
In this post, we delve deeper into the inference optimization process to improve the performance and efficiency of our machine learning models during the…
In this post, we delve deeper into the inference optimization process to improve the performance and efficiency of our machine learning models during the inference stage. We discuss the techniques employed, such as inference computation graph simplification, quantization, and lowering precision. We also showcase the benchmarking results of our scene text detection and recognition models, comparing the performance of the ONNX Runtime and NVIDIA TensorRT using NVIDIA Triton Inference Server.
Finally, we summarize the importance of optimizing deep learning models for inference and the benefits of using an end-to-end NVIDIA software solution, NVIDIA AI Enterprise, for building efficient and robust scene-text-OCR systems.
The first post in this series, Robust Scene Text Detection and Recognition: Introduction, discussed the importance of robust scene text detection and recognition (STDR) in various industries and the challenges. The second post, Robust Scene Text Detection and Recognition: Implementation, discussed the implementation of an STDR pipeline using state-of-the-art deep learning algorithms and techniques like incremental learning and fine-tuning.
Inference optimization
Inference optimization is done to improve the performance and efficiency of machine learning models during the inference stage. It helps in reducing the time, computational resources, and cost required for making predictions, and can also improve accuracy in some cases.
We have used techniques like inference computation graph simplification, quantization, and lowering precision for inference optimization. These models were originally trained using the PyTorch library, exported in torchScript format, converted to the ONNX format, and then transformed into an NVIDIA TensorRT engine.
