
Visual generative AI is the process of creating images from text prompts. The technology is based on vision-language foundation models that are pretrained on…
Visual generative AI is the process of creating images from text prompts. The technology is based on vision-language foundation models that are pretrained on web-scale data. These foundation models are used in many applications by providing a multimodal representation. Examples include image captioning and video retrieval, creative 3D and 2D image synthesis, and robotic manipulation. All these tasks benefit from the “open-world” capabilities of vision-language foundation models, making it possible to use rich, free-form text and a “long tail” of visual categories.
With these powerful representations, a new challenge arises. That is, how to use these models with user-specific, or personalized, visual concepts. How can these models be taught to combine such user-specific concepts with their prior knowledge based on what they have already learned from a massive dataset?
For example, a creative director for a toy brand is planning an ad campaign around a new teddy bear product and wants to show the toy in different situations, dressed as a superhero or a wizard. Or a child wants to create funny cartoons of the family dog. Or an interior designer wants to design a room while using an heirloom family sofa. All of these personalized use cases will involve composing a new scene and combining specific items with generic components.
Several algorithms are designed to address this challenge. Such personalization algorithms should meet the following quality, usability, and efficiency goals:
- Capture the visual identity of the learned concept and, at the same time, change it based on the text prompt.
- Provide the ability to combine several learned concepts in a single image.
- Be fast, with a small memory footprint per concept.
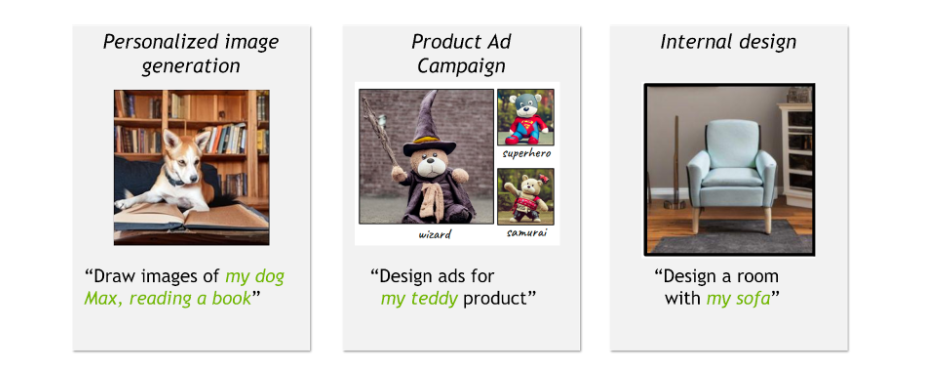 Figure 1. Examples of use cases for personalized image generation
Figure 1. Examples of use cases for personalized image generation
What is textual inversion?
This section explores the core idea of personalization through textual inversion, the basic technique for personalizing generative AI.
Given a few training images of a concept, the goal is to learn a new concept in a way that enables a foundation model to generate its image using rich language in a compositional way. The concept can be combined with nouns, relations, and adjectives that were not seen with the new concept during its training. At the same time, the concept should maintain its “essential” visual properties, even when modified and combined with other concepts.
The approach called textual inversion overcomes these challenges by finding new words in the word embedding space of frozen vision-language foundation models (Figure 2). This involves learning to match a new embedding vector with a new “pseudo-word” marked with a placeholder 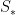
To find the embedding vector for
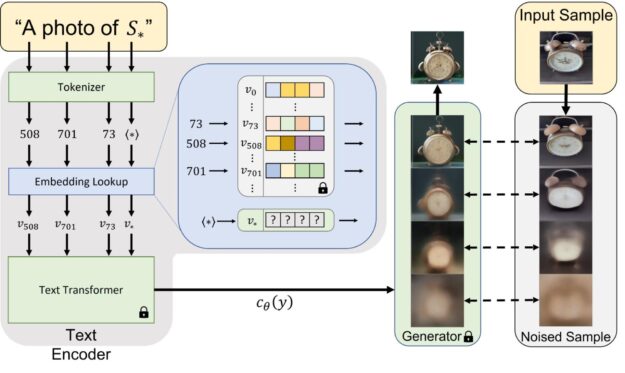 Figure 2. Textual inversion aims to find a new embedding vector that represents the new, specific concept. This vector is found by trying to recreate images of the concept from a small (3-5 image) set
Figure 2. Textual inversion aims to find a new embedding vector that represents the new, specific concept. This vector is found by trying to recreate images of the concept from a small (3-5 image) set
Experimental insights
Text-to-image personalization enables a range of applications. Figure 3 shows the composition of novel scenes by incorporating the learned pseudo-words into new text prompts. Each concept is learned from four example images and then used in new and complex text prompts. The frozen text-to-image model can combine its large body of prior knowledge with the new concepts, bringing them together in a new creation.
