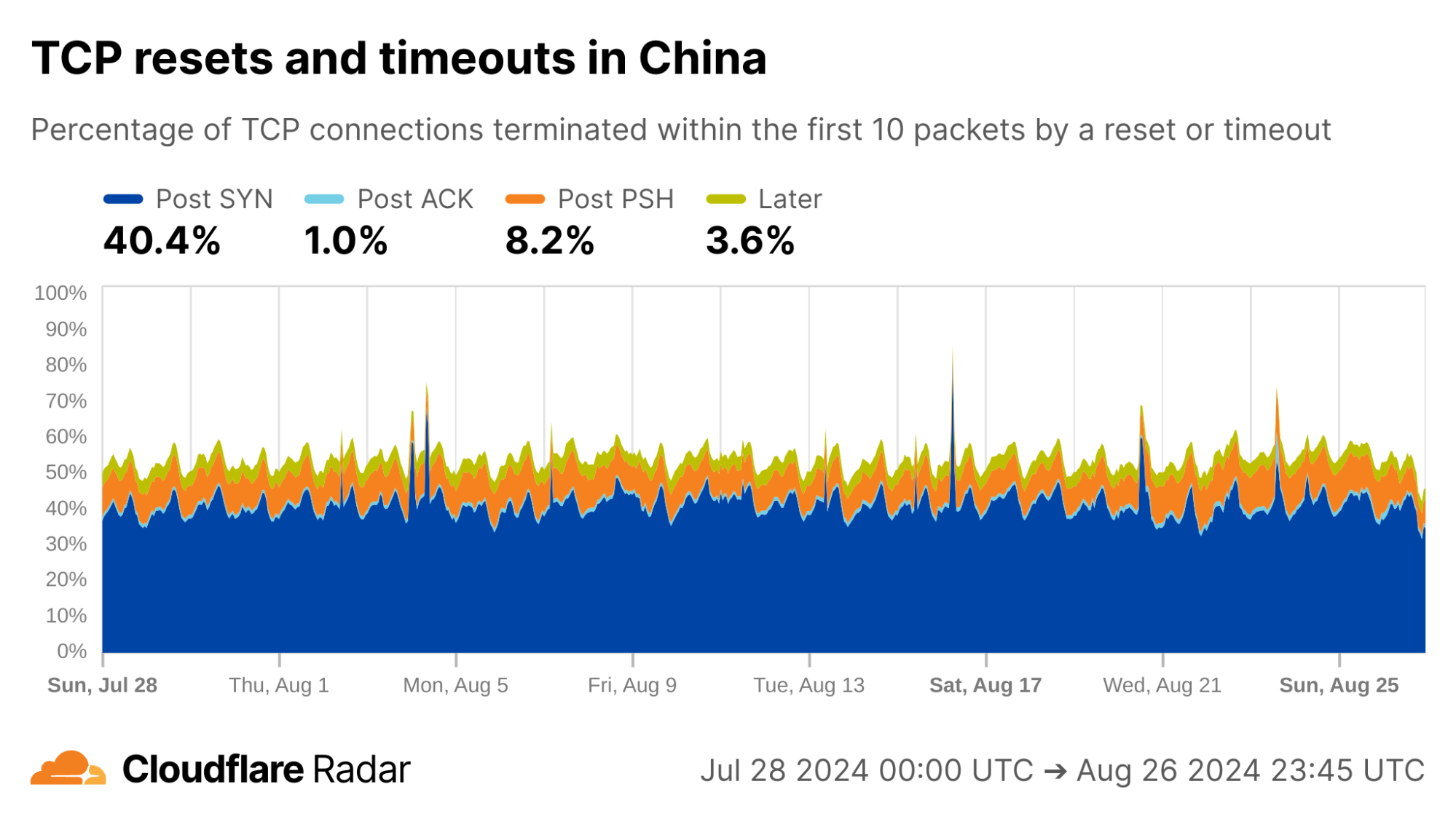
via Cloudflare Radar
AS4134 (CHINANET-BACKBONE) shows lower rates of Post-PSH anomalies than other Chinese ASes, but still well above the worldwide average.
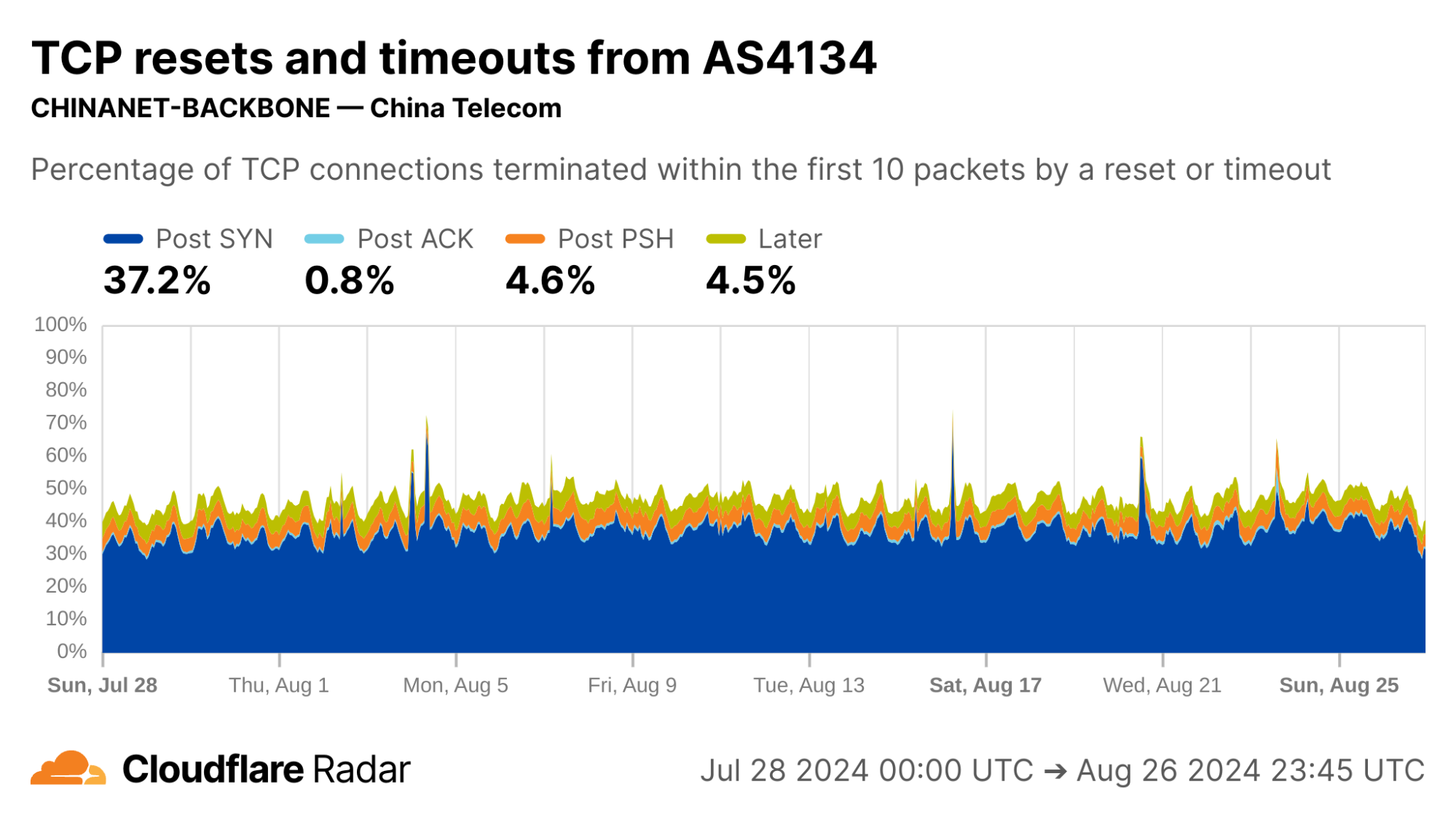
via Cloudflare Radar
Networks AS9808 (CHINAMOBILE-CN) and AS56046 (CMNET-Jiangsu-AP) both show double-digit percentages of connections matching Post-PSH anomalies.
