In case you missed the announcement from Developer Week 2024, Cloudflare is now offering software development kits (SDKs) for Typescript, Go and Python. As a reminder, you can get started by installing the packages.
// Typescript
npm install cloudflare
// Go
go get -u github.com/cloudflare/cloudflare-go/v2
// Python
pip install --pre cloudflare
Instead of using a tool like curl or Postman to create a new zone in your account, you can use one of the SDKs in a language that you’re already comfortable with or that integrates directly into your existing codebase.
import Cloudflare from 'cloudflare';
const cloudflare = new Cloudflare({
apiToken: process.env['CLOUDFLARE_API_TOKEN']
});
const newZone = await cloudflare.zones.create({
account: { id: '023e105f4ecef8ad9ca31a8372d0c353' },
name: 'example.com',
type: 'full',
});
Since their inception, our SDKs have been manually maintained by one or more dedicated individuals. For every product addition or improvement, we needed to orchestrate a series of manually created pull requests to get those changes into customer hands. This, unfortunately, created an imbalance in the frequency and quality of changes that made it into the SDKs. Even though the product teams would drive some of these changes, not all languages were covered and the SDKs fell to either community-driven contributions or to the maintainers of the libraries to cover the remaining languages. Internally, we too felt this pain when using our own services and, instead of covering all languages, decided to rally our efforts behind the primary SDK (Go) to ensure that at least one of these libraries was in a good state.
This plan worked for newer products and additions to the Go SDK, which in turn helped tools like our Terraform Provider stay mostly up to date, but even this focused improvement was still very taxing and time-consuming for internal teams to maintain. On top of this, the process didn’t provide any guarantees on coverage, parity, or correctness because the changes were still manually maintained and susceptible to human error. Regardless of the size of contribution, a team member would still need to coordinate a minimum of 4 pull requests (shown in more depth below) before a change was considered shipped and needed deep knowledge of the relationship between the dependencies in order to get it just right.
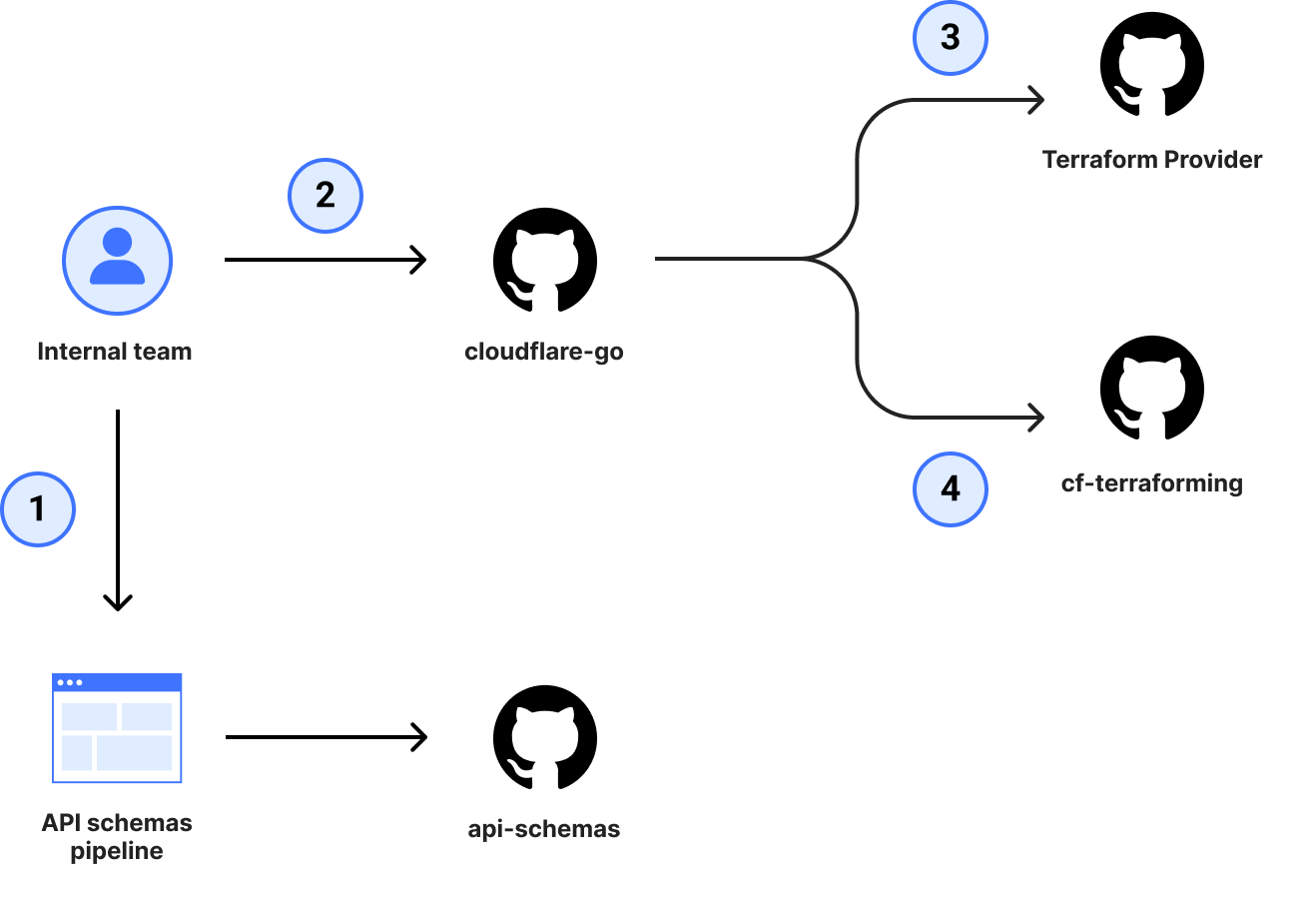 The pull requests previously required to ship an SDK change.
The pull requests previously required to ship an SDK change.