Surprisingly, although the training objective when learning the concept is visual in nature, the learned pseudo-words encapsulate semantic knowledge. For example, the bowl (bottom row) can contain other objects.
 Figure 3. Examples of new concepts learned with textual inversion
Figure 3. Examples of new concepts learned with textual inversion
Personalization also enables learning a new, less biased word for a biased concept by using a small, curated dataset. This new word can then be used in place of the original word to drive more inclusive generation (Figure 4).
 Figure 4. Personalization can be used to learn a less biased concept. The term ‘doctor’ from the base model (left) is replaced with a more inclusive term (right)
Figure 4. Personalization can be used to learn a less biased concept. The term ‘doctor’ from the base model (left) is replaced with a more inclusive term (right)
Better editing in a lightweight model
The textual inversion method previously described is a lightweight model, encoding a concept with only 1K parameters. Being so small, its quality may falter when required to combine multiple concepts or control concepts tightly with text.
An alternative model presented in DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation takes the opposite approach. Fine-tuning a gigabyte-sized U-Net architecture yields a model that is resource-intensive, requiring gigabytes of storage for every concept with a slow training speed. LoRA (Low-Rank Adaptation) can be combined with DreamBooth to reduce its storage footprint by freezing the U-Net weights and injecting smaller trainable matrices into specific layers.
We set out to design a network architecture and algorithm that generates images that better agree with the text prompt and the visual identity while maintaining a small model size and supporting the combination of multiple learned concepts into a single image.
We proposed a method to tackle all these challenges by making lightweight rank-1 model edits, as explained in Key-Locked Rank One Editing for Text-to-Image Personalization. This yields better generalization while personalizing a model in as few as 100KB of storage within 4–7 minutes.
The idea is quite intuitive. Using the example of the teddy bear, the pretrained model may already know to generate images of a generic teddy bear dressed as a superhero. In this case, first generate an image for a generic teddy bear, keep the activation of some model components “locked,” and regenerate an image with the specific personalized teddy bear. The key is, of course, which components should be locked.
Our main insight is that the key pathway of the cross-attention module in the diffusion model (the K matrix) controls the layout of the attention maps. Indeed, we observed that existing techniques tend to overfit that component, causing the attention on novel words to leak beyond the visual scope of the concept itself.
Based on this observation, we proposed a key-locking mechanism (Figure 5), in which the keys of a personalized concept (the teddy bear) are fixated on the keys of the super-category (a stuffed animal or even a generic toy). To keep the model lightweight and fast to train, we incorporated these components directly into the text-to-image diffusion model. We also added a gating mechanism to regulate how strongly the learned concept is considered and combines multiple concepts at inference time. We call our approach Perfusion (personalized diffusion).