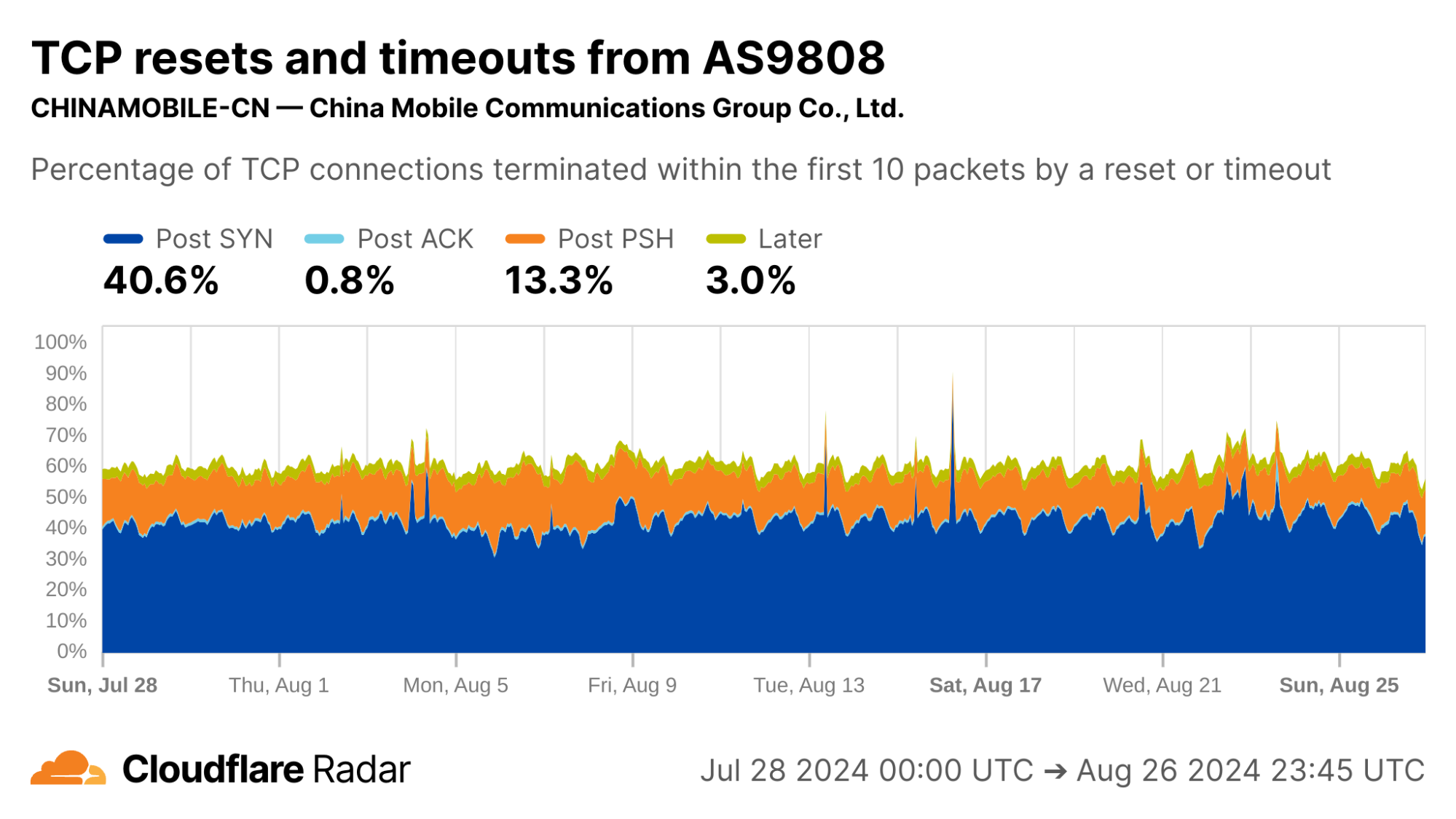
via Cloudflare Radar
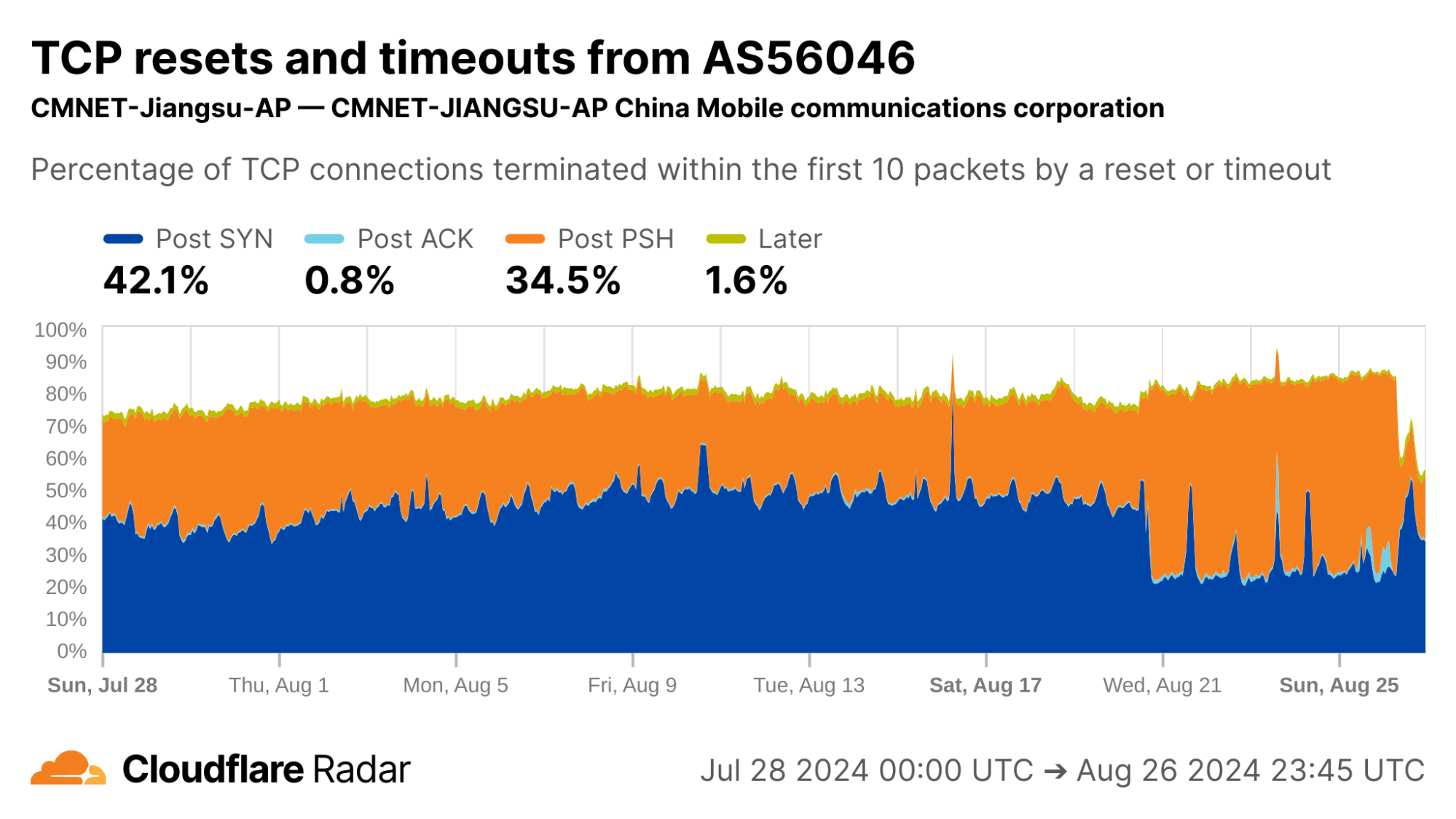
via Cloudflare Radar
See our deep-dive blog post for more information about connection tampering.
Sourcing new insights and targets for followup study
TCP resets and timeouts dataset may also be a source for identifying new or previously understudied network behaviors, by helping to find networks that “stick out” and merit further investigation.
Unattributable ZMap scanning
Here is one we’re unable to explain: Every day during the same 18-hour interval, over 10% of connections from UK clients never progress past the initial SYN packets, and just time out.