To carry out the ONNX to TensorRT conversion, we used the NGC container image for TensorRT, version 22.07. Following the conversion process, we deployed the model for inference using the NVIDIA Triton Inference Server, version 22.07. System performance was benchmarked on an NVIDIA A5000 laptop GPU with 16 GB of GPU memory.
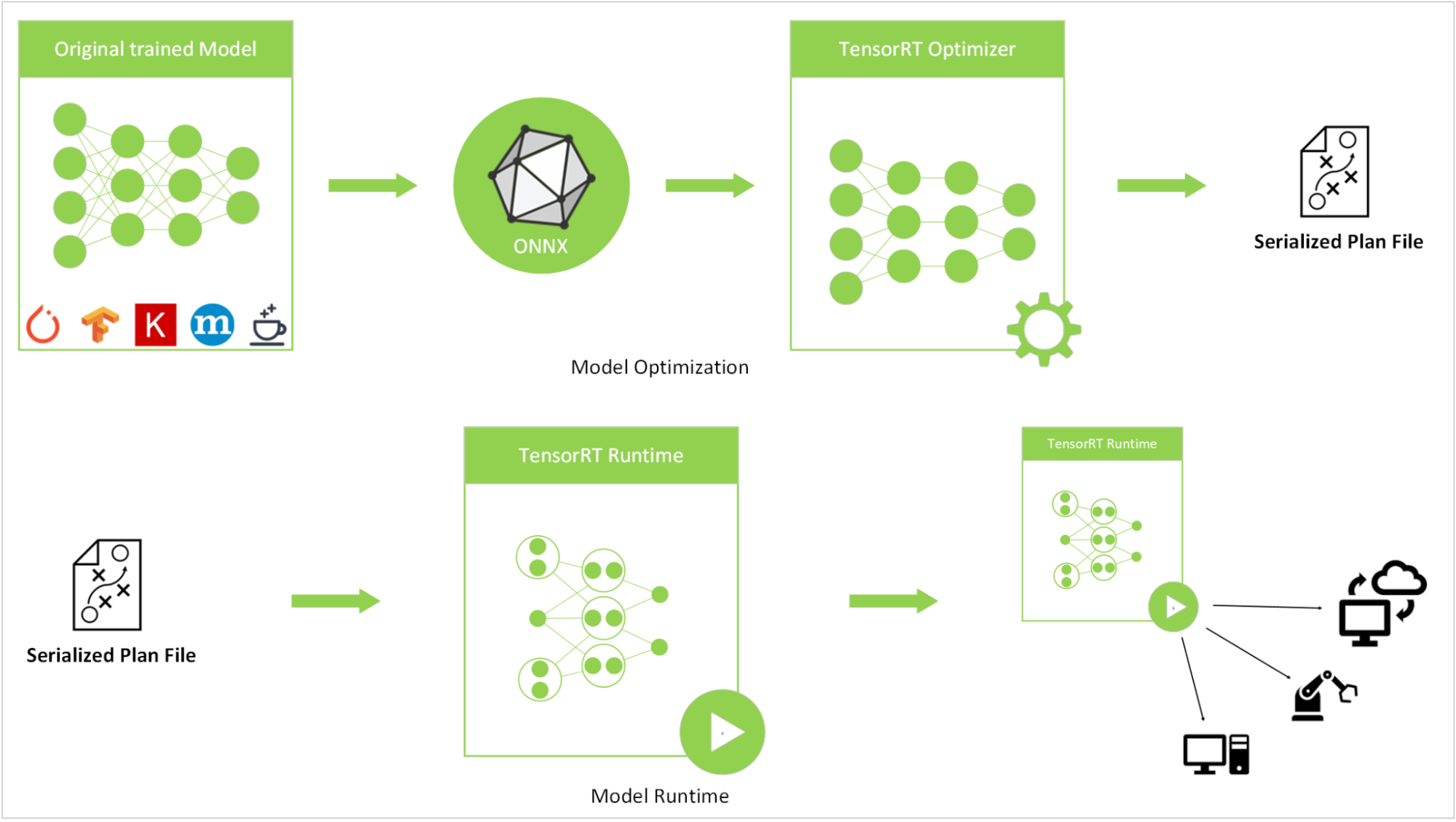 Figure 1. Inference optimization flow
Figure 1. Inference optimization flow
We discuss the details of the optimization of each building block of scene text detection and recognition (STDR) later in this post.
Scene text detection
Scene text detection is a crucial component of our scene-text-OCR system. This component takes an image of a scene as input and outputs the locations of text fields within the image. In this article, we are using the pretrained CRAFT model for general scene text detection tasks. This model, which is trained on a diverse set of images, is capable of handling dynamic input images and accurately locating text fields. The average width of the images used as input in our deployments is around 720 points. Here, we have benchmarked two image input sizes: (3,720,720) and (3,1200,1200).
Our benchmark shows around 2.3x speed-up with TensorRT compared to TorchScript for inference.
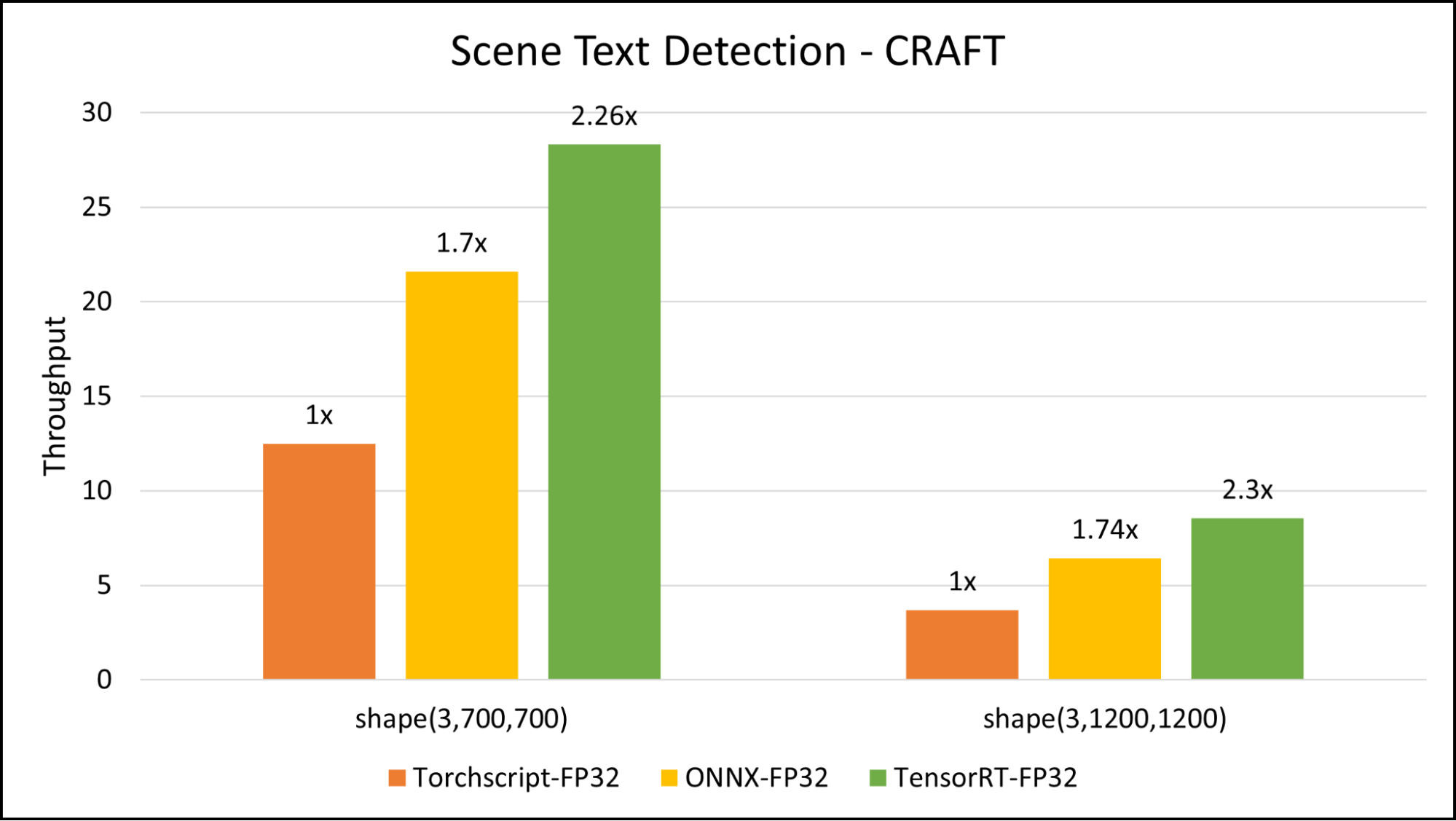 Figure 2. Triton Inference Server benchmark comparison of scene text detection CRAFT model on image sizes
Figure 2. Triton Inference Server benchmark comparison of scene text detection CRAFT model on image sizes
The deployed CRAFT model is a TensorRT engine with FP32 precision. The following code examples are a quick guide for conversion.
Create a conda environment:
$ conda create –n python=3.8 $ conda activate
Clone the CRAFT repo and install requirement.txt:
$ git clone https://github.com/clovaai/CRAFT-pytorch.git $ cd CRAFT-pytorch $ pip install –r requirement.txt
Load the model and convert it to an .onnx format that takes dynamic shapes:
input_tensor_detec = torch.randn((1, 3, 768, 768), requires_grad=False)
input_tensor_detec=input_tensor_detec.to(device="cuda”)
