An AI agent is a system consisting of planning capabilities, memory, and tools to perform tasks requested by a user. For complex tasks such as data analytics or…![]()
An AI agent is a system consisting of planning capabilities, memory, and tools to perform tasks requested by a user. For complex tasks such as data analytics or interacting with complex systems, your application may depend on collaboration among different types of agents. For more context, see Introduction to LLM Agents and Building Your First LLM Agent Application.
This post explains the agent types required to build an accurate LLM application that can handle nuanced data analysis tasks when queried. It walks through an example use case for building a data analyst agent application, including code snippets. Finally, it provides some considerations for AI developers to consider when optimizing and building LLM agent apps.
LLM agent types for data analysis tasks
To begin, this section explains two main types of LLM agents and how they work—data agents and API or execution agents. I’ll also present an agent swarm use case, which involves multiple agents collaborating to solve a problem. Note that these agent types somewhat represent the ends of a spectrum. Blended, purpose-built agents can be created for specific use cases.
Data agents
Data agents are typically designed for an extractive goal. In other words, data agents assist users in extracting information from a wide range of data sources. They help with assistive reasoning tasks.
For example, a financial analyst might ask, “In how many quarters of this year did the company have a positive cash flow?” This type of question requires reasoning, search (structured, unstructured, or both), and planning capabilities.
API or execution agents
API or execution agents are designed for an execution goal. These agents carry out a task or set of tasks requested by a user.
Consider the same financial analyst working with an Excel spreadsheet that contains the past year’s closing prices for 10 stocks. The analyst wants to organize these closing prices according to one or more statistical formulas. Excel APIs need to be chained together to perform this task. For another API agent example, see the Google Places API Copilot Demo.
Agent swarms
Agent swarms involve multiple data agents and multiple API agents collaborating in a decentralized manner to solve a complex problem. Agent swarms are designed for workflows that include both extractive and execution tasks that require different forms of planning and agent core harnesses.
For example, imagine that the financial analyst wants to study the top five fast food stocks for investment planning. The sequence of actions needed to reach this goal are outlined below and in Figure 1.
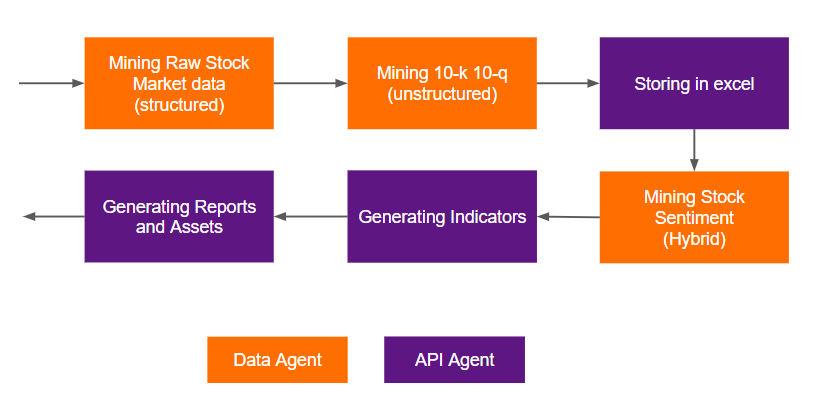 Figure 1. A general conceptual flow of the execution of a complex workflow solved with multiple agents
Figure 1. A general conceptual flow of the execution of a complex workflow solved with multiple agents
As more types of LLM agents are modeled, they can interact with each other in the agent swarm to effectively solve problems. Constraining the problem into different agent verticals enables building agents with smaller models. This requires less effort for customization and retains modularity, which in turn provides benefits for adding new features, selecting the features you want, and simplifying deployment scaling. In this ecosystem, every agent looks at another agent like a tool and uses its help when required.
Building a data analyst agent
With this general taxonomy as a foundation, this section dives into building a data agent for a use case of talking to an SQL database for inventory management. The following discussion assumes you have read Building Your First LLM Agent Application, or are otherwise familiar with the basics of LLM agents.
