
To make scene text detection and recognition work on irregular text or for specific use cases, you must have full control of your model so that you can do…
To make scene text detection and recognition work on irregular text or for specific use cases, you must have full control of your model so that you can do incremental learning or fine-tuning as per your use cases and datasets. Keep in mind that this pipeline is the main building block of scene understanding, AI-based inspection, and document processing platforms. It should be accurate and have low latency.
The first post in this series, Robust Scene Text Detection and Recognition: Introduction, discussed the importance of robust scene text detection and recognition (STDR) in various industries and the challenges. The third post, Robust Scene Text Detection and Recognition: Inference Optimization, covers production-ready optimization and performance for your STDR pipeline.
For this post, we decided to use state-of-the-art, highly accurate, deep-learning models. To ensure accuracy and keep low end-to-end latency, we performed model inference optimization using tools and frameworks like NVIDIA TensorRT and ONNX Runtime. To ensure standard model deployment and execution, in addition to high-performing inference with scalability, we decided to use NVIDIA Triton Inference Server.
To train our models, we used Docker container images from the NGC catalog, a hub for GPU-optimized AI and ML software. NGC containers leverage the power of NVIDIA GPUs and can run in virtual machines (VMs) configured with NVIDIA virtual GPU (vGPU) software in NVIDIA vGPU and GPU pass-through deployments. These containers are pre-configured with optimized libraries for SDKs like PyTorch and TensorRT.