# Load net
net = CRAFT()
net.load_state_dict(copyStateDict(torch.load(model_path)))
net = net.cuda()
net.eval()
# Convert the model into ONNX
torch.onnx.export(net, input_tensor_detec, output_dir,
verbose=False, opset_version=11,
do_constant_folding= True,
export_params=True,
input_names=["input"],
output_names=["output", "output1"], dynamic_axes={"input": {0: "batch", 2: "height", 3: "width"}})
Simplify the ONNX graph. Use ONNX Simplifier to simplify the ONNX model. It infers the whole computation graph and then replaces the redundant operators with their constant outputs (also known as constant folding). The following code example shows the operation folding report for a graph simplification of a CRAFT model:
$ onnxsim
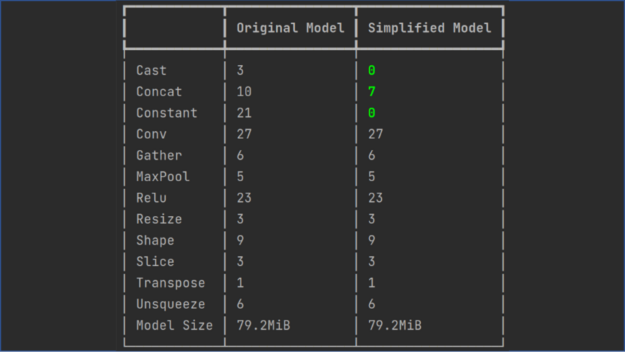 Figure 3. onnxsim report for CRAFT model
Figure 3. onnxsim report for CRAFT model
For this post, use NVIDIA TensorRT pre-configured Docker containers to convert the ONNX model to a TensorRT serialized plan file. The following code example works with the tensorrt:22.07-py3 NGC container:
~$ docker run -it --gpus all -v :/models nvcr.io/nvidia/tensorrt:22.07-py3 root@576df0ec3a49:/workspace#$ trtexec --onnx=/models/craft.onnx --explicitBatch --workspace=5000 --minShapes=input:1x3x256x256 --optShapes=input:1x3x700x700 --maxShapes=input:1x3x1200x1200 --buildOnly –saveEngine=/models/craft.engine
The following code example shows the config.pbtxt file for the scene text detection model:
name: "craft"
default_model_filename: "detec_trt.engine"
platform: "tensorrt_plan"
max_batch_size : 1
input [
{
name: "input"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "output"
data_type: TYPE_FP32
dims: [ -1, -1, 2 ]
},
{
name: "output1"
data_type: TYPE_FP32
dims: [ 32, -1, -1 ]
}
]
Scene text recognition
Scene text recognition is an integral module of the STDR pipeline. We used the PARseq algorithm, a state-of-the-art technique for efficient and customizable text recognition to achieve accurate results.
