
A common technological misconception is that performance and complexity are directly linked. That is, the highest-performance implementation is also the most…
A common technological misconception is that performance and complexity are directly linked. That is, the highest-performance implementation is also the most challenging to implement and manage. When considering data center networking, however, this is not the case.
InfiniBand is a protocol that sounds daunting and exotic in comparison to Ethernet, but because it is built from the ground up for the highest performance, it is actually simpler to deploy and maintain. When you are considering connectivity for AI infrastructure, the InfiniBand Cluster Operation and Maintenance Guide helps make setting up and operating a full-stack InfiniBand network as simple as possible.
This comprehensive guide covers the essential steps needed to streamline Day 0, Day 1, and Day 2 network operations. In particular, the guide details how to use NVIDIA Unified Fabric Manager (UFM) to assist in initial provisioning as well as ongoing maintenance plans.
UFM is a powerful toolset with wide-ranging telemetry and analytics capabilities. However, getting started with UFM for the basics of cluster monitoring and management does not require any advanced prerequisites or specialized knowledge.
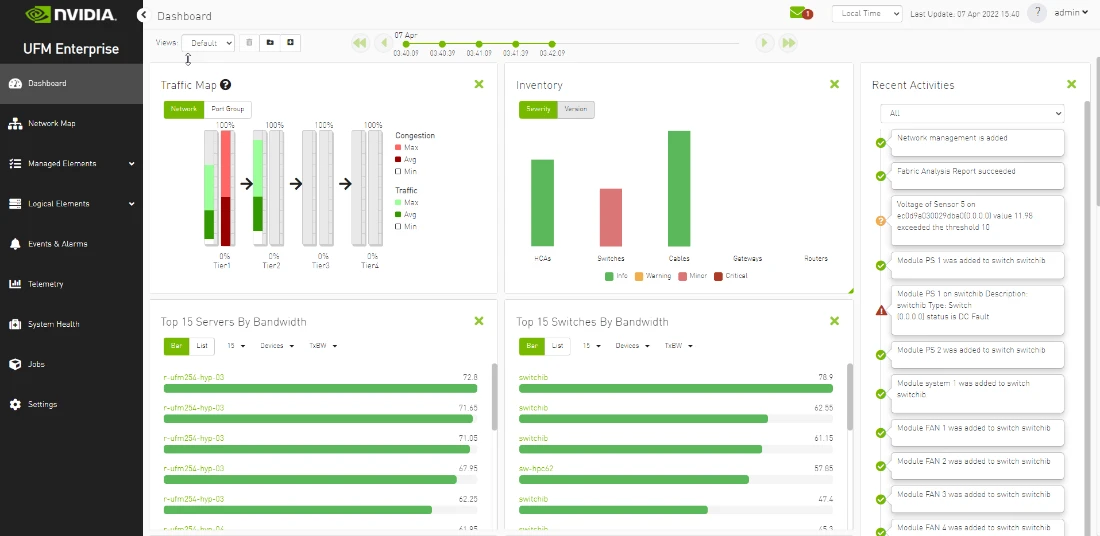 Figure 1. UFM Fabric dashboard
Figure 1. UFM Fabric dashboard
Cluster build and operation
The guide walks you through bring-up:
- Verifying UFM operational status
- Generating the fabric health report and topology validation
- Verifying cluster performance
The guide also provides an introduction to congestion analysis with UFM Telemetry. UFM telemetry and monitoring capabilities are powerful. Third-party plugins to tools such as Grafana, Fluentd, Slurm, and Zabbix enable you to capture vital networking metrics and use them with your platform of choice.
When the administrator knows that the cluster is in a healthy initial state, the guide suggests a cluster maintenance regime, with a list of checks for periodic maintenance.
Minutely/Ongoing Maintenance:
- Check for scenarios on the troubleshooting list and follow the instructions for resolution.
Weekly Maintenance:
- Monitor trends in link monitoring key indicators (available in the UFM user interface).
- Run cluster topology validation checks and fabric health validation tests.
- Verify performance KPIs with ClusterKit (included as part of the HPC-X software package).
- Review temperature differentials captured within UFM to ensure that your cooling system is working properly.
Quarterly/Annual Maintenance:
- Examine the most recent firmware and software release notes and validated configurations and upgrade if possible.
- Conduct an annual review of NVIDIA network health by contacting NVIDIA Networking support or your designated NVIDIA point of contact
Many of these checks may be automated and are configurable through the API. The guide provides links to the appropriate UFM API documentation to make this setup easy and seamless.
Issue resolution
Of course, no system is perfect. Even a well-oiled machine like an InfiniBand cluster encounters unexpected issues every so often.
However, as an admin, the cluster maintenance guide is your one-stop shop. It includes a chapter describing the most frequently encountered scenarios, and how to solve them. This section includes the scenario and how to detect it (with corresponding UFM Alert Event IDs), and then a set of steps to take to reach a resolution. It covers simple and common errors such as bad ports, flapping links, and cable connection issues, as well as more complex challenges such as performance degradation or low bandwidth.
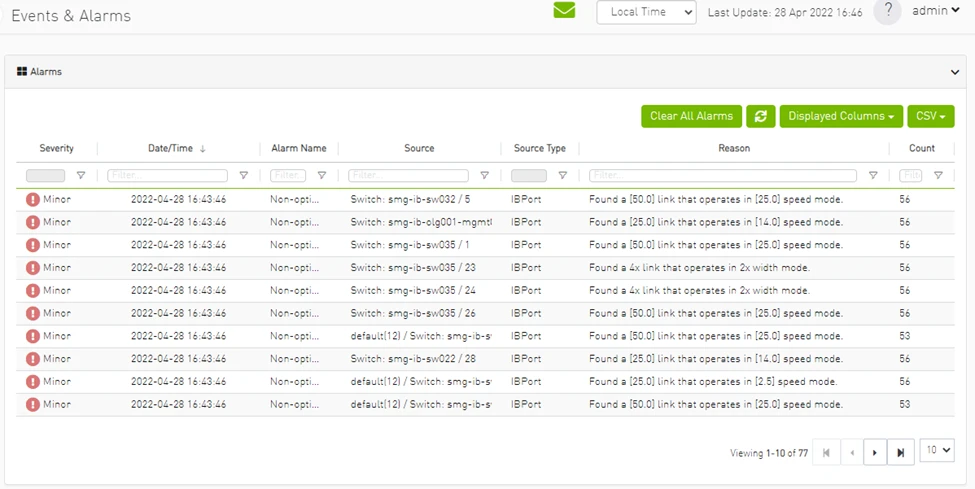 Figure 2. UFM Events & Alarms dashboard
Figure 2. UFM Events & Alarms dashboard
Summary
When building a network, performance is a key consideration, but performance and ease of use don’t have to be thought of as a tradeoff.
InfiniBand is easy to adopt, deploy, and operationalize for AI. Leveraging the power of UFM, the cluster operations and maintenance guide contains everything a network administrator needs to know. It’s a lot simpler than cracking open your networking certification textbooks as the cluster guide is less than 40 pages.
Consider choosing the simplicity of NVIDIA Quantum InfiniBand for your AI infrastructure.
Source:: NVIDIA