Following the completion of our transition to OpenAPI from JSON Hyper-Schema, we caught up internally and started discussing what else OpenAPI could help us unlock. It was at that point that we set the lofty goal of using OpenAPI for more than just our documentation. It was time to use OpenAPI to generate our SDKs.
Before we dove headfirst into generating SDKs, we established some guiding principles. These would be non-negotiable and determine where we spent our effort.
You should not be able to tell what underlying language generated the SDK
This was important for us because too often companies build SDKs using automation. Not only do you end up with SDKs that are flavored based on generator language, but the SDKs then lack the language nuances or patterns that are noticeable to users familiar with the language.
For example, a Rubyist may use the following if expression:
do_something if bar?
Whereas most generators do not have this context and would instead default to the standard case where if/else expressions are spread over multiple lines.
if bar?
do_something
end
Despite being a simple and non-material example, it demonstrates a nuance that a machine cannot decipher on its own. This is terrible for developers because you’re then no longer only thinking about how to solve the original task at hand, but you also end up tailoring your code to match how the generator has built the SDK and potentially lose out on the language features you would normally use. The problem is made significantly worse if you’re using a strongly typed language to generate a language without types, since it will be structuring and building code in a way that types are expected but never used.
Lowering the mean time to uniform support
When a new feature is added to a product, it’s great that we add API support initially. However, if that new feature or product never makes it to whatever language SDK you are using to drive your API calls, it’s as good as non-existent. Similarly, not every use case is for infrastructure-as-code tools like Terraform, so we needed a better way of meeting our customers with uniformity where they choose to integrate with our services.
By extension, we want uniformity in the way the namespaces and methods are constructed. Ignoring the language-specific parts, if you’re using one of our SDKs and you are looking for the ability to list all DNS records, you should be able to trust that the method will be in the dns namespace and that to find all records, you can call a list method regardless of which one you are using. Example:
// Go
client.DNS.Records.List(...)
// Typescript
client.dns.records.list(...)
// Python
client.dns.records.list(...)
This leads to less time digging through documentation to find what invocation you need and more time using the tools you’re already familiar with.