To maximize the performance of our pipeline, we converted the PARseq TorchScript model to ONNX and then further converted it to a TensorRT engine, ensuring low latency in text recognition, as each image may contain multiple text fields.
We found that using an input size of 3x32x128 for the model proved to be the optimal balance between inference time and accuracy. Figure 4 shows the benchmarking results for the PARseq model. We benchmarked around 3x acceleration compared to TorchScript inference.
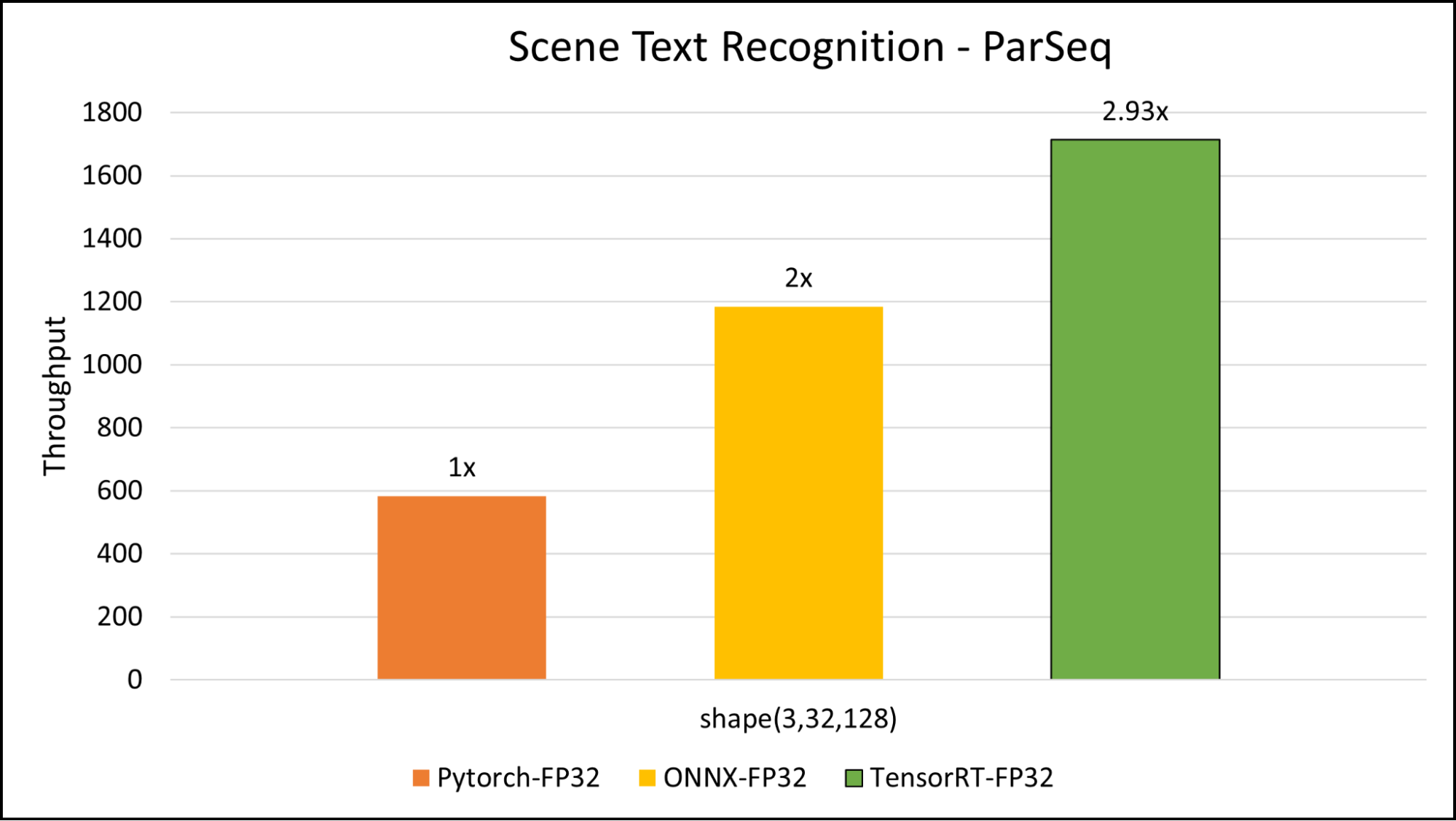 Figure 4. Triton Inference Server benchmark comparison of scene text recognition PARseq model
Figure 4. Triton Inference Server benchmark comparison of scene text recognition PARseq model
The pretrained models published by the authors work well with most of the cases. You can also fine-tune the model if you want to get more accurate output on a custom dataset. The following code examples show the important steps for conversion.