Choose an LLM
Begin by identifying which LLM to use. This example uses the Mixtral 8x7B LLM available in the NVIDIA NGC catalog. It accelerates various models and makes them available as APIs. The first API calls per model are free for experimentation.
Note that if you’re working with a model that isn’t tuned to handle agent workflows, you can reformulate the prompts below as a series of multiple-choice questions (MCQs). This should work, as most of the models are instruction-tuned to handle MCQs. Learn more about fine-tuning.
Select a use case
Next, select a use case. The use case for this post is talking to an SQL database for inventory management. Then populate that database with, for example, three tables.
Note that the information presented below is for exemplary purposes only and is not intended to convey actual details.
suppliers_data = [
{"name": "Samsung Electronics", "address": "Seoul, South Korea", "contact": "800-726-7864"},
{"name": "Apple Inc.", "address": "Cupertino, California, USA", "contact": "800–692–7753"},
{"name": "OnePlus Technology", "address": "Shenzhen, Guangdong, China", "contact": "400-888-1111"},
{"name": "Google LLC", "address": "Mountain View, California, USA", "contact": "855-836-3987"},
{"name": "Xiaomi Corporation", "address": "Beijing, China", "contact": "1800-103-6286"},
]
products_data = [
{"name": "Samsung Galaxy S21", "description": "Samsung flagship smartphone", "price": 799.99, "supplier_id": 1},
{"name": "Samsung Galaxy Note 20", "description": "Samsung premium smartphone with stylus", "price": 999.99, "supplier_id": 1},
{"name": "iPhone 13 Pro", "description": "Apple flagship smartphone", "price": 999.99, "supplier_id": 2},
{"name": "iPhone SE", "description": "Apple budget smartphone", "price": 399.99, "supplier_id": 2},
{"name": "OnePlus 9", "description": "High performance smartphone", "price": 729.00, "supplier_id": 3},
{"name": "OnePlus Nord", "description": "Mid-range smartphone", "price": 499.00, "supplier_id": 3},
{"name": "Google Pixel 6", "description": "Google's latest smartphone", "price": 599.00, "supplier_id": 4},
{"name": "Google Pixel 5a", "description": "Affordable Google smartphone", "price": 449.00, "supplier_id": 4},
{"name": "Xiaomi Mi 11", "description": "Xiaomi high-end smartphone", "price": 749.99, "supplier_id": 5},
{"name": "Xiaomi Redmi Note 10", "description": "Xiaomi budget smartphone", "price": 199.99, "supplier_id": 5},
]
inventory_data = [
{"product_id": 1, "quantity": 150, "min_required": 30},
{"product_id": 2, "quantity": 100, "min_required": 20},
{"product_id": 3, "quantity": 120, "min_required": 30},
{"product_id": 4, "quantity": 80, "min_required": 15},
{"product_id": 5, "quantity": 200, "min_required": 40},
{"product_id": 6, "quantity": 150, "min_required": 25},
{"product_id": 7, "quantity": 100, "min_required": 20},
{"product_id": 8, "quantity": 90, "min_required": 18},
{"product_id": 9, "quantity": 170, "min_required": 35},
{"product_id": 10, "quantity": 220, "min_required": 45},
For experimentation, store the preceding entries in an SQLite database. These entries are tailored for the schema shown in Figure 2. The intention is to create a simplified version of a database that is typically at the heart of any inventory management system. These databases contain information about current inventory levels, suppliers, and more.
