
Hyperdrive (Cloudflare’s globally distributed SQL connection pooler and cache) recently added support for Postgres protocol-level named prepared statements across pooled connections. Named prepared statements allow Postgres to cache query execution plans, providing potentially substantial performance improvements. Further, many popular drivers in the ecosystem use these by default, meaning that not having them is a bit of a footgun for developers. We are very excited that Hyperdrive’s users will now have access to better performance and a more seamless development experience, without needing to make any significant changes to their applications!
While we’re not the first connection pooler to add this support (PgBouncer got to it in October 2023 in version 1.21, for example), there were some unique challenges in how we implemented it. To that end, we wanted to do a deep dive on what it took for us to deliver this.
Hyper-what?
One of the classic problems of building on the web is that your users are everywhere, but your database tends to be in one spot. Combine that with pesky limitations like network routing, or the speed of light, and you can often run into situations where your users feel the pain of having your database so far away. This can look like slower queries, slower startup times, and connection exhaustion as everything takes longer to accomplish.
Hyperdrive is designed to make the centralized databases you already have feel like they’re global. We use our global network to get faster routes to your database, keep connection pools primed, and cache your most frequently run queries as close to users as possible.
Postgres Message Protocol
To understand exactly what the challenge with prepared statements is, it’s first necessary to dig in a bit to the Postgres Message Protocol. Specifically, we are going to take a look at the protocol for an “extended” query, which uses different message types and is a bit more complex than a “simple” query, but which is more powerful and thus more widely used.
A query using Hyperdrive might be coded something like this, but a lot goes on under the hood in order for Postgres to reliably return your response.
import postgres from "postgres";
// with Hyperdrive, we don't have to disable prepared statements anymore!
// const sql = postgres(env.HYPERDRIVE.connectionString, {prepare: false});
// make a connection, with the default postgres.js settings (prepare is set to true)
const sql = postgres(env.HYPERDRIVE.connectionString);
// This sends the query, and while it looks like a single action it contains several
// messages implied within it
let [{ a, b, c, id }] = await sql`SELECT a, b, c, id FROM hyper_test WHERE id = ${target_id}`;
To prepare a statement, a Postgres client begins by sending a Parse message. This includes the query string, the number of parameters to be interpolated, and the statement’s name. The name is a key piece of this puzzle. If it is empty, then Postgres uses a special “unnamed” prepared statement slot that gets overwritten on each new Parse. These are relatively easy to support, as most drivers will keep the entirety of a message sequence for unnamed statements together, and will not try to get too aggressive about reusing the prepared statement because it is overwritten so often.
If the statement has a name, however, then it is kept prepared for the remainder of the Postgres session (unless it is explicitly removed with DEALLOCATE). This is convenient because parsing a query string and preparing the statement costs bytes sent on the wire and CPU cycles to process, so reusing a statement is quite a nice optimization.
Once done with Parse, there are a few remaining steps to (the simplest form of) an extended query:
- A Bind message, which provides the specific values to be passed for the parameters in the statement (if any).
- An Execute message, which tells the Postgres server to actually perform the data retrieval and processing.
- And finally a Sync message, which causes the server to close the implicit transaction, return results, and provides a synchronization point for error handling.
While that is the core pattern for accomplishing an extended protocol query, there are many more complexities possible (named Portal, ErrorResponse, etc.).
We will briefly mention one other complexity we often encounter in this protocol, which is Describe messages. Many drivers leverage Postgres’ built-in types to help with deserialization of the results into structs or classes. This is accomplished by sending a Parse-Describe-Flush/Sync sequence, which will send a statement to be prepared, and will expect back information about the types and data the query will return. This complicates bookkeeping around named prepared statements, as now there are two separate queries, with two separate kinds of responses, that must be kept track of. We won’t go into much depth on the tradeoffs of an additional round-trip in exchange for advanced information about the results’ format, but suffice it to say that it must be handled explicitly in order for the overall system to gracefully support prepared statements.