Install PARSeq:
$ git clone https://github.com/baudm/parseq.git $ pip install -r requirements.txt $ pip install -e .
You can use your own fine-tuned model or pretrained model from the model repository and convert it into .onnx format. Use an ONNX version later than 1.12.0.
from strhub.models.utils import load_from_checkpoint # To ONNX device = "cuda" ckpt_path = "..." onnx_path = "..." img = ... parseq = load_from_checkpoint(ckpt_path) parseq.refine_iters = 0 parseq.decode_ar = False parseq = parseq.to(device).eval() parseq.to_onnx(onnx_path, img, do_constant_folding=True, opset_version=14) # opset v14 or newer is required # check onnx_model = onnx.load(onnx_path) onnx.checker.check_model(onnx_model, full_check=True) ==> pass
To convert to TensorRT format, simplify the ONNX model using onnx-simplifier:
$ onnxsim
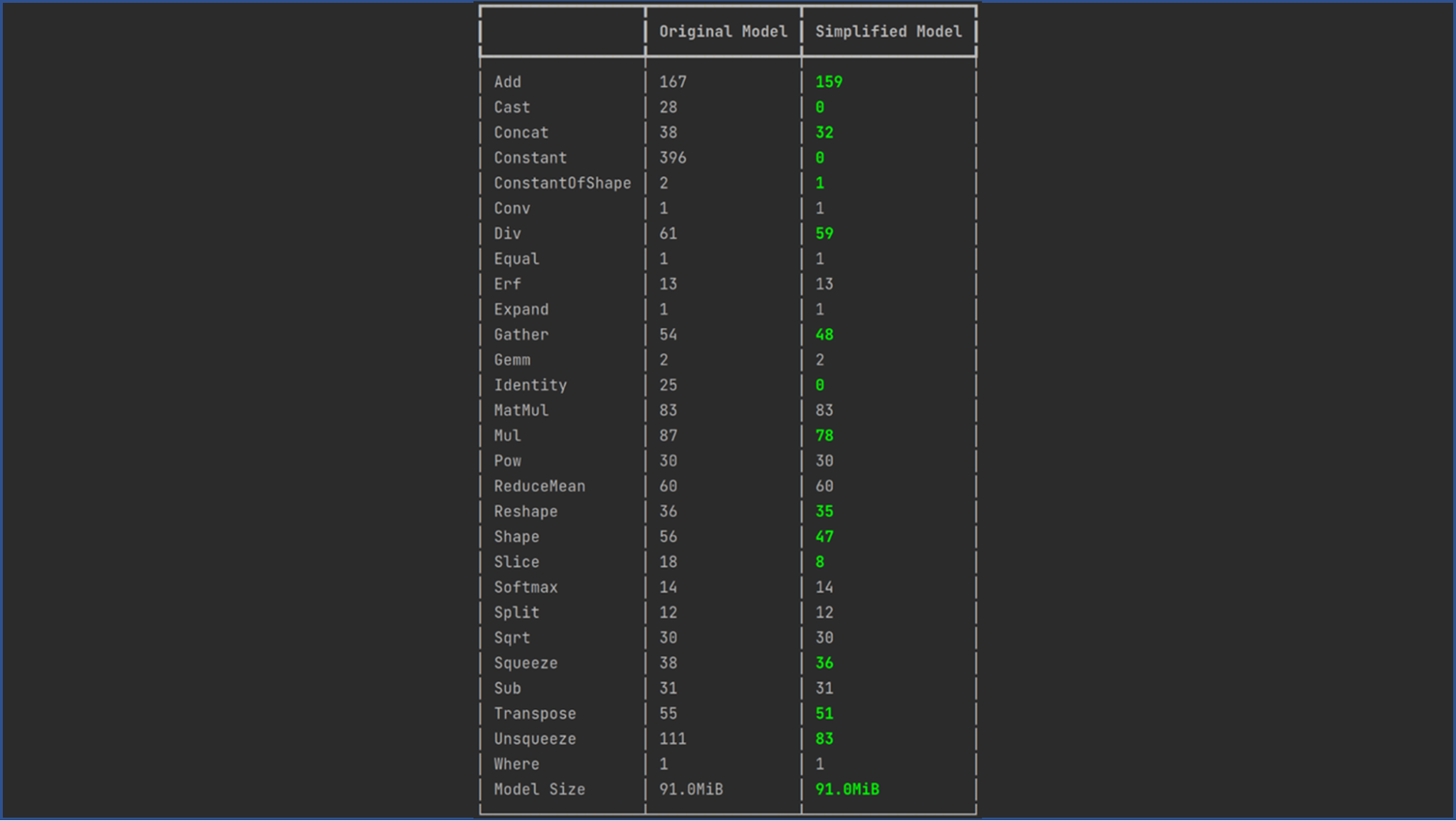 Figure 5. onnxsim report for the PARSeq model
Figure 5. onnxsim report for the PARSeq model
After converting the model to a simplified ONNX format, use the trtexec tool for the conversion. This conversion is done inside the TensorRT container version 22.07.