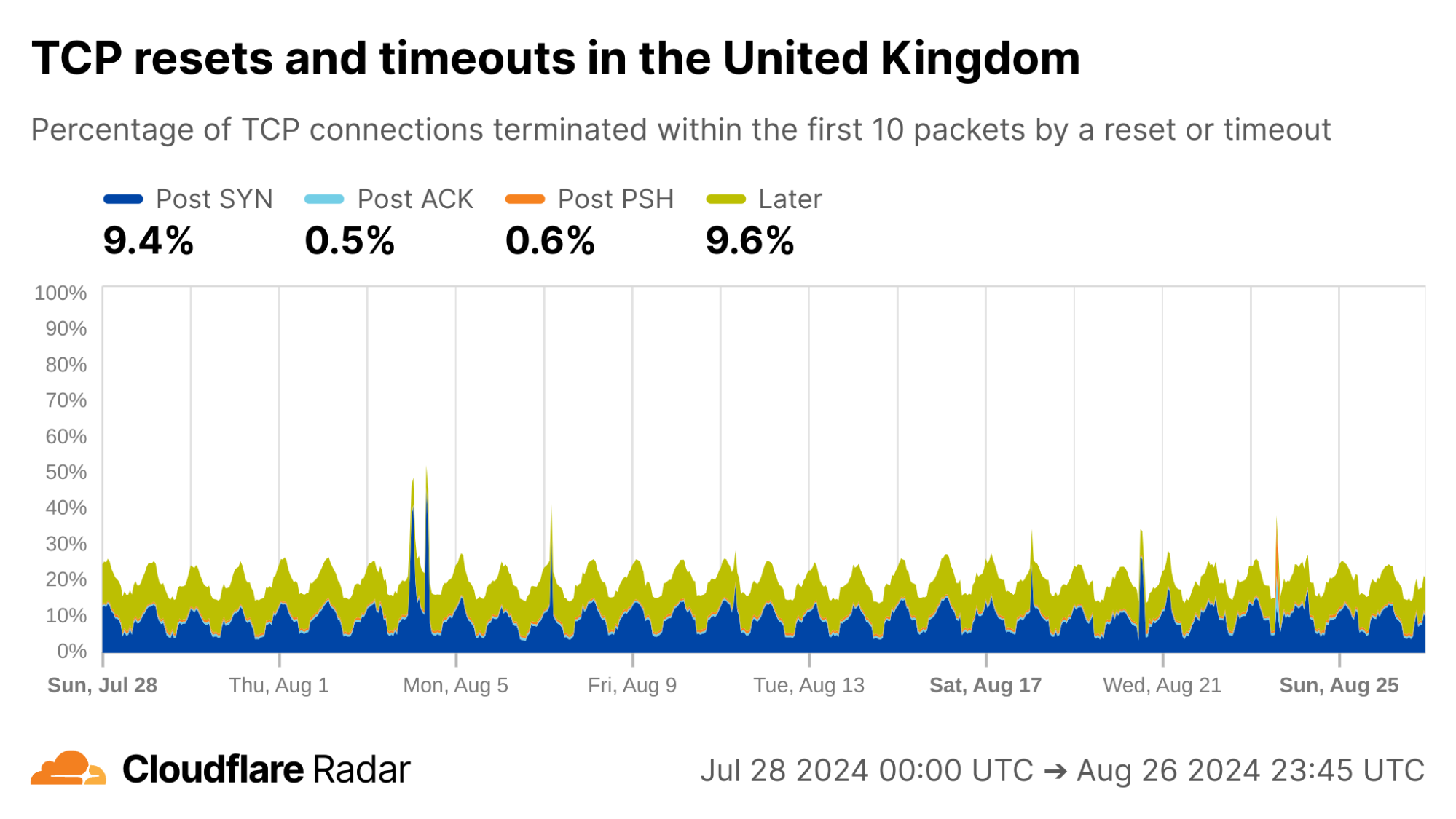
via Cloudflare Radar
Internal inspection revealed that almost all of the Post-SYN anomalies come from a scanner using ZMap at AS396982 (GOOGLE-CLOUD-PLATFORM), in what appears to be a full port scan across all IP address ranges. (The ZMap client responsibly self-identifies, based on ZMap’s responsible self-identification as discussed later.) We see a similar level of scan traffic from IP prefixes in AS396982 geolocated to the United States.
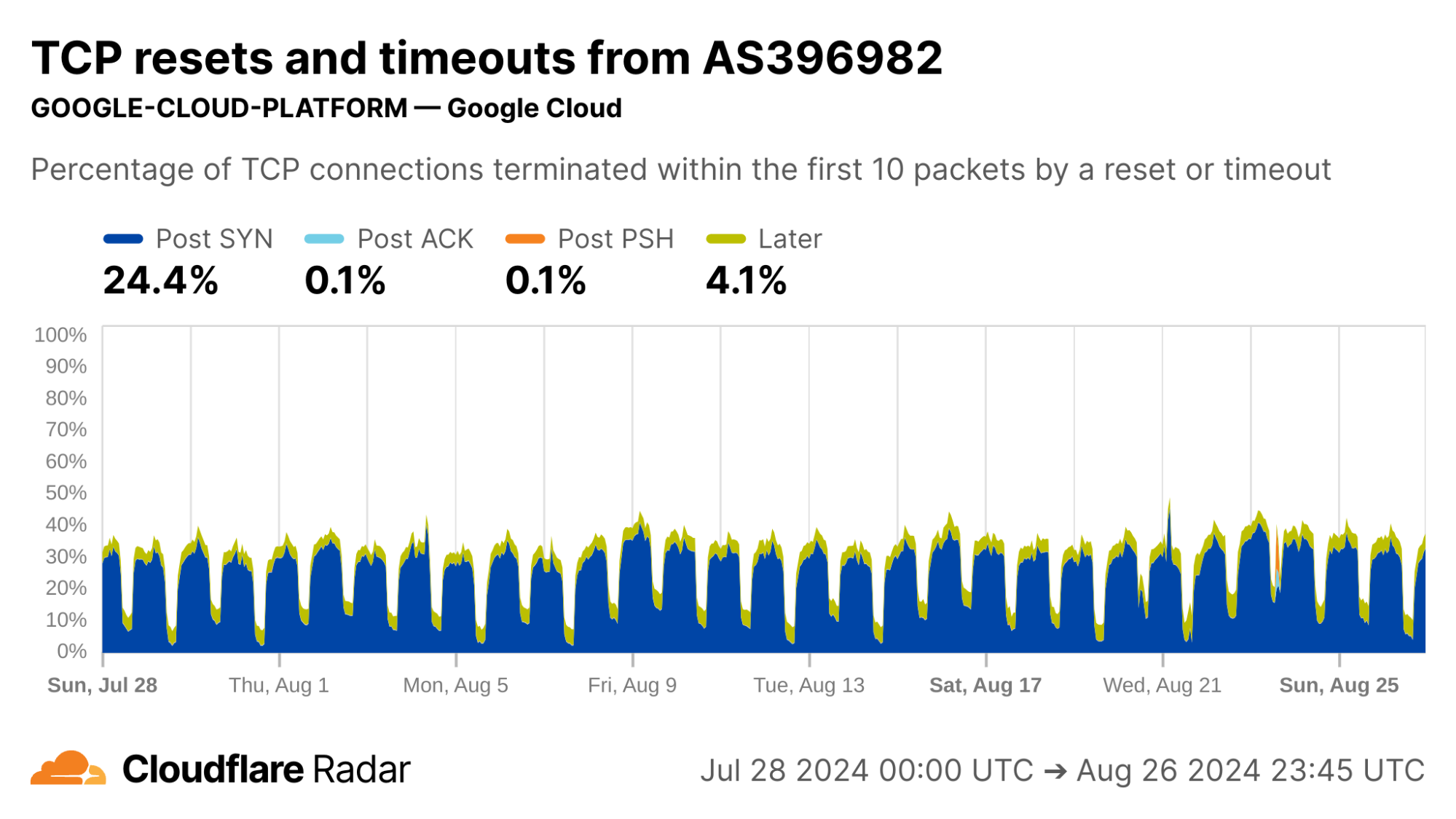
via Cloudflare Radar
Zero-rating in mobile networks
A cursory look at anomaly rates at the country level reveals some interesting findings. For instance, looking at connections from Mexico, the rates of Post-ACK and Post-PSH anomalies often associated with connection tampering are higher than the global average. The profile for Mexico connections is also similar to others in the region. However, Mexico is a country with “no documented evidence that the government or other actors block or filter internet content.”