Fast feedback loops, clear conventions
Cloudflare has a lot of APIs; everything is backed by an API somewhere. However, not all Cloudflare APIs are designed with the same conventions in mind. Those APIs that are on the critical path and regularly experience traffic surges or malformed input are naturally more hardened and more resilient than those that are infrequently used. This creates a divergence in quality of the endpoint, which shouldn’t be the case.
Where we have learned a lesson or improved a system through a best practice, we should make it easy for others to be aware of and opt into that pattern with little friction at the earliest possible time, ideally as they are proposing the change in CI. That is why when we built the OpenAPI pipeline for API schemas, we built in mechanisms to allow applying linting rules, using redocly CLI, that will either warn the engineer or block them entirely, depending on the severity of the violation.
For example, we want to encourage usage of fine grain API tokens, so we should present those authentication schemes first and ensure they are supported for new endpoints. To enforce this, we can write a redocly plugin:
module.exports = {
id: 'local',
assertions: {
apiTokenAuthSupported: (value, options, location) => {
for (const i in value) {
if (value.at(i)?.hasOwnProperty("api_token")) {
return [];
}
}
return [{message: 'API Token should be defined as an auth method', location}];
},
apiTokenAuthDefinedFirst: (value, options, location) => {
if (!value.at(0)?.hasOwnProperty("api_token")) {
return [{message: 'API Tokens should be the first listed Security Option', location}];
}
return [];
},
},
};
And the rule configuration:
rule/security-options-defined:
severity: error
subject:
type: Operation
property: security
where:
- subject:
type: Operation
property: security
assertions:
defined: true
assertions:
local/apiTokenAuthSupported: {}
local/apiTokenAuthDefinedFirst: {}
In this example, should a team forget to put the API token authentication scheme first, or define it at all, the CI run will fail. Teams are provided a helpful failure message with a link to the conventions to discover more if they need to understand why the change is recommended.
These lints can be used for style conventions, too. For our documentation descriptions, we like descriptions to start with a capital letter and end in a period. Again, we can add a lint to enforce this requirement.
module.exports = {
id: 'local',
assertions: {
descriptionIsFormatted: (value, options, location) => {
for (const i in value) {
if (/^[A-Z].*.$/.test(value)) {
return [];
}
}
return [{message: 'Descriptions should start with a capital and end in a period.', location}];
},
},
};
rule/security-options-defined:
severity: error
subject:
type: Schema
property: description
assertions:
local/descriptionIsFormatted: {}
This makes shipping endpoints of the same quality much easier and prevents teams needing to sort through all the API design or resiliency patterns we may have introduced over the years – possibly even before they joined Cloudflare.
Building the generation machine
Once we had our guiding principles, we started doing some analysis of our situation and saw that if we decided to build the solution entirely in house, we would be at least 6–9 months away from a single high quality SDK with the potential for additional follow-up work each time we had a new language addition. This wasn’t acceptable and prevented us from meeting the requirement of needing a low-cost followup for additional languages, so we explored the OpenAPI generation landscape.
Due to the size and complexity of our schemas, we weren’t able to use most off the shelf products. We tried a handful of solutions and workarounds, but we weren’t comfortable with any of the options; that was, until we tried Stainless. Founded by one of the engineers that built what many consider to be the best-in-class API experiences at Stripe, Stainless is dedicated to generating SDKs. If you’ve used the OpenAI Python or Typescript SDKs, you’ve used an SDK generated by Stainless.
The way the platform offering works is that you bring your OpenAPI schemas and map them to methods with the configuration file. Those inputs then get fed into the generation engine to build your SDKs.
resources:
zones:
methods:
list: get /zones
The configuration above would allow you to generate various client.zones.list() operations across your SDKs.
This approach means we can do the majority of our changes using the existing API schemas, but if there is an SDK-specific issue, we can modify that behavior on a per-SDK basis using the configuration file.
An added benefit of using the Stainless generation engine is that it gives us a clear line of responsibility when discussing where a change should be made.