~$ docker run -it --gpus all -v :/models nvcr.io/nvidia/tensorrt:22.07-py3 root@576df0ec3a49:/workspace# trtexec --onnx=/models/parseq_simple.onnx --fp16 --workspace=1024 --saveEngine=/models/parseq_fp16.trt --minShapes=input:1x3x32x128 --optShapes=input:4x3x32x128 --maxShapes=input:16x3x32x128
The following code example shows the config.pbtxt file for the scene text recognition model:
name: "parseq"
max_batch_size: 16
platform: "tensorrt_plan"
default_model_filename: "parseq_exp_fp32.trt"
input {
name: "input"
data_type: TYPE_FP32
dims: [3, 32, 128]
}
output {
name: "output"
data_type: TYPE_FP32
dims: [26, 95]
}
instance_group [
{
count: 1
kind: KIND_GPU
}
]
Orchestrator
The orchestrator module is a Python backend that maintains flow and performs pre-processing for the STDR pipeline. To do the pipeline benchmarking, we used four different images with different image sizes to create custom inputs for perf_analyzer.
We created two versions of the pipeline, one pipeline using the ONNX Runtime CPU/ GPU backend and another using TensorRT plans, so that the pipeline can work in both GPU and non-GPU environments. We benchmarked the onnx_backend pipeline and tensorrt_plan pipeline on an NVIDIA RTX A5000 laptop GPU (16 GB) using NVIDIA Triton Inference Server.
The input sample for the benchmark has four different images with sizes (3x472x338), (3x3280x2625), (3x512x413), and (3x1600x1200).