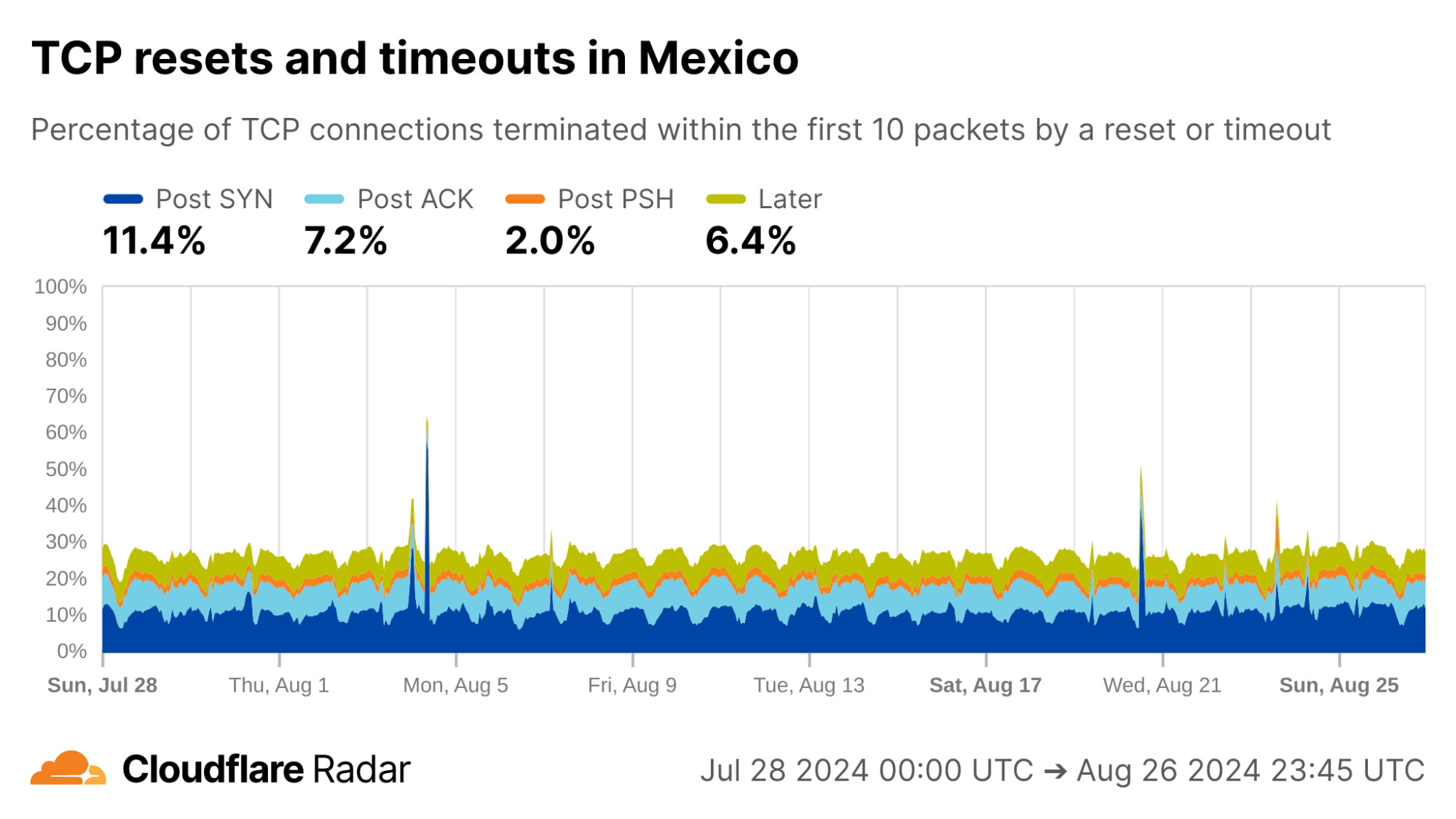
via Cloudflare Radar
Looking at each of the top ASes by HTTP traffic volume in Mexico, we find that close to 50% of connections from AS28403 (RadioMovil Dipsa, S.A. de C.V., operating as Telcel) are terminated via a reset or timeout directly after the completion of the TCP handshake (Post-ACK connection stage). In this stage, it’s possible a middlebox has seen and dropped a data packet before it gets to Cloudflare.
One explanation for this behavior may be zero-rating, in which a cellular network provider allows access to certain resources (such as messaging or social media apps) at no cost. When users exceed their data transfer limits on their account, the provider might still allow traffic to zero-rated destinations while blocking connections to other resources.
To enforce a zero-rating policy, an ISP might use the TLS Server Name Indication (SNI) to determine whether to block or allow connections. The SNI is sent in a data-containing packet immediately following the TCP handshake. Thus, if an ISP drops the packet containing the SNI, the server would still see the SYN and ACK packets from the client but no subsequent packets, which is consistent with a Post-ACK connection anomaly.
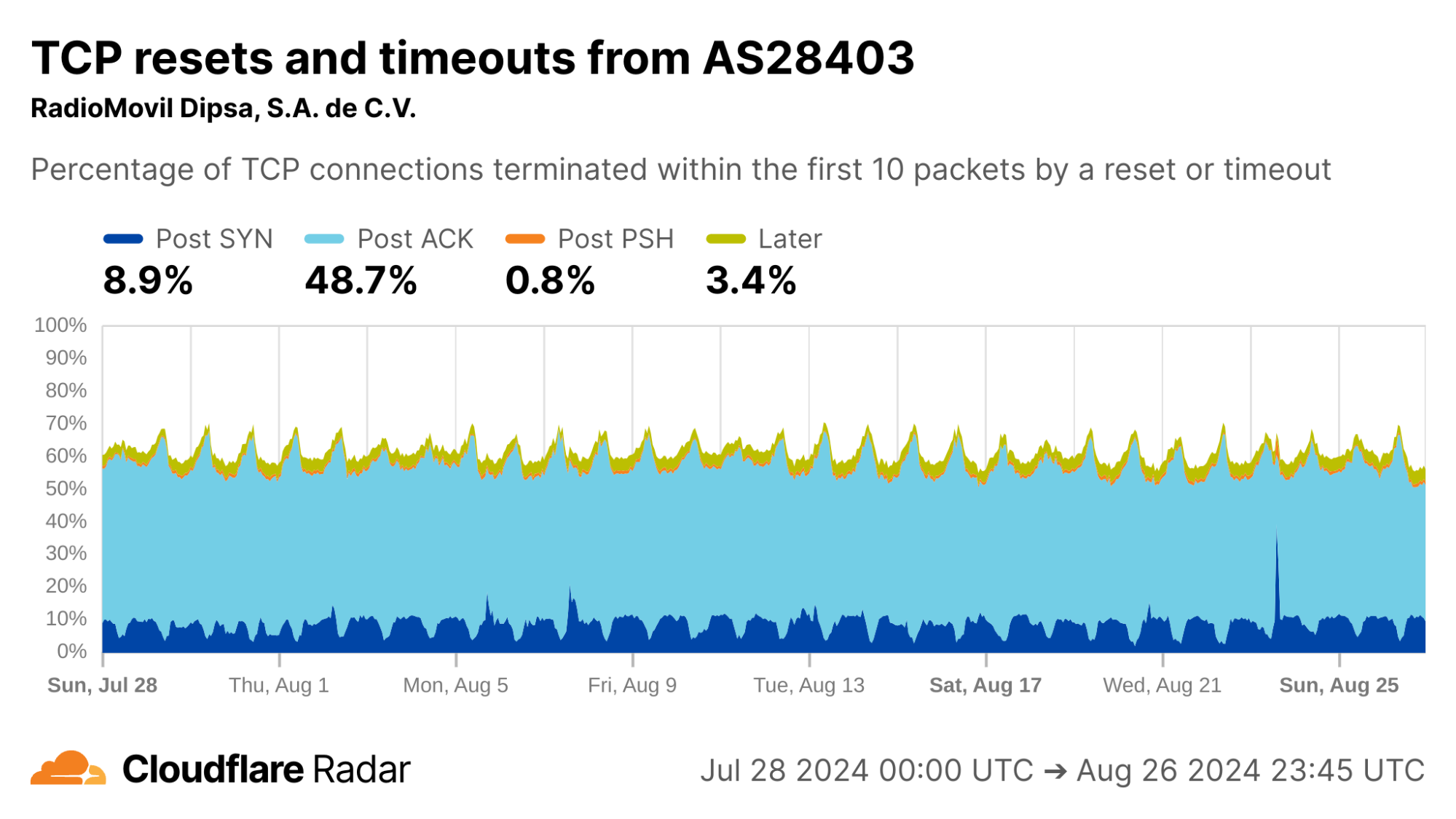
via Cloudflare Radar
Turning to Peru, another country with a similar profile in the dataset, there are even higher rates of Post-ACK and Post-PSH anomalies compared to Mexico.