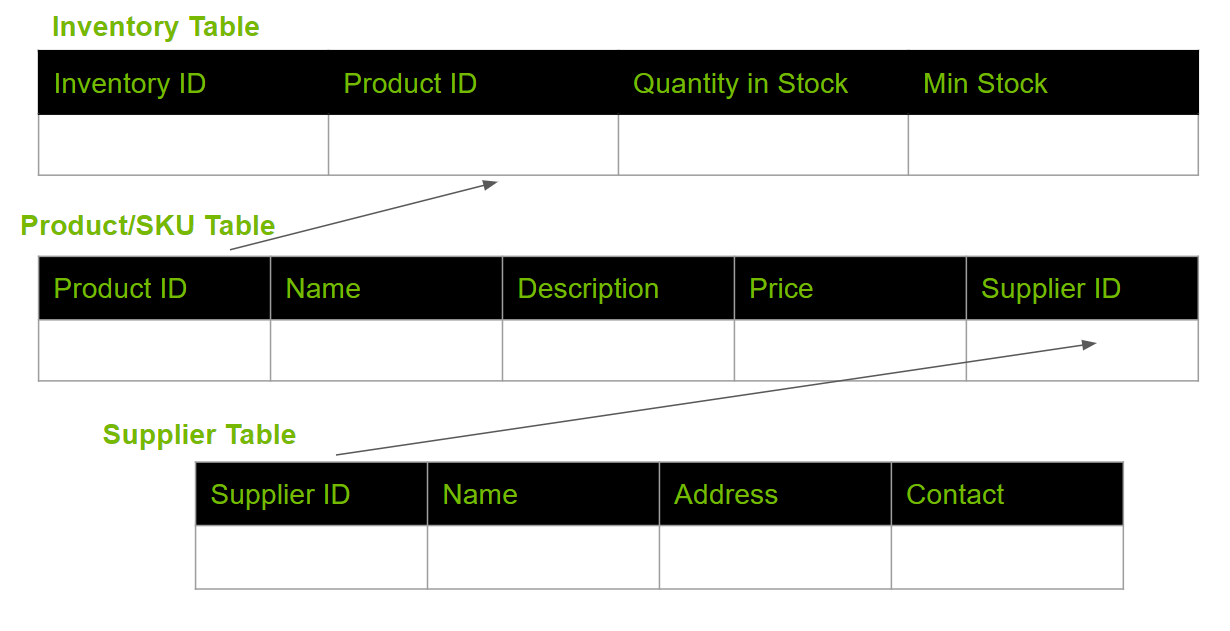 Figure 2. Schema of the sample database to showcase the use case
Figure 2. Schema of the sample database to showcase the use case
LLM agent components
An LLM agent contains four key components: tools, memory module, planning module, and agent core. Details about the components for this example are provided below.
Tools
This example uses the following two tools:
- Calculator: For any basic calculations needed after querying the data. To keep it simple, an LLM is used here. Any service or API can be added to solve said problem.
- SQL Query Executor: For querying the database for raw data.
Memory
A simple buffer or list to keep track of all the agent’s actions.
Planning
A linear greedy approach. To achieve this, create a “faux tool” for “generate the final answer.” This idea is addressed further in the section below.
Agent core
Time to put everything together. The prompt for the agent core LLM looks something like this:
""" [INST]You are an agent capable of using a variety of TOOLS to answer a data analytics question.
Always use MEMORY to help select the TOOLS to be used.
MEMORY
TOOLS
- Generate Final Answer: Use if answer to User's question can be given with MEMORY
- Calculator: Use this tool to solve mathematical problems.
- Query_Database: Write an SQL Query to query the Database.
ANSWER FORMAT
```json
{
"tool_name": "Calculator"
}
```
[/INST]
User: {User's Question}
Assistant: ```json
{
"tool_name": """
The preceding prompt includes all the tools and related information. You can design the core’s code harness in a way such that, given any tool but the “generate the final answer” faux tool, the agent will append the results of the tool used to memory and re-access the situation. This is an iterative greedy approach where the “best” decision is made for the individual step.
if tool_selection['tool_name'] == "Query_Database":
Generate_SQL_Query(question, memory, schema)
QueryDB
Append results to memory
Agent(question, memory)
if tool_selection['tool_name'] == "Generate Final Answer":
Final_Output = llm(question, memory)
return final output
if tool_selection['tool_name'] == "Calculator":
Ask_Math_Question_To_LLM(question, memory)
Append results to memory
Agent(question, memory)
In summary, a data agent has access to planning capability, memory, multiple data access tools, and means of performing related analytical tasks. Figure 3 shows the general architecture of a data agent.