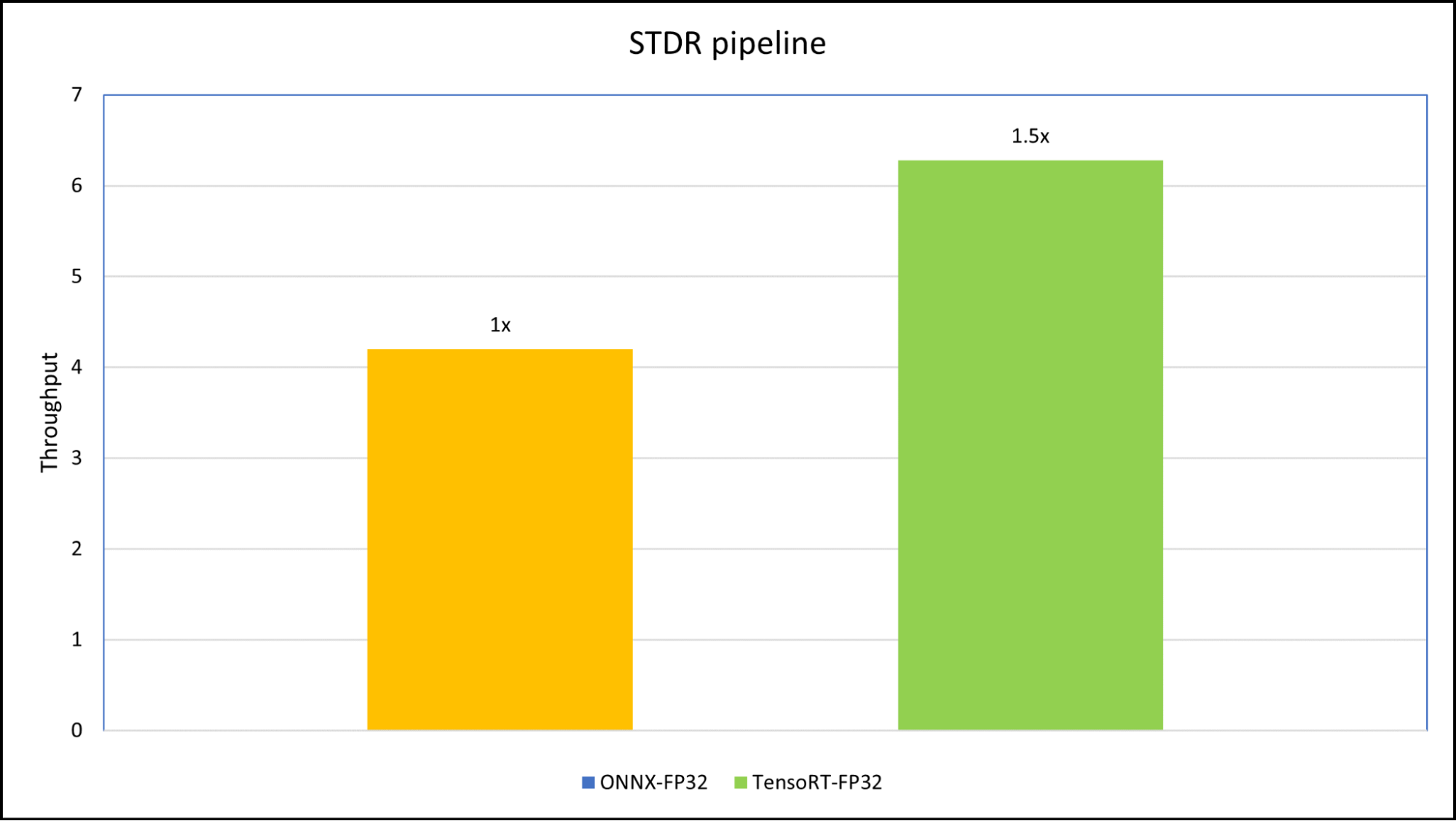 Figure 6. Triton Inference Server benchmark comparison of scene text recognition and detection on ONNX runtime and TensorRT plan
Figure 6. Triton Inference Server benchmark comparison of scene text recognition and detection on ONNX runtime and TensorRT plan
The orchestrator is a Python backend module that coordinates between the scene text detection and scene text recognition models. The configuration file for the orchestrator is as follows:
name: "pipeline"
backend: "python"
max_batch_size: 1
input [
{
name: "input"
data_type: TYPE_UINT8
dims: [ -1, -1, 3 ]
}
]
output [
{
name: "output"
data_type: TYPE_STRING
dims: [ -1 ]
}
]
instance_group [
{
count: 1
kind: KIND_GPU
}
]
Summary
In summary, the deployment of scene text detection and recognition systems requires careful consideration of real-world scenarios, and optimizing deep learning models for inference is crucial.
To ensure production-ready optimization and performance, NVIDIA offers an end-to-end software solution, NVIDIA AI Enterprise, that consists of best-in-class AI software and tools including TensorRT and Triton Inference Server for easy access to build enterprise AI applications. The solution is instrumental in achieving low latency and high-performance inference across various devices.
By using these technologies, you can build efficient and robust scene-text-OCR systems for a range of applications.
Source:: NVIDIA