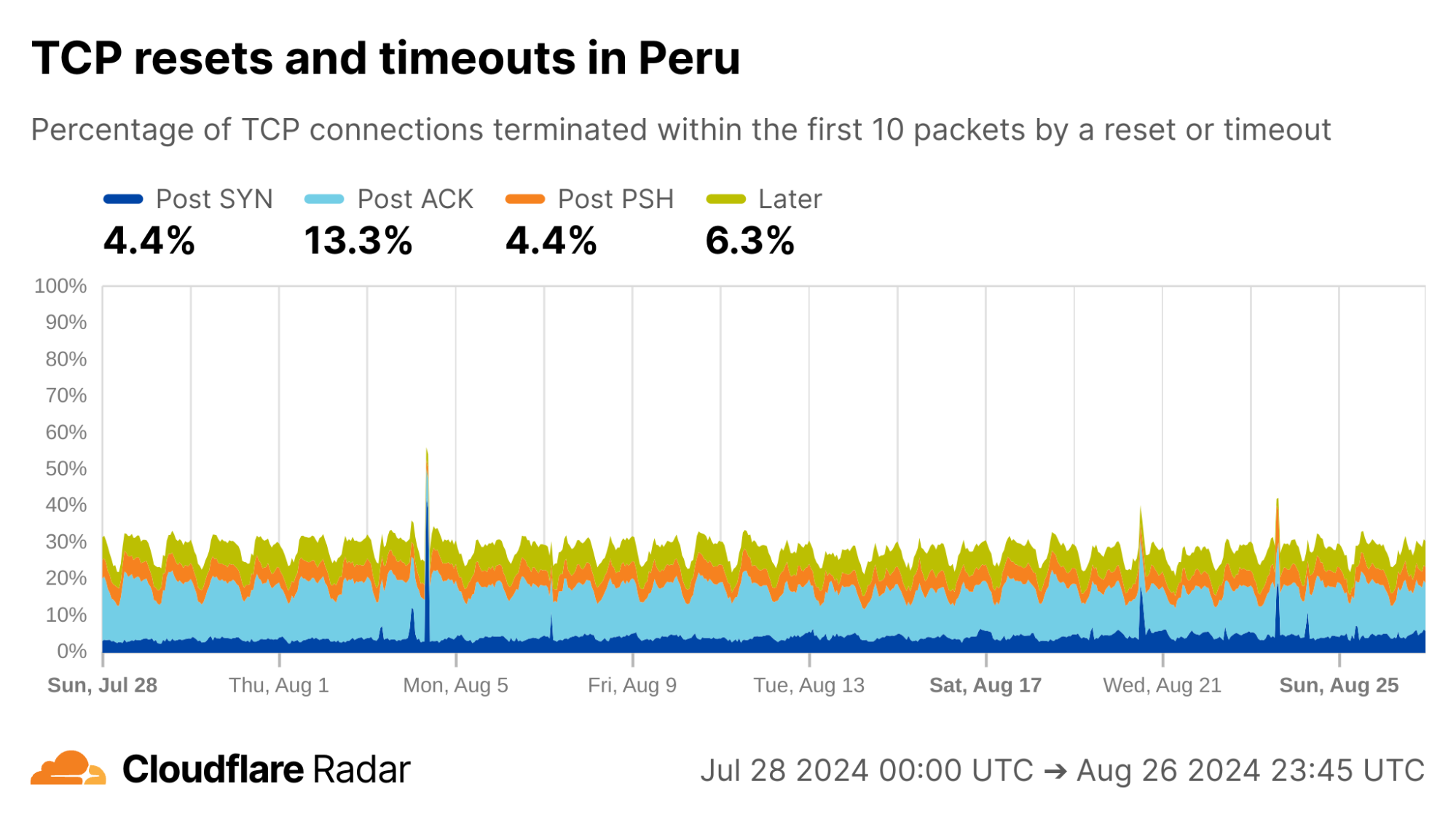
via Cloudflare Radar
Focusing on specific ASes, we see that AS12252 (Claro Peru) shows high rates of Post-ACK anomalies similar to AS28403 in Mexico. Both networks are operated by the same parent company, América Móvil, so one might expect similar network policies and network management techniques to be employed.
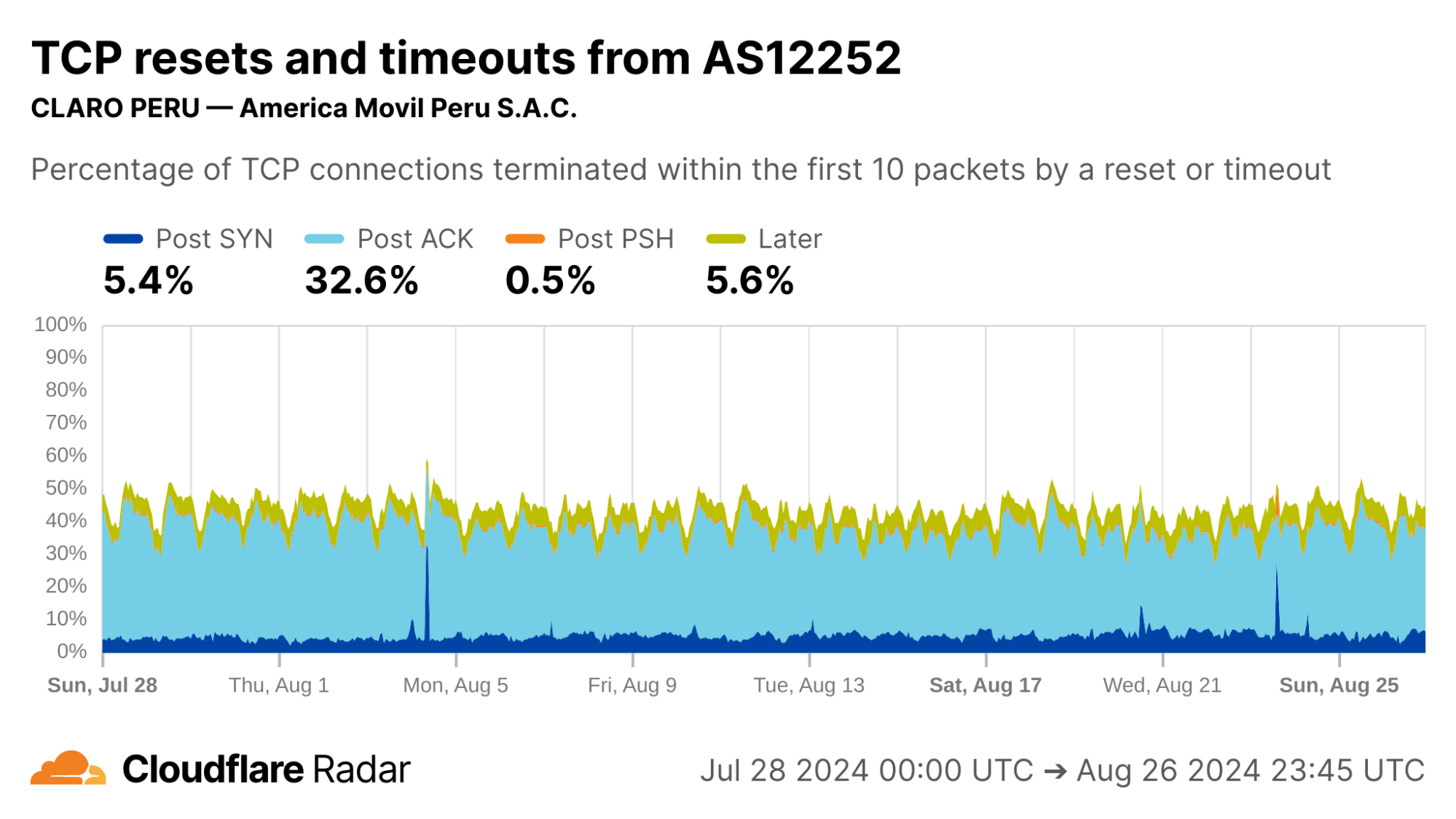
via Cloudflare Radar
Interestingly, AS6147 (Telefónica Del Perú) instead shows high rates of Post-PSH connection anomalies. This could indicate that this network uses different techniques at the network layer to enforce its policies.
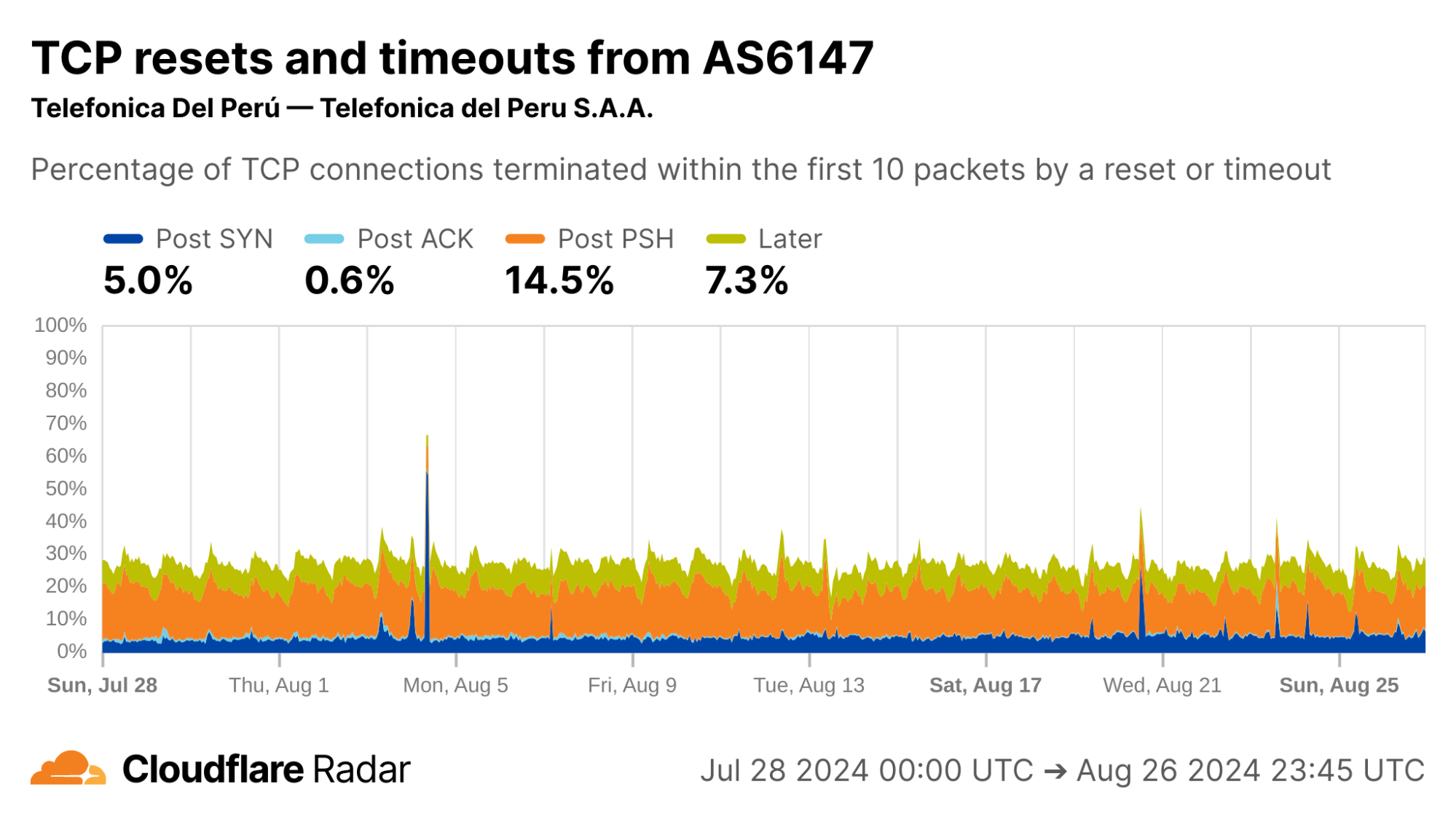
via Cloudflare Radar
Changes over time, a longitudinal view
One of the most powerful aspects of our continuous passive measurement is the ability to measure networks over longer periods of time.