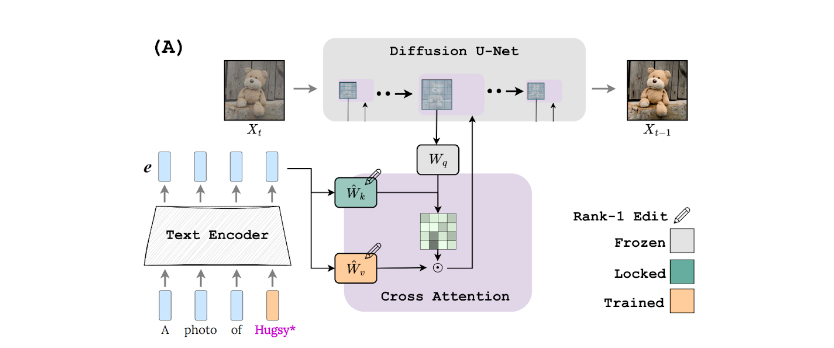 Figure 5. Perfusion architecture, in which a prompt is fed to cross-attention modules (represented by purple blocks) and the key then generates an attention map to modulate the value pathway
Figure 5. Perfusion architecture, in which a prompt is fed to cross-attention modules (represented by purple blocks) and the key then generates an attention map to modulate the value pathway
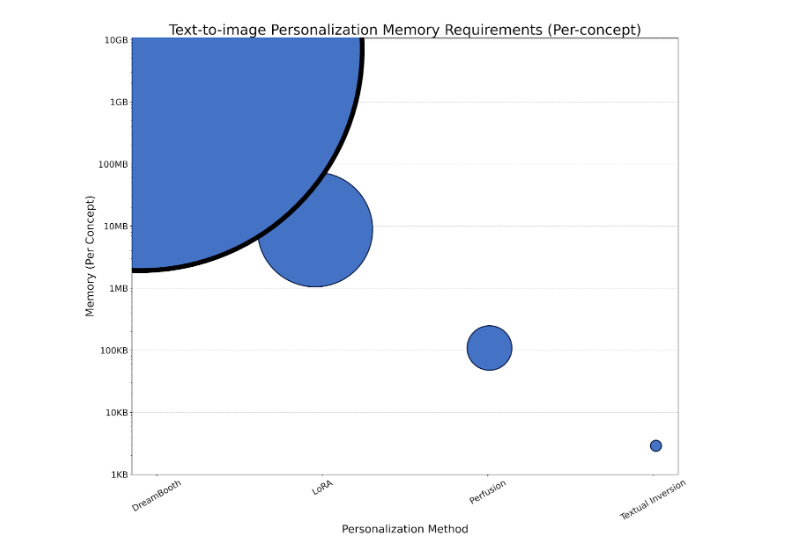 Figure 6. The additional memory required for every personalized concept for four personalization methods: DreamBooth, LoRA, Perfusion, and textual inversion. Circle sizes are a function of the per-concept memory requirements
Figure 6. The additional memory required for every personalized concept for four personalization methods: DreamBooth, LoRA, Perfusion, and textual inversion. Circle sizes are a function of the per-concept memory requirements
Experimental insights
This section presents a series of examples that explore the properties of Perfusion.
Figure 7 shows high-quality personalized generated images, combining two novel concepts into a single image. The images on the left are used to teach the model the new personalized concepts, teddy* and teapot*. In practice, a specific description is not necessary, and we could have used a broader concept such as toy*. In the images on the right, these concepts are combined—and in surprising ways, such as “a teddy* sailing in a teapot*.”