So the basic query from our code above looks like this from a message perspective:
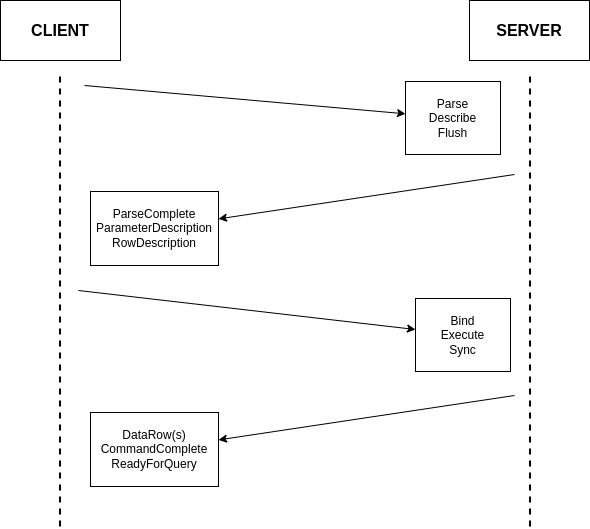
A more complete description and the full structure of each message type are well described in the Postgres documentation.
So, what’s so hard about that?
Buffering Messages
The first challenge that Hyperdrive must solve (that many other connection poolers don’t have) is that it’s also a cache.
The happiest path for a query on Hyperdrive never travels far, and we are quite proud of the low latency of our cache hits. However, this presents a particular challenge in the case of an extended protocol query. A Parse by itself is insufficient as a cache key, both because the parameter values in the Bind messages can alter the expected results, and because it might be followed up with either a Describe or an Execute message which will invoke drastically different responses.
So Hyperdrive cannot simply pass each message to the origin database, as we must buffer them in a message log until we have enough information to reliably distinguish between cache keys. It turns out that receiving a Sync is quite a natural point at which to check whether you have enough information to serve a response. For most scenarios, we buffer until we receive a Sync, and then (assuming the scenario is cacheable) we determine whether we can serve the response from cache or we need to take a connection to the origin database.
Taking a Connection From the Pool
Assuming we aren’t serving a response from cache, for whatever reason, we’ll need to take an origin connection from our pool. One of the key advantages any connection pooler offers is in allowing many client connections to share few database connections, so minimizing how often and for how long these connections are held is crucial to making Hyperdrive performant.
To this end, Hyperdrive operates in what is traditionally called “transaction mode”. This means that a connection taken from the pool for any given transaction is returned once that transaction concludes. This is in contrast to what is often called “session mode”, where once a connection is taken from the pool it is held by the client until the client disconnects.
For Hyperdrive, allowing any client to take any database connection is vital. This is because if we “pin” a client to a given database connection then we have one fewer available for every other possible client. You can run yourself out of database connections very quickly once you start down that path, especially when your clients are many small Workers spread around the world.
The challenge prepared statements present to this scenario is that they exist at the “session” scope, which is to say, at the scope of one connection. If a client prepares a statement on connection A, but tries to reuse it and gets assigned connection B, Postgres will naturally throw an error claiming the statement doesn’t exist in the given session. No results will be returned, the client is unhappy, and all that’s left is to retry with a Parse message included. This causes extra round-trips between client and server, defeating the whole purpose of what is meant to be an optimization.
One of the goals of a connection pooler is to be as transparent to the client and server as possible. There are limitations, as Postgres will let you do some powerful things to session state that cannot be reasonably shared across arbitrary client connections, but to the extent possible the endpoints should not have to know or care about any multiplexing happening between them.
This means that when a client sends a Parse message on its connection, it should expect that the statement will be available for reuse when it wants to send a Bind-Execute-Sync sequence later on. It also means that the server should not get Bind messages for statements that only exist on some other session. Maintaining this illusion is the crux of providing support for this feature.
Putting it all together
So, what does the solution look like? If a client sends Parse-Bind-Execute-Sync with a named prepared statement, then later sends Bind-Execute-Sync to reuse it, how can we make sure that everything happens as expected? The solution, it turns out, needs just a few built-in Rust data structures for efficiently capturing what we need (a HashMap, some LruCaches and a VecDeque), and some straightforward business logic to keep track of when to intervene in the messages being passed back and forth.