Internet shutdowns
In our June 2024 blog post “Examining recent Internet shutdowns in Syria, Iraq, and Algeria”, we shared the view of exam-related nationwide Internet shutdowns from the perspective of Cloudflare’s network. At that time we were preparing the TCP resets and timeouts dataset, which was helpful to confirm outside reports and get some insight into the specific techniques used for the shutdowns.
As examples of changing behavior, we can go “back in time” to observe exam-related blocking as it happened. In Syria, during the exam-related shutdowns we see spikes in the rate of Post-SYN anomalies. In reality, we see a near-total drop in traffic (including SYN packets) during these periods.
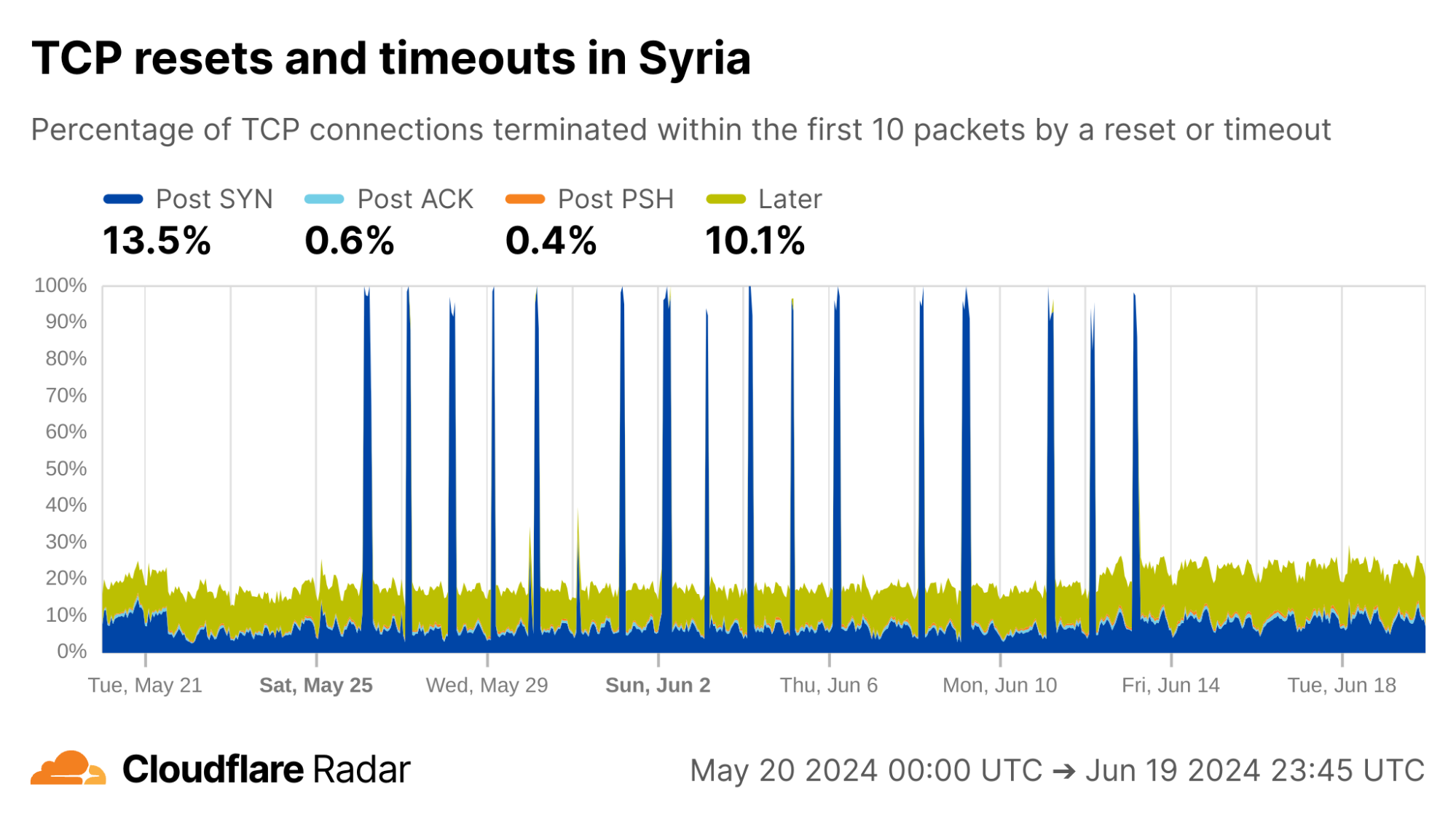
via Cloudflare Radar
A second round of shutdowns starting the last week of July are quite prominent as well.
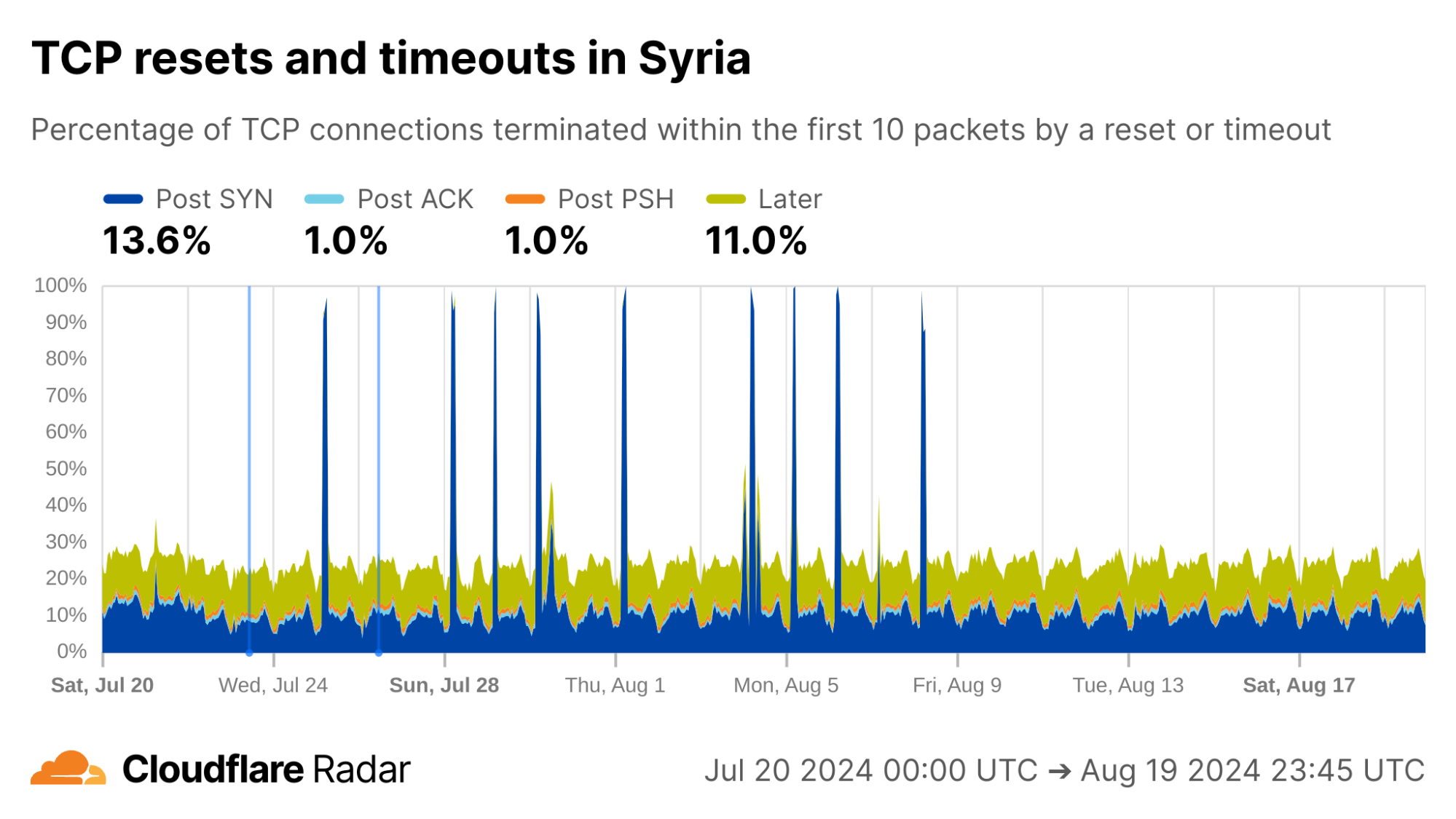
via Cloudflare Radar
Looking at connections from Iraq, Cloudflare’s view of exam-related shutdowns appears similar to those in Syria, with multiple Post-SYN spikes, albeit much less pronounced.