- Service team: Knows their service best and manages the representation for end users.
- API team: Understands and implements best practices for APIs and SDK conventions, builds centralized tooling or components within the platform for all teams, and translates service mappings to align with Stainless.
- Stainless: Provides a simple interface to generate SDKs consistently.
The decision to use Stainless has allowed us to move our focus from building the generation engine to instead building high-quality schemas to describe our services. In the span of a few months, we have gone from inconsistent, manually maintained SDKs to automatically shipping three language SDKs with hands-off updates freely flowing from the internal teams. Best of all, it is now a single pull request workflow for the majority of our changes – even if we were to add a new language or integration to the pipeline!
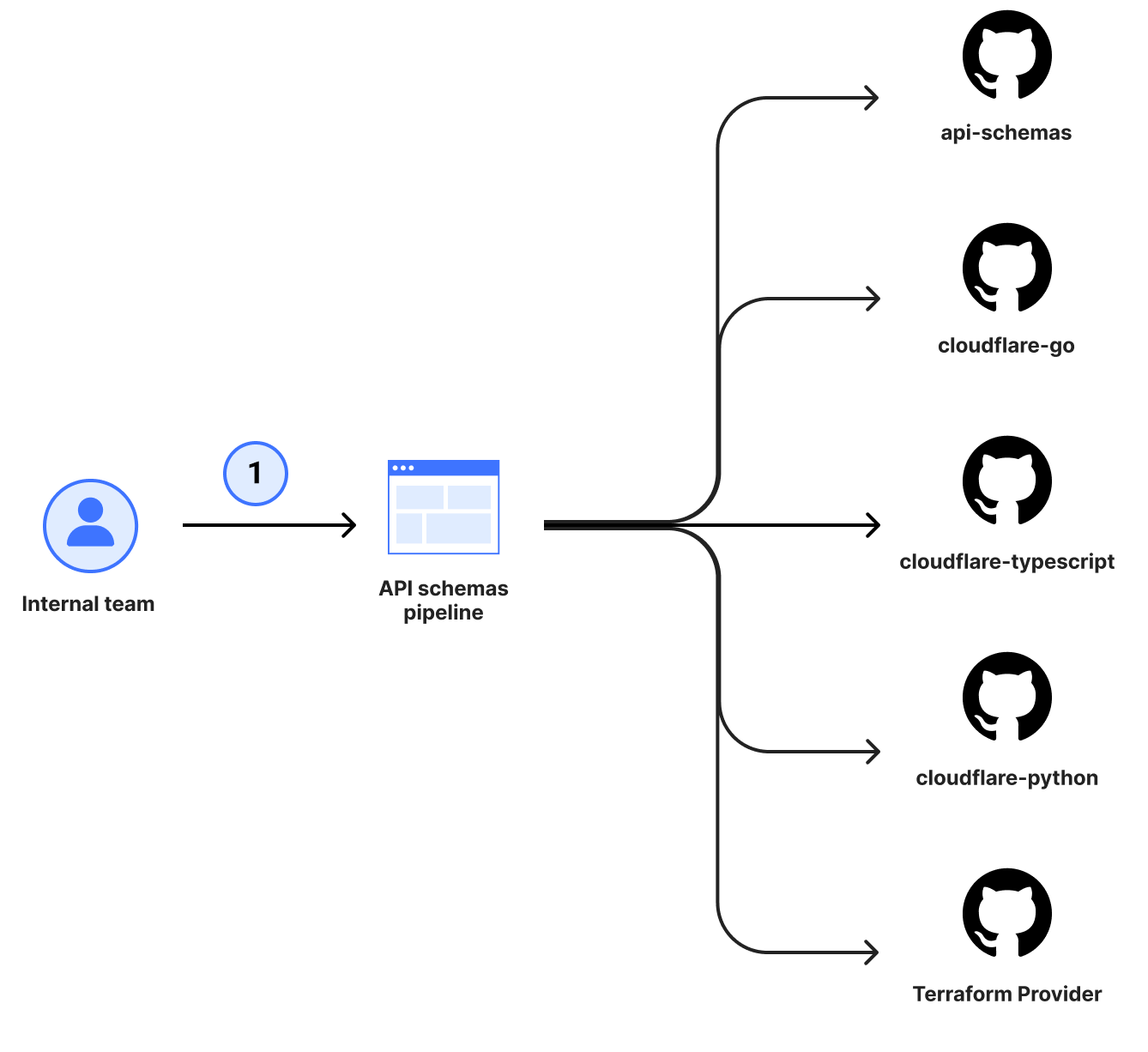 Just a single pull request is now required to ship an SDK change.