Whenever a named Parse comes in, we store it in an in-memory HashMap on the server that handles message processing for that client’s connection. This persists until the client is disconnected. This means that whenever we see anything referencing the statement, we can go retrieve the complete message defining it. We’ll come back to this in a moment.
Once we’ve buffered all the messages we can and gotten to the point where it’s time to return results (let’s say because the client sent a Sync), we need to start applying some logic. For the sake of brevity we’re going to omit talking through error handling here, as it does add some significant complexity but is somewhat out of scope for this discussion.
There are two main questions that determine how we should proceed:
This gives us four scenarios to consider:
A Parse with a cache hit is the easiest path to address, as we don’t need to do anything special. We use the messages sent as a cache key, and serve the results back to the client. We will still keep the Parse in our HashMap in case we want it later (#2 below), but otherwise we’re good to go.
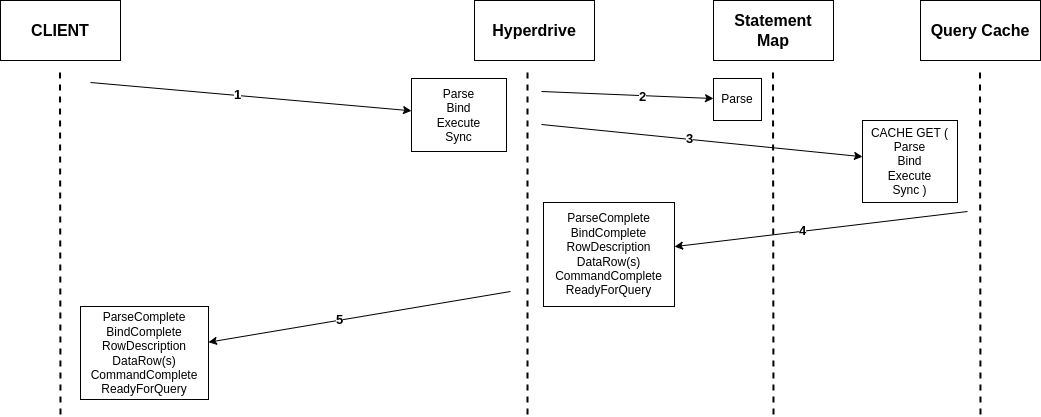
A Parse with a cache miss is a bit more complicated, as now we need to send these messages to the origin server. We take a connection at random from our pool and do so, passing the results back to the client. With that, we’ve begun to make changes to session state such that all our database connections are no longer identical to each other. To keep track of what we’ve done to muddy up our state, we keep a LruCache on each connection of which statements it already has prepared. In the case where we need to evict from such a cache, we will also DEALLOCATE the statement on the connection to keep things tracked correctly.
Reuse with a cache hit is yet more tricky, but still straightforward enough. In the example below, we are sent a Bind with the same parameters twice (#1 and #9). We must identify that we received a Bind without a preceding Parse, we must go retrieve that Parse (#10), and we must use the information from it to build our cache key. Once all that is accomplished, we can serve our results from cache, needing only to trim out the ParseComplete within the cached results before returning them to the client.