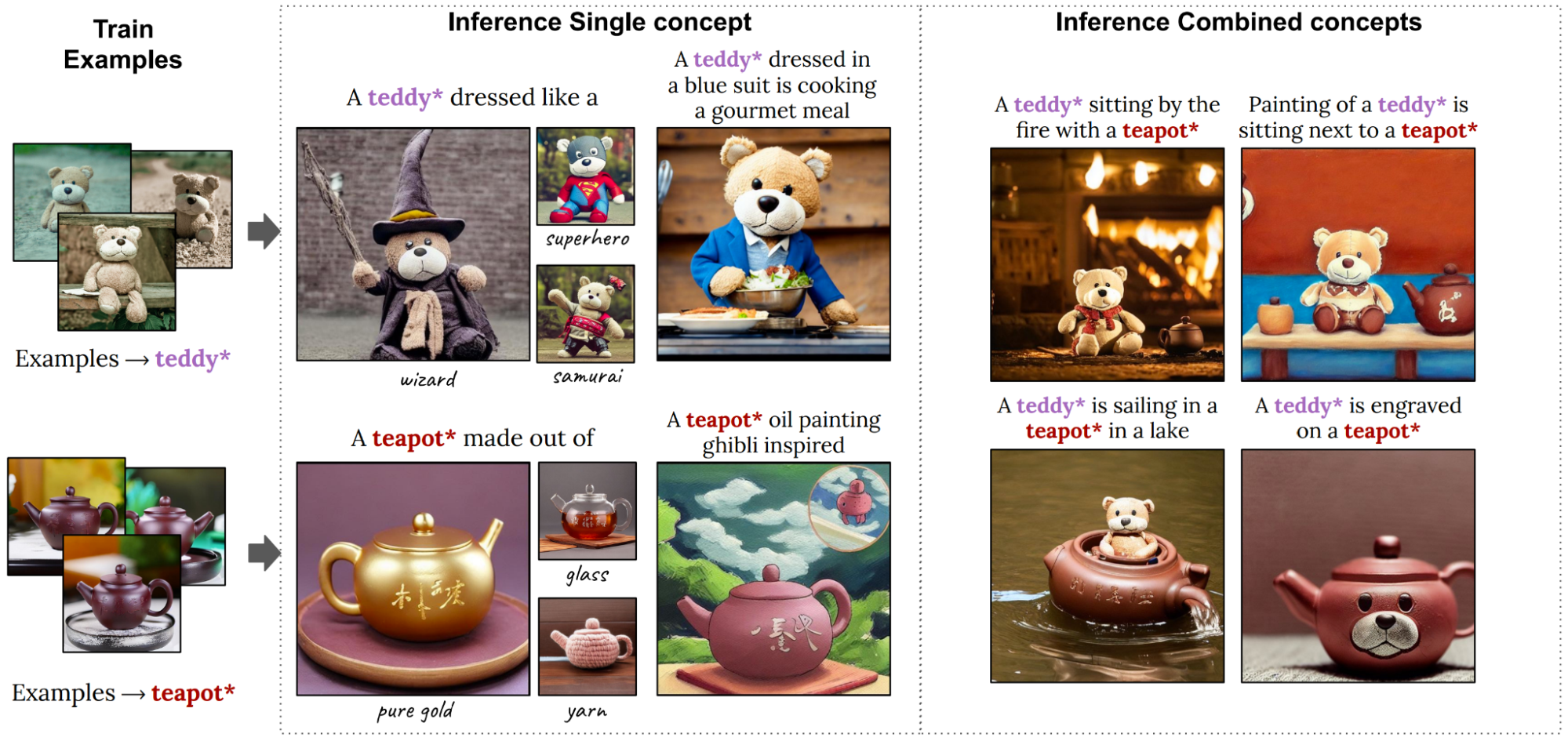 Figure 7. Examples of high-quality personalized generated images
Figure 7. Examples of high-quality personalized generated images
Figure 8 explores the effect of using key locking in Perfusion, regarding the similarity of generated images with the text prompt. Images generated with key locking (top row) match the prompt much better than those without key locking (bottom row), at the cost of somewhat lower similarity with the posture and appearance of the training images. Training the keys resembles DreamBooth or LoRA but requires less storage space.
 Figure 8. Images generated with key locking (top) match the prompt better than those generated without key locking (bottom)
Figure 8. Images generated with key locking (top) match the prompt better than those generated without key locking (bottom)
Figure 9 illustrates how Perfusion enables a creator to control the balance between visual fidelity and similarity to the text during generation using a single runtime parameter. On the left are quantitative results of a single trained model, in which a single runtime parameter is adjusted. Perfusion can span a wide range of outcomes (represented by the blue line) by tuning this parameter at generation time without retraining. The images on the right illustrate the effect that this parameter has on the generated images.