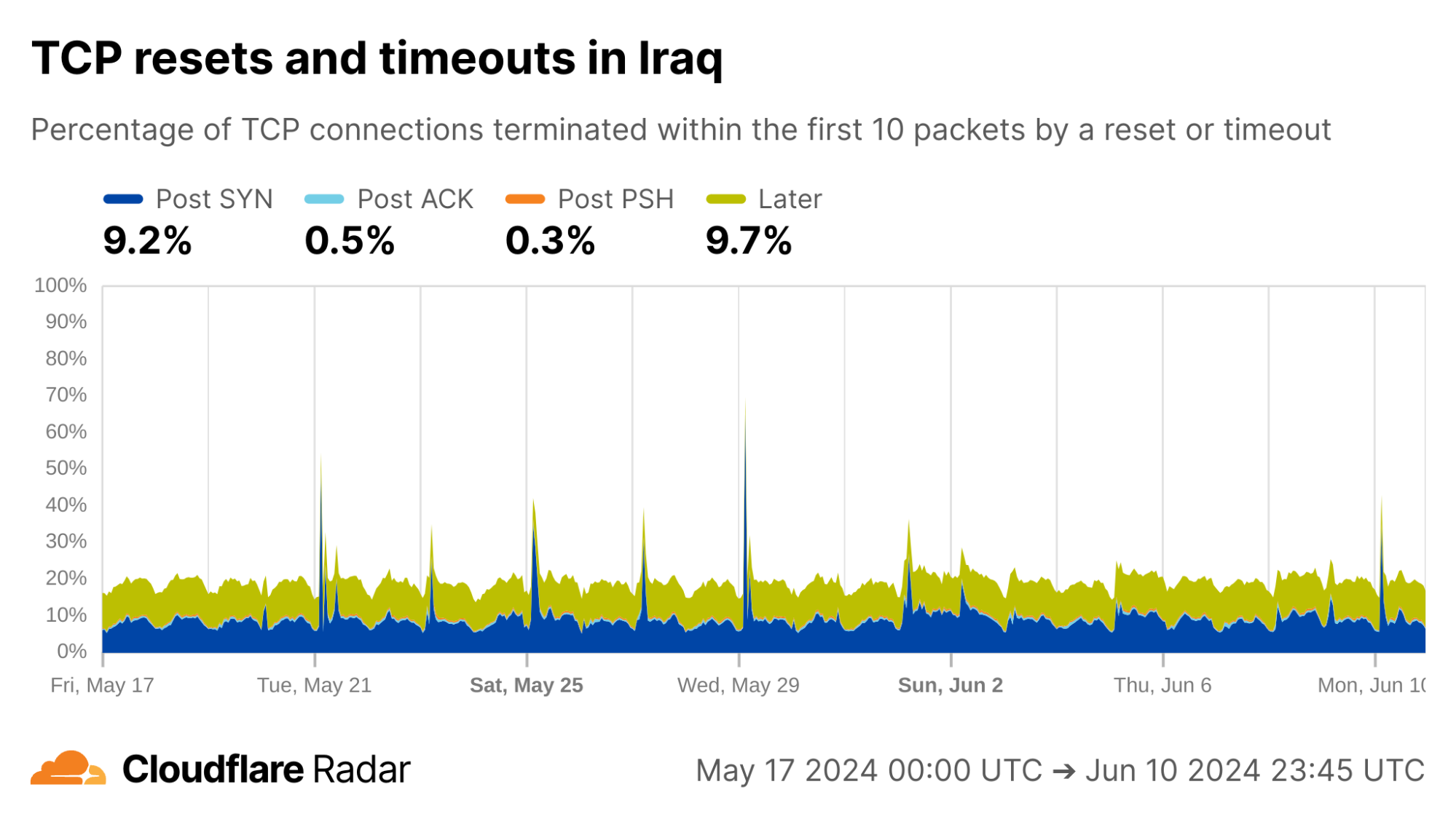
via Cloudflare Radar
The exams shutdown blog also describes how Algeria took a more nuanced approach for restricting access to content during exam times: instead of full Internet shutdowns, evidence suggests that Algeria instead targeted specific connections. Indeed, during exam periods we see an increase in Post-ACK connection anomalies. This behavior would be expected if a middlebox selectively drops packets that contain forbidden content, while leaving other packets alone (like the initial SYN and ACK).
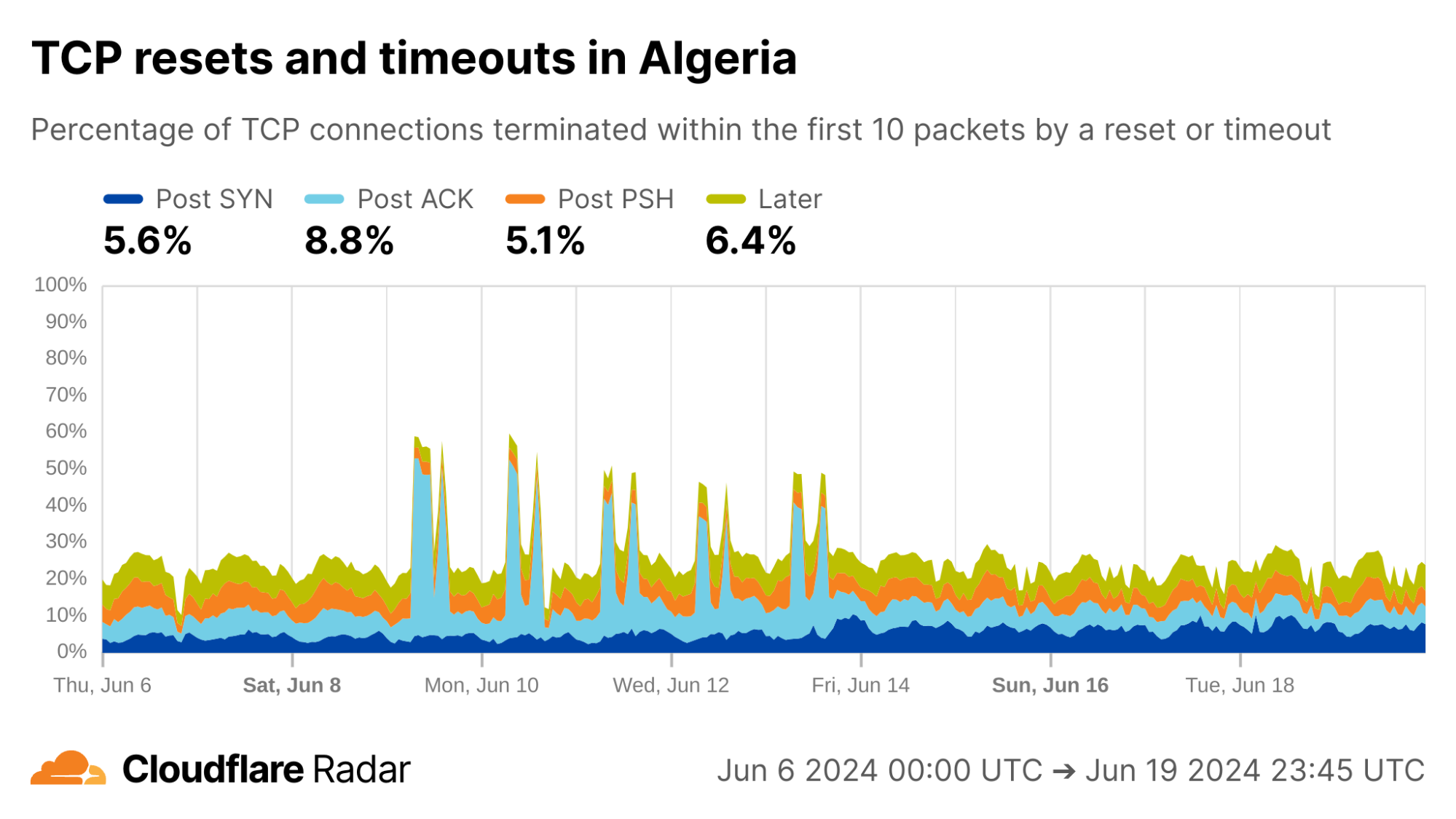
via Cloudflare Radar
The examples above reinforce that this data is most useful when correlated with other signals. The data is also available via the API, so others can dive in more deeply. Our detection techniques are also transferable to other servers and operators, as described next.