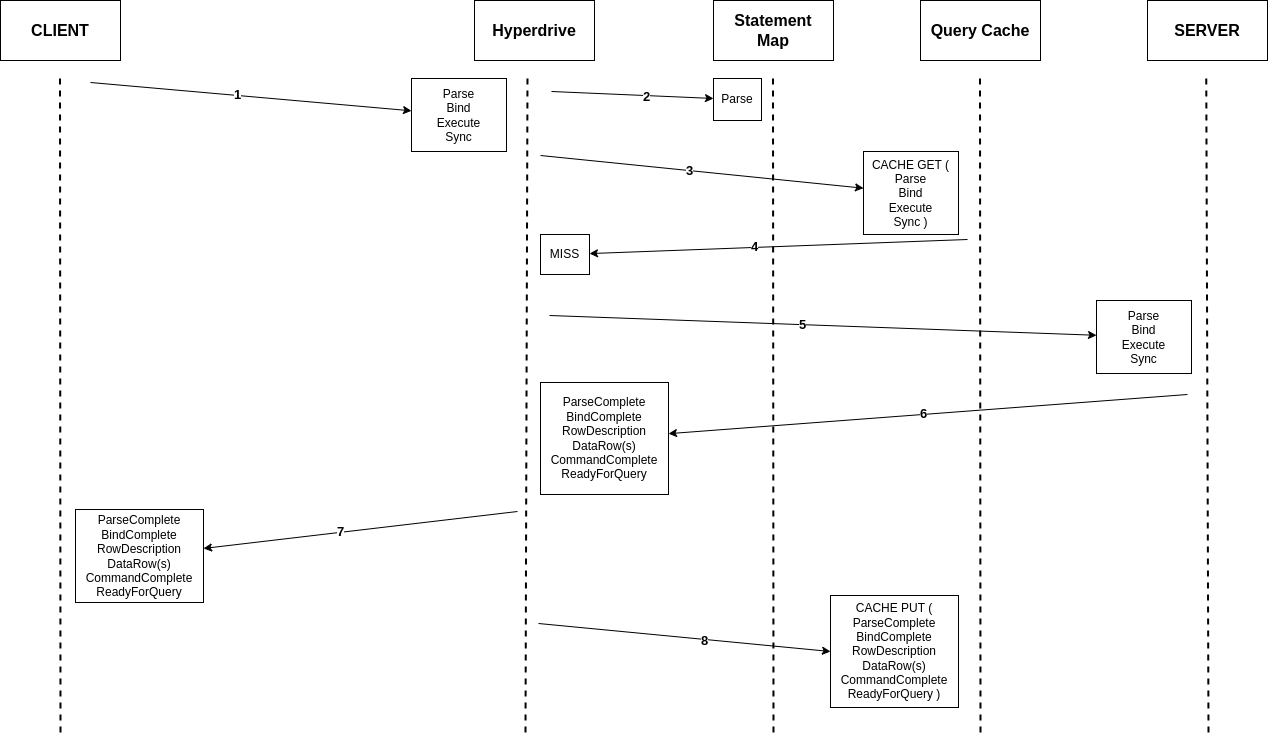
Reuse with a cache miss is the hardest scenario, as it may require us to lie in both directions. In the example below, we cache results for one set of parameters (#8), but are sent a Bind with different parameters (#9). As in the cache hit scenario, we must identify that we were not sent a Parse as part of the current message sequence, retrieve it from our HashMap (#10), and build our cache key to GET from cache and confirm the miss (#11). Once we take a connection from the pool, though, we then need to check if it already has the statement we want prepared. If not, we must take our saved Parse and prepend it to our message log to be sent along to the origin database (#13). Thus, what the server receives looks like a perfectly valid Parse-Bind-Execute-Sync sequence. This is where our VecDeque (mentioned above) comes in, as converting our message log to that structure allowed us to very ergonomically make such changes without needing to rebuild the whole byte sequence. Once we receive the response from the server, all that’s needed is to trim out the initial ParseComplete response from the server, as a well-made client would likely be very confused receiving such a response to a Parse it didn’t send. With that message trimmed out, however, the client is in the position of getting exactly what it asked for, and both sides of the conversation are happy.

Dénouement
Now that we’ve got a working solution, where all parties are functioning well, let’s review! Our solution lets us share database connections across arbitrary clients with no “pinning”, no custom handling on either client or server, and supports reuse of prepared statements to reduce CPU load on re-parsing queries and reduce network traffic on re-sending Parse messages. Engineering always involves tradeoffs, so the cost of this is that we will sometimes still need to sneak in a Parse because a client got assigned a different connection on reuse, and in those scenarios there is a small amount of additional memory overhead because the same statement is prepared on multiple connections.
And now, if you haven’t already, go give Hyperdrive a spin, and let us know what you think in the Hyperdrive Discord channel!
Source:: CloudFlare