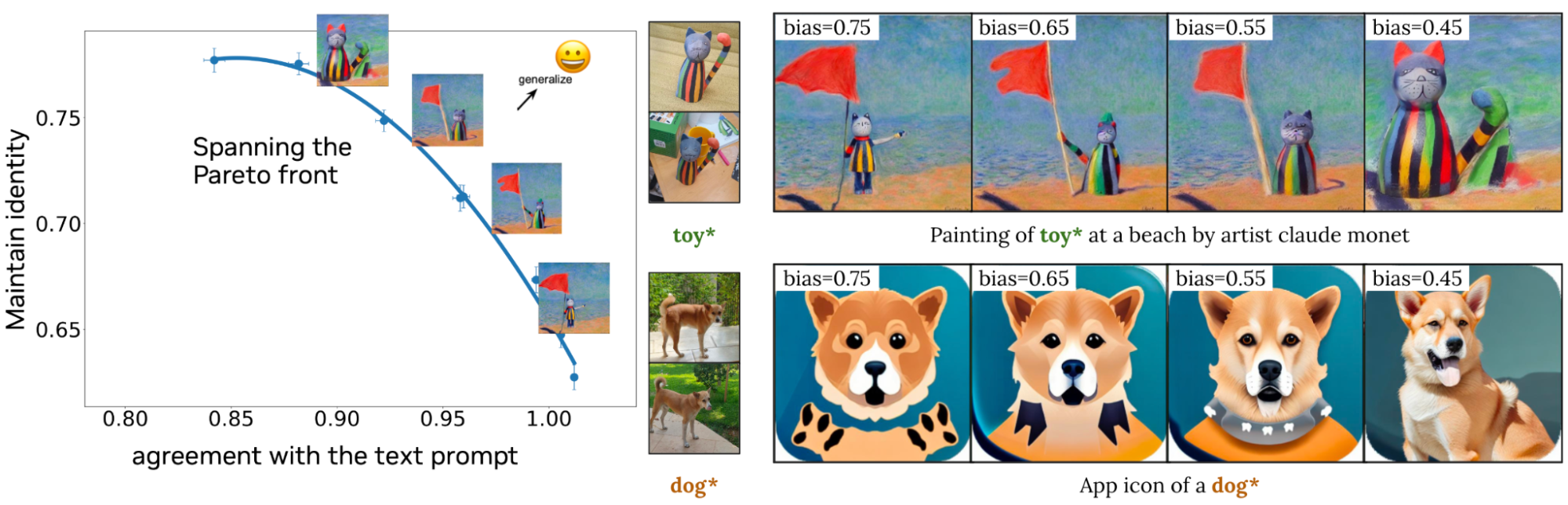 Figure 9. Controlling visual-textual similarity at the time of inference
Figure 9. Controlling visual-textual similarity at the time of inference
Figure 10 compares Perfusion with baseline methods. Perfusion achieves excellent prompt agreement without being affected by traits of the training images.
 Figure 10. Comparisons of Perfusion personalization with baseline methods
Figure 10. Comparisons of Perfusion personalization with baseline methods
Accelerating personalization
Most personalization methods, such as textual inversion and Perfusion, can require several minutes to teach a model a new concept. This can often be quick enough for hobbyist work, but there is a faster and more efficient way to enable personalization at scale or on the fly.
One approach to speeding up the training processes of a new concept is to pretrain an encoder. An encoder is a neural network trained to predict the approximate outcome of a lengthy personalization training process. For example, if you want to teach the model a new word that represents your cat, you could train a new model that takes as an input one (or more) images of your cat, and outputs a numeric representation for a new word. You can then feed that representation into your text-to-image model to generate new pictures of your cat.
We proposed an encoder-for-tuning (E4T) method, which takes a two-step approach. In the first step, it learns to predict a new word that describes a concept and a set of weight offsets for the class of that concept. These offsets make it easier to learn to personalize new objects from that class, like dogs, cats, or faces. These offsets are kept small (regularized) to avoid overfitting.
In the second step, the full model weights (including the weight offsets) are fine-tuned to better reconstruct the single image of the concept. While this still requires some tuning, our first step ensures we start very close to the concept. As a result, training a new concept takes as few as five training steps, lasting mere seconds instead of minutes.
Conclusion
Recent advances in personalized generation now enable the creation of high-quality images of specific personalized items in surprisingly new contexts. This post has explained the basic idea behind personalization and two approaches for improving personalized text-to-image models.
The first approach uses key locking to improve similarity with the visual appearance of the training images and the text prompt meaning. The second approach uses an encoder to accelerate personalization 100x with fewer images. These two technologies can be combined, yielding a high-quality, lightweight model that’s very fast to train.
These technologies still have limitations. Learned models don’t always fully preserve the identity of a concept and may be more difficult to edit using text prompts rather than generic concepts. Future work continues to improve on these limitations.
Interested in using these approaches in commercial applications? Fill out the research licensing request form.
Source:: NVIDIA