How to detect anomalous TCP connections at scale
In this section, we discuss how we constructed the TCP resets and timeouts dataset. The scale of Cloudflare’s global network presents unique challenges for data processing and analysis. We share our techniques to help readers to understand our methodology, interpret the dataset, and replicate the mechanisms in other networks or servers.
Our methodology can be summarized as follows:
Log a sample of connections arriving at our client-facing servers. This sampling system is completely passive, meaning that it has no ability to decrypt traffic and only has access to existing packets sent over the network.
Reconstruct connections from the captured packets. A novel aspect of our design is that only one direction needs to be observed, from client to server.
Match reconstructed connections against a set of signatures for anomalous connections terminated by resets or timeouts. These signatures consist of two parts: a connection stage, and a set of tags that indicate specific behaviors derived from the literature and our own observations.
These design choices keep encrypted packets safe and can be replicated anywhere, without needing access to the destination server.
First, sample connections
Our main goal was to design a mechanism that scales, and gives us broad visibility into all connections arriving at Cloudflare’s network. Running traffic captures on each client-facing server works, but does not scale. We would also need to know exactly where and when to look, making continuous insights hard to capture. Instead, we sample connections from all of Cloudflare’s servers and log them to a central location where we could perform offline analysis.
This is where we hit the first roadblock: existing packet logging pipelines used by Cloudflare’s analytics systems log individual packets, but a connection consists of many packets. To detect connection anomalies we needed to see all, or at least enough, packets in a given connection. Fortunately, we were able to leverage a flexible logging system built by Cloudflare’s DoS team for analyzing packets involved in DDoS attacks in conjunction with a carefully crafted invocation of two iptables rules to achieve our goal.
The first iptables rule randomly selects and marks new connections for sampling. In our case, we settled on sampling one in every 10,000 ingress TCP connections. There’s nothing magical about this number, but at Cloudflare’s scale it strikes a balance between capturing enough without straining our data processing and analytics pipelines. The iptables rules only apply to packets after they have passed the DDoS mitigation system. As TCP connections can be long-lived, we sample only new TCP connections. Here is the iptables rule for marking connections to be sampled:
-t mangle -A PREROUTING -p tcp --syn -m state
--state NEW -m statistic --mode random
--probability 0.0001 -m connlabel --label
--set -m comment --comment "Label a sample of ingress TCP connections"
Breaking this down, the rule is installed in the mangle table (for modifying packets) in the chain that handles incoming packets (-A PREROUTING). Only TCP packets with the SYN flag set are considered (-p tcp --syn) where there is no prior state for the connection (--state NEW). The filter selects one in every 10,000 SYN packets (-m statistic –mode random --probability 0.0001) and applies a label to the connection (-m connlabel --label --set).
The second iptables rule logs subsequent packets in the connection, to a maximum of 10 packets. Again, there’s nothing magic about the number 10 other than that it’s generally enough to capture the connection establishment, subsequent request packets, and resets on connections that close before expected.
-t mangle -A PREROUTING -m connlabel --label
-m connbytes ! --connbytes 11
--connbytes-dir original --connbytes-mode packets
-j NFLOG --nflog-prefix "" -m
comment --comment "Log the first 10 incoming packets of each sampled ingress connection"
This rule is installed in the same chain as the previous rule. It matches only packets from sampled connections (-m connlabel --label ), and only the first 10 packets from each connection (-m connbytes ! --connbytes 11 --connbytes-dir original --connbytes-mode packets). Matched packets are sent to NFLOG (-j NFLOG --nflog-prefix "") where they’re picked up by the logging system and saved to a centralized location for offline analysis.
Reconstructing connections from sampled packets
Packets logged on our servers are inserted into ClickHouse tables as part of our analytics pipeline. Each logged packet is stored in its own row in the database. The next challenge is to reassemble packets into the corresponding connections for further analysis. Before we go further, we need to define what a “connection” is for the purpose of this analysis.
We use the standard definition of a connection defined by the network 5-tuple of protocol, source IP address, source port, destination IP address, destination port with the following tweaks:
We only sample packets on the ingress (client-to-server) half of a connection, so do not see the corresponding response packets from server to client. In most cases, we can infer what the server response will be based on our knowledge of how our servers are configured. Ultimately, the ingress packets are sufficient to learn anomalous TCP connection behaviors.
We query the ClickHouse dataset in 15-minute intervals, and group together packets sharing the same network 5-tuple within that interval. This means that connections may be truncated towards the end of the query interval. When analyzing connection timeouts, we exclude incomplete flows where the latest packet timestamp is within 10 seconds of the query cutoff.
Since resets and timeouts are most likely to affect new connections, we only consider sequences of packets starting with a SYN packet marking the beginning of a new TCP handshake. Thus, existing long-lived connections are excluded.
The logging system does not guarantee precise packet interarrival timestamps, so we consider only the set of packets that arrive, not ordered by their arrival time. In some cases, we can determine packet ordering based on TCP sequence numbers but it turns out not to significantly impact the results.
We filter out a small fraction of connections with multiple SYN packets to reduce noise in the analysis.
With the above conditions for how we define a connection, we’re now ready to describe our analysis pipeline in more detail.
Mapping connection close events to stages
TCP connections transition through a series of stages from connection establishment through eventual close. The stage at which an anomalous connection closes provides clues as to why the anomaly occurred. Based on the packets that we receive at our servers, we place each incoming connection into one of four stages (Post-SYN, Post-ACK, Post-PSH, Later), described in more detail above.
The connection close stage alone provides useful insights into anomalous TCP connections from various networks, and this is what is shown today on Cloudflare Radar. However, in some cases we can provide deeper insights by matching connections against more specific signatures.
Applying tags to describe more specific connection behaviors
The grouping of connections into stages as described above is done solely based on the TCP flags of packets in the connection. Considering other factors such as packet inter-arrival timing, exact combinations of TCP flags, and other packet fields (IP identification, IP TTL, TCP sequence and acknowledgement numbers, TCP window size, etc.) can allow for more fine-grained matching to specific behaviors.
For example, the popular ZMap scanner software fixes the IP identification field to 54321 and the TCP window size to 65535 in SYN packets that it generates (source code). When we see packets arriving to our network that have these exact fields set, it is likely that the packet was generated by a scanner using ZMap.
Tags can also be used to match connections against known signatures of tampering middleboxes. A large body of active measurements work (for instance, Weaver, Sommer, and Paxson) has found that some middleboxes deployments exhibit consistent behaviors when disrupting connections via reset injection, such as setting an IP TTL field that differs from other packets sent by the client, or sending both a RST packet and a RST+ACK packet. For more details on specific connection tampering signatures, see the blog post and the peer-reviewed paper.
Currently, we define the following tags, which we intend to refine and expand over time. Some tags only apply if another tag is also set, as indicated by the hierarchical presentation below (e.g., the fin tag can only apply when the reset tag is also set).
timeout: terminated due to a timeoutreset: terminated due to a reset (packet with RST flag set)fin: at least one FIN packet was received alongside one or more RST packets
single_rst: terminated with a single RST packetmultiple_rsts: terminated with multiple RST packetsacknumsame: the acknowledgement numbers in the RST packets were all the same and non-zeroacknumsame0: the acknowledgement numbers in the RST packets were all zeroacknumdiff: the acknowledgement numbers in the RST packets were different and all non-zeroacknumdiff0: the acknowledgement numbers in the RST packets were different and one was zero
single_rstack: terminated with a single RST+ACK packet (both RST and ACK flags set)multiple_rstacks: terminated with a multiple RST+ACK packetsrst_and_rstacks: terminated with a combination of RST and RST+ACK packets
zmap: SYN packet matches those generated by the ZMap scanner
Connection tags are not currently visible in the Radar dashboard and API, but we plan to release this additional functionality in the future.
What’s next?
Cloudflare’s mission is to help build a better Internet, and we consider transparency and accountability to be a critical part of that mission. We hope that the insights and tools we are sharing help to shed light on anomalous network behaviors around the world.
While the current TCP resets and timeouts dataset should immediately prove useful to network operators, researchers, and Internet citizens as a whole, we’re not stopping here. There are several improvements we’d like to add in the future:
Expand the set of tags for capturing specific network behaviors and expose them in the API and dashboard.
Extend insights to connections from Cloudflare to customer origin servers.
Add support for QUIC, which is currently used for over 30% of HTTP requests to Cloudflare worldwide.
If you’ve found this blog interesting, we encourage you to read the accompanying blog post and paper for a deep dive on connection tampering, and to explore the TCP resets and timeouts dashboard and API on Cloudflare Radar. We welcome you to reach out to us with your own questions and observations at radar@cloudflare.com.
Source:: CloudFlare