To enable high-performance inference across the cloud, on-premises, and at the edge, we also made use of the Triton Inference Server Docker container. This container enables multiple models from different frameworks to be executed simultaneously on a single GPU or CPU. On a multi-GPU server, Triton Inference Server automatically creates an instance of each model on each GPU to maximize utilization.
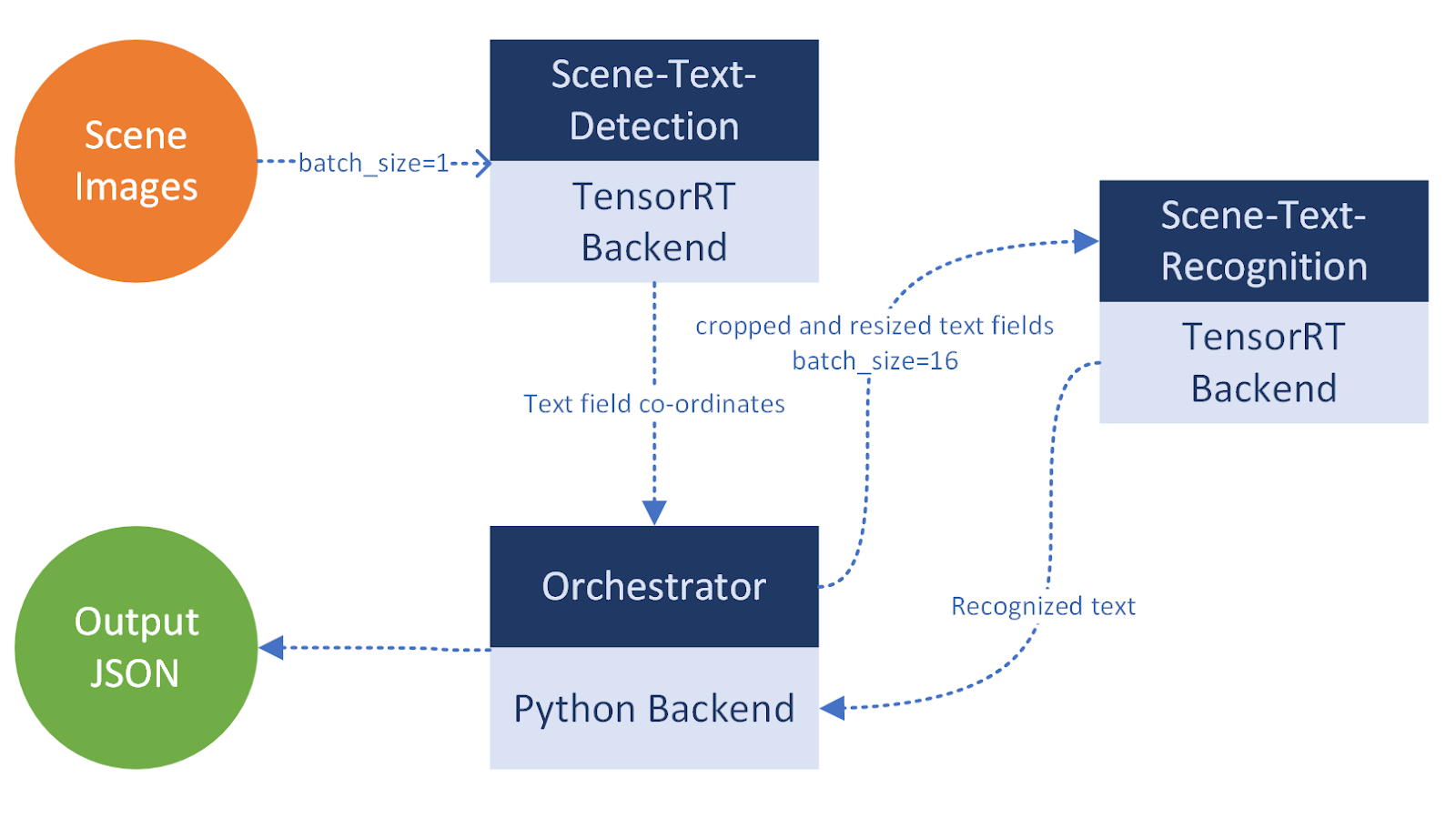
There are three building blocks of the STDR pipeline:
- Scene text detection
- Scene text recognition
- Orchestration
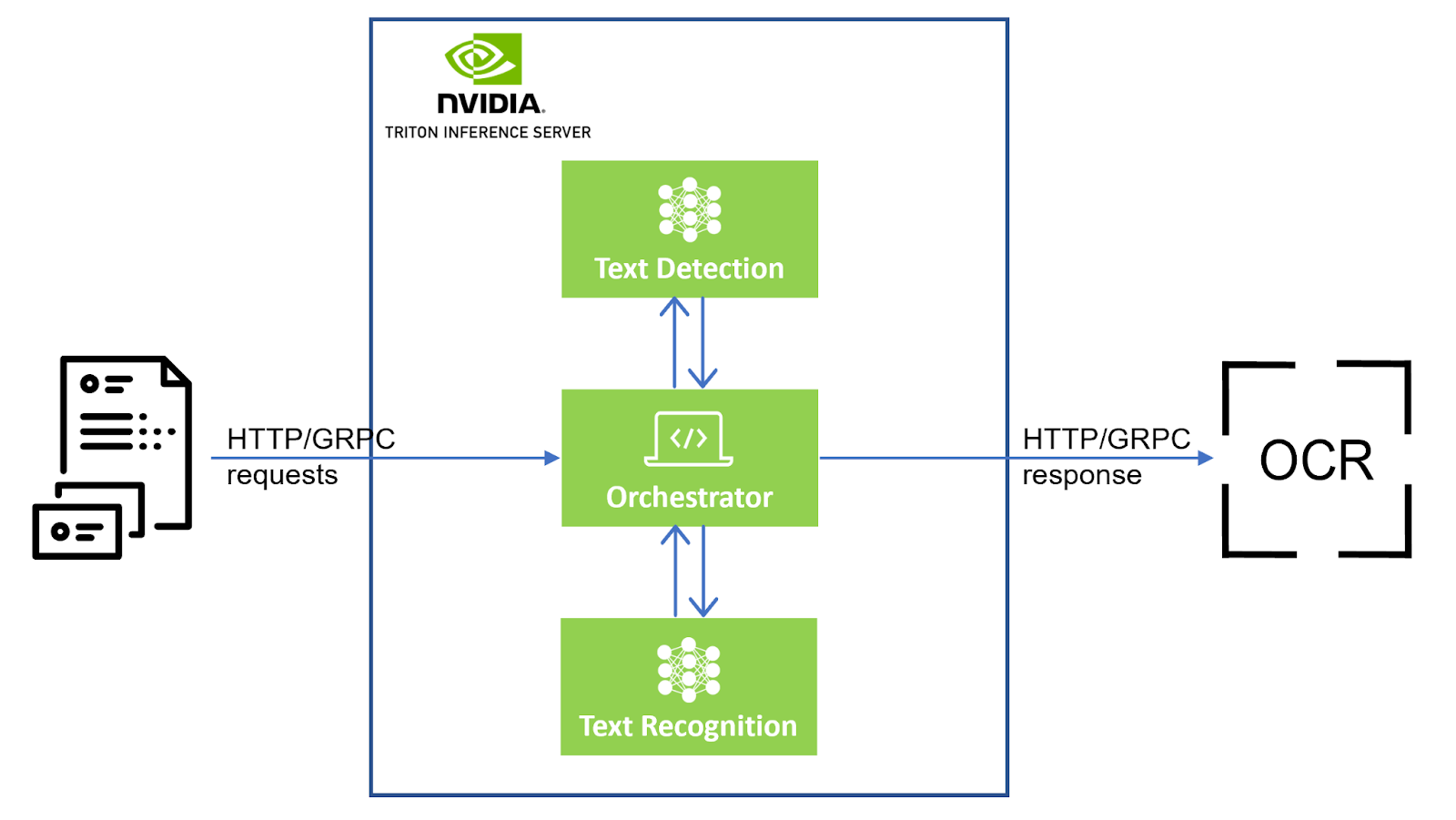
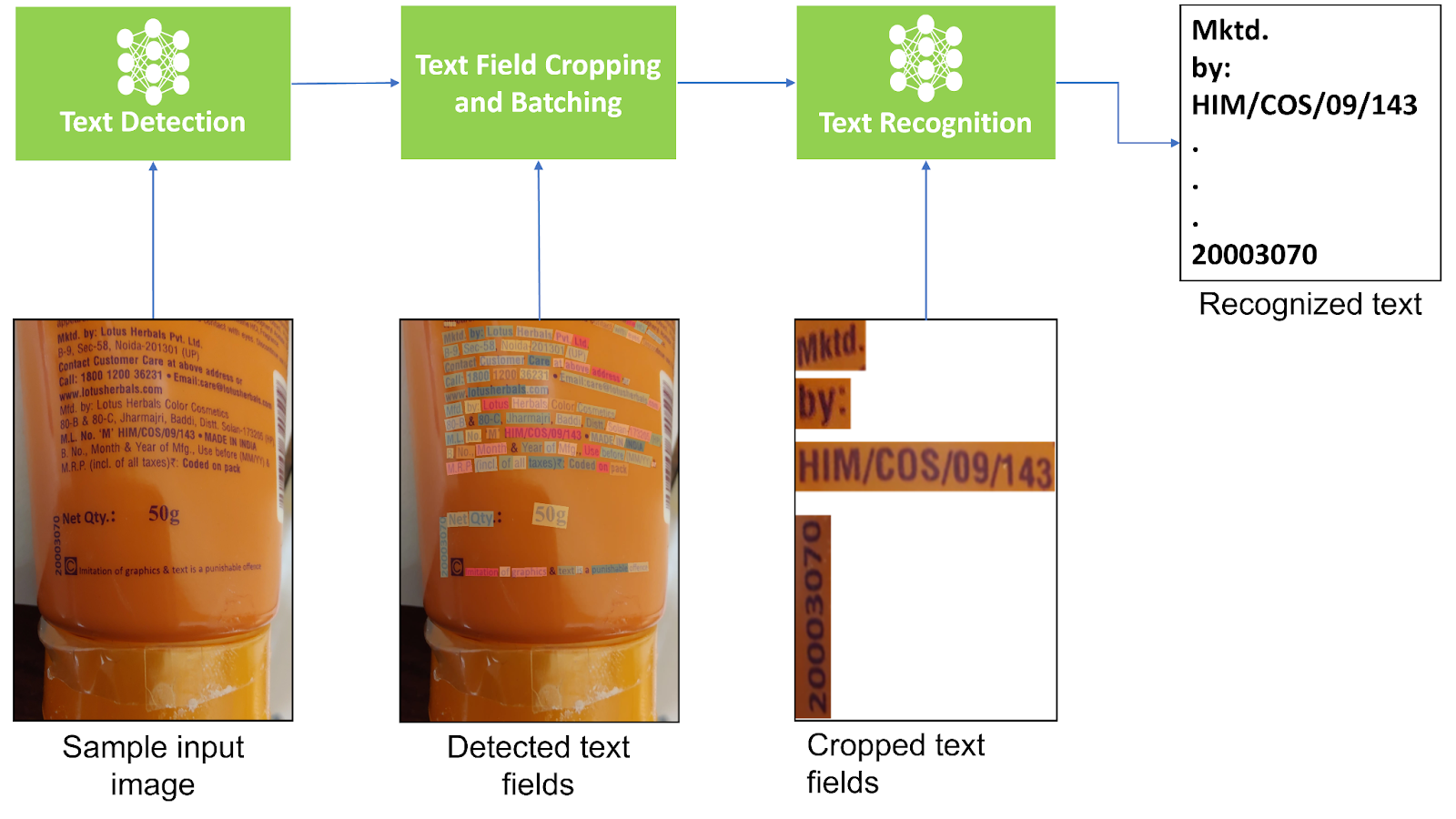
Scene text detection
In the current pipeline, there are the following options for text detection algorithms:
- FCENet
- CRAFT
- TextFuseNet
You can train and fine-tune FCENet and TextFuseNet for particular use cases. However, CRAFT cannot be trained or fine-tuned as Clova AI has not published the training code for IP reasons. Our general-purpose pipeline uses the pretrained CRAFT model, which is trained on synthText, IC13, and IC17. For more information, see Character Region Awareness for Text Detection.