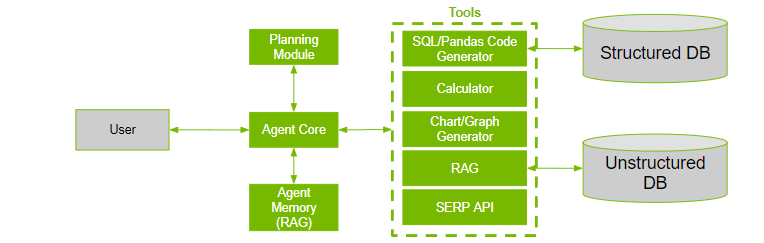 Figure 3. General architecture of a data agent
Figure 3. General architecture of a data agent
Data agent example
This section provides an example that showcases how different tools can be used together to solve business questions. The key advantage for using an agent in a scenario like this is that the user doesn’t need to know details about the database or the technical skill to run queries.
Question: “How much excess inventory do I have for Google Pixel 6?”
Answer: Based on the retrieved information from the inventory system, you currently have 80 units of excess inventory for Google Pixel 6. This calculation is derived by subtracting the minimum required quantity (20) from the current quantity in stock (100). (See above for source data.)
 Figure 4. Sample data agent output
Figure 4. Sample data agent output
To solve this question, the agent performed the following steps:
Step 1: QueryDB tool
- Generate SQL
- Query database
- Store results in memory
Step 2: Calculator tool
- Solve math problem using LLM
- Store results in memory. Note that this can be replaced with code generation plus code execution.
Step 3: Final answer generation
The following prompt is for the agent core LLM after SQL is generated.
"""
[INST]You are an agent capable of using a variety of TOOLS to answer a data analytics question.
Always use MEMORY to help select the TOOLS to be used.
MEMORY
Previous Question: How much excess inventory do we have for 'Google Pixel 6'?
SQL Query:
SELECT
inventory.id,
inventory.product_id,
inventory.quantity,
inventory.min_required,
products.name
FROM
inventory
JOIN
products ON inventory.product_id = products.id
WHERE
products.name = 'Google Pixel 6';
Retrieved Information: [(7, 7, 100, 20, 'Google Pixel 6')]
TOOLS
- Generate Final Answer: Use if answer to User's question can be given with MEMORY
- Calculator: Use this tool to solve mathematical problems.
- Query_Database: Write an SQL Query to query the Database.
ANSWER FORMAT
```json
{
"tool_name": "Calculator"
}
```
[/INST]
User: How much excess inventory do we have for 'Google Pixel 6'?
Assistant: ```json
{
"tool_name": """
Key considerations when building data agent applications
Keep in mind the following key considerations when building your LLM agent application.
Scaling the tools
Imagine a case with 100K tables and 100 tools, rather than three tables and three tools. One way to accommodate this type of scaling is to add an intermediate RAG step. This step might pull in the top five most relevant tools for the agent to select from. This can apply to memory, database schema, or any other options that the agent needs to consider.
Working with multiple vector databases
You can also build a topical router to direct the queries to the correct database in situations with multiple SQL or vector databases.
Better planning for implementation
A simple linear solver to implement a greedy iterative solution is featured here. It can be replaced by a task decomposition module or a plan compiler of sorts to generate a more efficient plan of execution.
Summary
This post has explained the basics of how to build an LLM agent application for data analytics to help familiarize you with the concepts behind building agents. I highly recommend exploring the open-source ecosystem to select the best agent framework for your application.
Ready to build your own LLM data agent for production? Check out the AI Chatbot with Retrieval-Augmented Generation free hands-on lab to help you build reliable and scalable solutions.
Source:: NVIDIA