Just a single pull request is now required to ship an SDK change.
Lessons from our journey, for yours
Mass updates, made easy
Depending on the age of your APIs, you will have a diverging history of how they are represented to customers. That may be as simple as path parameters being inconsistent or perhaps something more complex like different HTTP methods for updates. While you can handle these individually at any sort of scale, that just isn’t feasible. As of this post, Cloudflare offers roughly 1,300 publicly documented endpoints, and we needed a more automatable solution. For us, that was codemods. Codemods are a way of applying transformations to perform large scale refactoring of your codebase. This allows you to programmatically rewrite expressions, syntax or other parts of your code without having to manually go through every file. Think of it like find and replace, but on steroids and with more context of the underlying language constructs.
We started with a tool called comby. We wrapped it in a custom CLI tool that knew how to speak to our version control endpoints and wired it in a way that provides a comby configuration TOML file, pull request description, and commit message for each transformation we needed to apply. Here is a sample comby configuration where we updated the URI paths to be consistently suffixed with _id instead of other variations (_identifier, Identifier, etc.) where we had a plural resource followed by an individual identifier.
[account-id-1-path-consistency]
match = 'paths/~accounts~1{account_identifier1}'
rewrite = 'paths/~accounts~1{account_id}'
[account-id-camelcase-path-consistency]
match = 'paths/~accounts~1{accountId}'
rewrite = 'paths/~accounts~1{account_id}'
[placeholder-identifier-to-id]
match = ':[_~_identifier}]' # need the empty hole match here since we are using unbalanced }
rewrite = '_id}'
[route-consistency-for-resource-plurals]
match = ':[topic~/w+/]{:[id~w+]}'
rewrite = ':[topic]{:[id]}'
rule = 'where rewrite :[id] { :[x] -> :[topic] }, rewrite :[id] { /:[x]s/ -> :[x]_id }'
[property-identifier-to-id]
match = 'name: :[topic]_identifier'
rewrite = 'name: :[topic]_id'
For an interactive version of this configuration, check out the comby playground.
This approach worked for the majority of our internal changes. However, knowing how difficult migrations can be, we also wanted a tool that we could provide to customers to use for their own SDK migrations. In the past we’ve used comby for upgrades in the Terraform Provider with great feedback. While comby is powerful, once you start using more complex expressions, the syntax can be difficult to understand unless you are familiar with it.
After looking around, we eventually found Grit. It is a tool that does everything we need (including the custom CLI) while being very familiar to anyone that understands basic Javascript through a query language, known as GritQL. An added bonus here is that we are able to contribute to the Grit Pattern Library, so our migrations are only ever a single CLI invocation away for anyone to use once they have the CLI installed.
// Migrate to the Golang v2 library
grit apply cloudflare_go_v2
Consistency, consistency, consistency
Did I mention consistency is important? Before attempting to feed your OpenAPI schemas into any system (especially a homegrown one), get them consistent with the practices, structures, and how you intend to represent them. This makes determining what is a bug in your generation pipeline vs a bug in your schema much easier. If it’s broken everywhere, it’s the generation pipeline, otherwise it’s an isolated bug to track down in your schema.
Having consistency leads into a better developer experience. From our examples above, if your routes always follow the plural resource name followed by an identifier, the end user doesn’t have to think about what the inputs need to be. The consistency and conventions lead them there – even if your documentation is lacking.