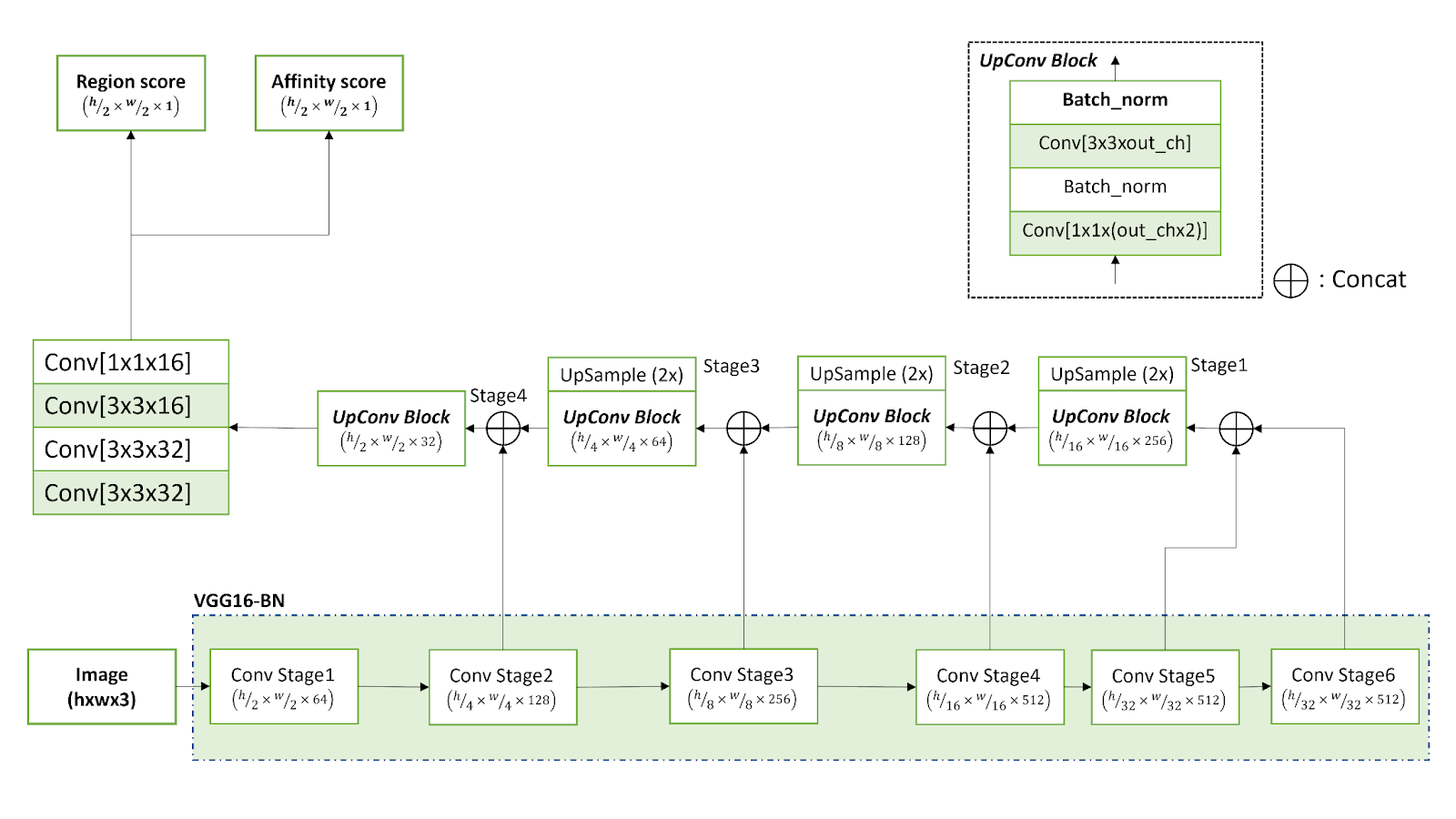
This network uses a fully convolutional network architecture based on the VGG-16 model, which encodes the input into a distinct feature representation. The decoding segment of CRAFT is similar to that of UNet and includes skip connections that aggregate low-level features.
CRAFT predicts two separate scores for each character:
- Region score: Provides information regarding the area of the character.
- Affinity score: Reveals the degree to which characters are combined into a single entity.

Scene text recognition
In this post, we use the state-of-the-art Scene Text Recognition with the Permuted Autoregressive Sequence (PARseq) algorithm. For more information, see Scene Text Recognition with Permuted Autoregressive Sequence Models.
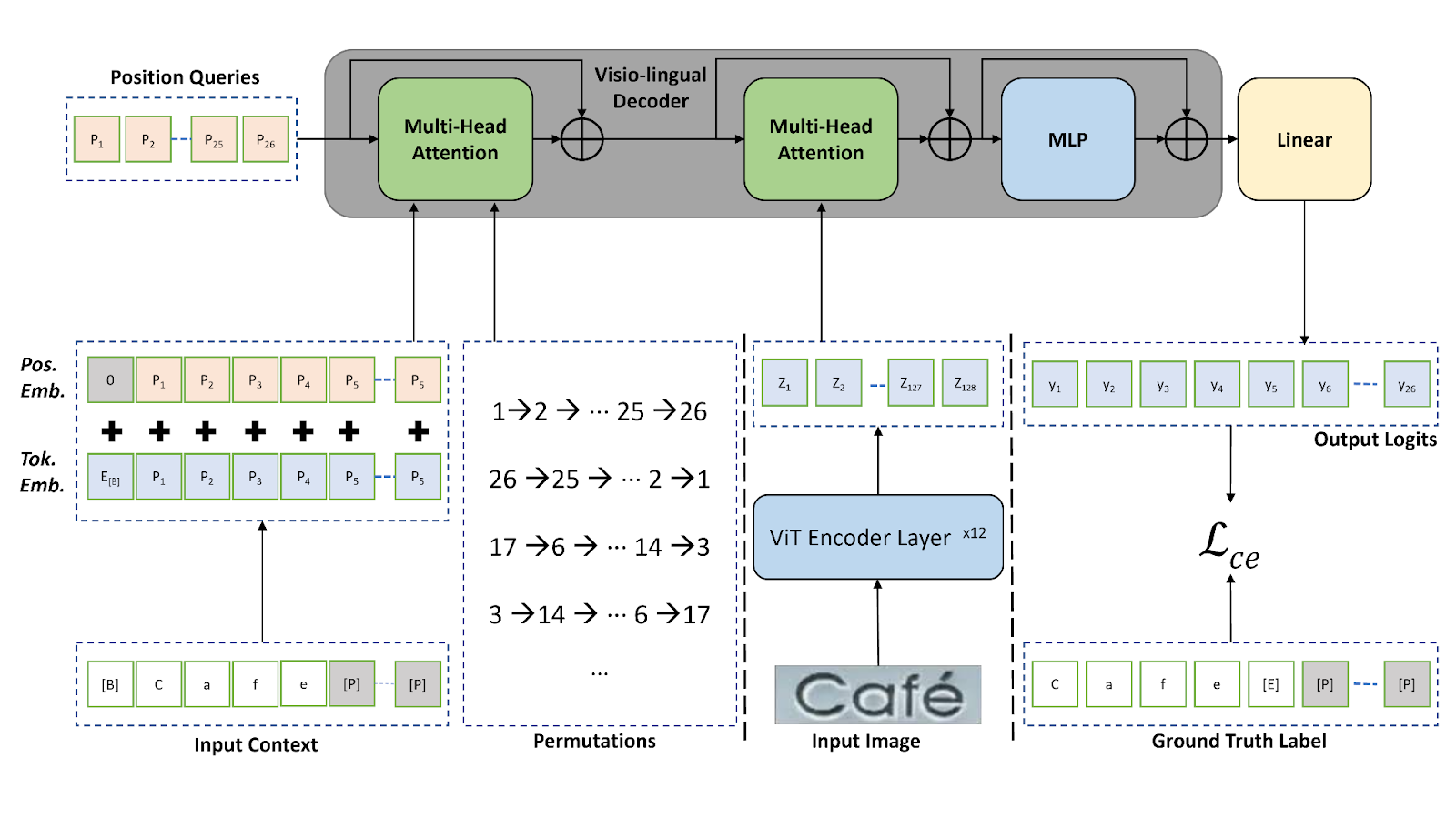