Use shared $refs sparingly
It seems like a great idea for reusability at the time of writing them, but when overused, $refs make finding correct values problematic and lead to cargo cult practices. In turn, this leads to lower quality and difficult-to-change schemas despite looking more usable from the outset. Consider the following schema example:
thing_base:
type: object
required:
- id
properties:
updated_at:
$ref: '#/components/schemas/thing_updated_at'
created_at:
$ref: '#/components/schemas/thing_updated_at'
id:
$ref: '#/components/schemas/thing_identifier'
thing_updated_at:
type: string
format: date-time
description: When the resource was last updated.
example: "2014-01-01T05:20:00Z"
thing_created_at:
type: string
format: date-time
description: When the resource was created.
example: "2014-01-01T05:20:00Z"
thing_id:
type: string
description: Unique identifier of the resource.
example: "2014-01-01T05:20:00Z"
Did you spot the bug? Have another look at the created_at value. You likely didn’t catch it at first glance, but this is a common issue when needing to reference reusable values. Here, it is a minor annoyance as the documentation would be incorrect (created_at would have the description of updated_at), but in other cases, it could be a completely incorrect schema representation.
For us, the correct usage of $ref values is predominantly where you have potential for multiple component schemas that may be used as part of a oneOf, allOf or anyOf directive.
dns_record:
oneOf:
- $ref: '#/components/schemas/dns-records_ARecord'
- $ref: '#/components/schemas/dns-records_AAAARecord'
- $ref: '#/components/schemas/dns-records_CAARecord'
- $ref: '#/components/schemas/dns-records_CERTRecord'
- $ref: '#/components/schemas/dns-records_CNAMERecord'
- $ref: '#/components/schemas/dns-records_DNSKEYRecord'
- $ref: '#/components/schemas/dns-records_DSRecord'
- $ref: '#/components/schemas/dns-records_HTTPSRecord'
- $ref: '#/components/schemas/dns-records_LOCRecord'
- $ref: '#/components/schemas/dns-records_MXRecord'
- $ref: '#/components/schemas/dns-records_NAPTRRecord'
- $ref: '#/components/schemas/dns-records_NSRecord'
- $ref: '#/components/schemas/dns-records_PTRRecord'
- $ref: '#/components/schemas/dns-records_SMIMEARecord'
- $ref: '#/components/schemas/dns-records_SRVRecord'
- $ref: '#/components/schemas/dns-records_SSHFPRecord'
- $ref: '#/components/schemas/dns-records_SVCBRecord'
- $ref: '#/components/schemas/dns-records_TLSARecord'
- $ref: '#/components/schemas/dns-records_TXTRecord'
- $ref: '#/components/schemas/dns-records_URIRecord'
type: object
required:
- id
- type
- name
- content
- proxiable
- created_on
- modified_on
When in doubt, consider the YAGNI principle instead. You can always refactor and extract this later once you have enough uses to determine the correct abstraction.
Design your ideal usage and work backwards
Before we wrote a single line of code to solve the problem of generation, we prepared language design documents for each of our target languages that followed the README-driven design principles. This meant our focus from the initial design was on the usability of the library and not on the technical challenges that we would eventually encounter. This led us to identify problems and patterns early with how various language nuances would surface to the end user without investing in anything more than a document. Python keyword arguments, Go interfaces, how to enforce required parameters, client instantiation and overrides, types – all considerations made up front that helped minimize the number of unknowns as we built out support.
What’s next?
When we embarked on the OpenAPI journey, we knew it was only the beginning and would eventually open more doors and quality of life improvements for teams and customers alike. Now that we have a few language SDKs available, we’re turning our attention to generating our Terraform Provider using the same guiding principles to further minimize the maintenance burden. But that’s still not all. Coming later in 2024 are more improvements and integrations with other parts of the Cloudflare Developer Platform, so stay tuned.
If you haven’t already, check out one of the SDKs in Go, Typescript and Python today. If you’d like support for a different language, go here to submit your details to help determine the next language. We’d love to hear what languages you would like offered as a Cloudflare SDK.
Source:: CloudFlare