Published, pretrained models are trained on several datasets like MJSynth and SynthText, COCO-Text, RCTW17, Uber-Text, ArT, LSVT, and MLT19. We also used incremental learning techniques to fine-tune pretrained models on custom datasets.
Orchestrator
The orchestrator module is the control unit of the pipeline. This module is responsible for coordinating between scene text detection and scene text recognition.
- It receives an input image from a request.
- That image is pre-processed and sent to the scene text detection module.
- The detection module returns the locations of the text fields present in the input image.
- The Orchestrator crops out the text fields from the input image into a list of
ndarrays. - It creates batches from the cropped text images of a predefined batch size and sends one batch at a time to the text recognition module.
- The recognition module returns STR output with a confidence score for each of the cropped text images within that batch.
The orchestrator maintains a track of each text field location, corresponding STR output, and confidence score. Using all this information, it creates a response JSON.
Summary
In this post, we discussed the implementation of an STDR pipeline using state-of-the-art deep learning algorithms and techniques like incremental learning and fine-tuning. We used the CRAFT algorithm for text detection and the PARSeq algorithm for text recognition. We designed a distinct orchestration module to facilitate coordination between text detection and recognition. This post also highlighted the use of NVIDIA TensorRT, ONNX Runtime, and NVIDIA Triton Inference Server for model optimization and high-performance inference serving.
For more information, see the Robust Scene Text Detection and Recognition: Introduction and Robust Scene Text Detection and Recognition: Inference Optimization posts in this series.
Source:: NVIDIA