
On Mondays throughout the year, we’ll be releasing new models. This week, we released the NVIDIA-optimized DePlot model, which you can experience directly…
On Mondays throughout the year, we’ll be releasing new models. This week, we released the NVIDIA-optimized DePlot model, which you can experience directly from your browser.
NVIDIA Foundation Models and Endpoints provides access to a curated set of community and NVIDIA-built generative AI models to experience, customize, and deploy in enterprise applications.
If you haven’t already, try the leading models like Nemotron-3, Mixtral 8X7B, Llama 2, and Stable Diffusion in the NVIDIA AI playground.
DePlot
A leap in visual language reasoning, DePlot by Google Research enables comprehension of charts and plots when coupled with a large language model (LLM). As opposed to prior multimodal LLMs that are trained end-to-end for plot de-rendering and numerical reasoning, this approach breaks down the problem into the following steps:
- Plot-to-text translation using a pretrained image-to-text model
- Textual reasoning using an LLM
Specifically, DePlot refers to the image-to-text Transformer model in the first step, used for modality conversion from a plot to the text format. The linearized tables generated by DePlot can be directly ingested as part of a prompt into an LLM in the second step to facilitate reasoning.
Previous state-of-the-art (SOTA) models required at least tens of thousands of human-written examples to accomplish such plot or chart comprehension while still being limited in their reasoning capabilities on complex queries.
Using this plug-and-play approach, the DePlot+LLM pipeline achieves over 29.4% improvement over the previous SOTA on the ChartQA benchmark with just one-shot prompting!
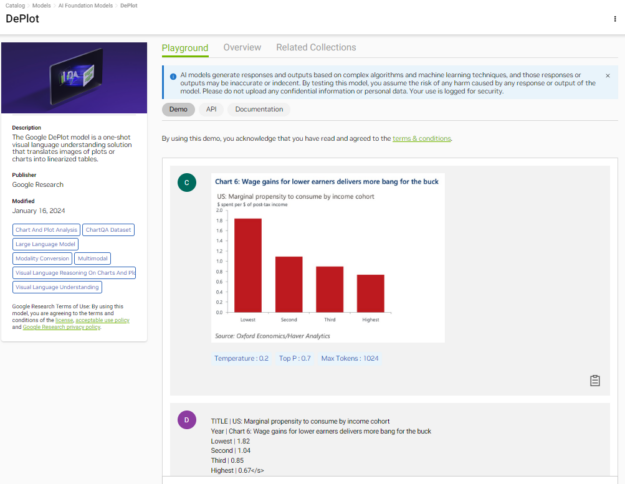 Figure 1. DePlot converts a plot into a structured table
Figure 1. DePlot converts a plot into a structured table
Figure 1 shows how DePlot converts a plot into a structured table that can be used as context for LLMs to answer reasoning-based questions. Try DePlot now.
Using the model in a browser
You can now experience DePlot directly from your browser using a simple user interface on the DePlot playground on the NGC catalog. The following video shows the results generated from the models running on a fully accelerated stack.
Video 1. NVIDIA AI Foundation model interface
The video shows the NVIDIA AI Foundation model interface used to extract information from a graph using DePlot running on a fully accelerated stack.
Using the model with the API
If you would rather use the API to test out the model, we’ve got you covered. After you sign in to the NGC catalog, you have access to NVIDIA cloud credits that enable you to truly experience the models at scale by connecting your application to the API endpoint.
The following Python example uses base64 and requests modules to encode the plot image and issue requests to the API endpoint. Before proceeding, ensure that you have an environment capable of executing Python code, such as a Jupyter notebook.
Obtain the NGC catalog API key
On the API tab, select Generate Key. If you haven’t registered yet, you are prompted to sign up or sign in.
Set the API key in your code:
# Will be used to issue requests to the endpoint API_KEY = “nvapi-xxxx“
Encode your chart or graph in base64 format
To provide an image input as part of your request, you must encode it in base64 format.
# Fetch an example chart from ChartQA dataset !wget -cO - https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/5090.png > chartQA-example.png # Encode the image into base64 format import base64 with open(os.path.join(os.getcwd(), "chartQA-example.png"), "rb") as image_file: encoded_string = base64.b64encode(image_file.read())
As an option, you can visualize the chart:
from IPython import display display.Image(base64.b64decode(encoded_string))
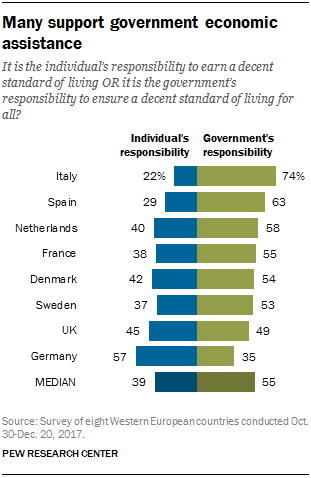 Figure 2. Barchart example for table value generation
Figure 2. Barchart example for table value generation
Send an inference request
import requests
invoke_url = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/functions/3bc390c7-eeec-40f7-a64d-0c6a719985f7"
fetch_url_format = "https://api.nvcf.nvidia.com/v2/nvcf/pexec/status/"
# Ensure that you have configured API_KEY
headers = {
"Authorization": "Bearer {}".format(API_KEY),
"Accept": "application/json",
}
# To re-use connections
session = requests.Session()
# The payload consists of a base64 encoded image accompanied by header text.
payload = {
"messages": [
{
"content": "Generate underlying data table of the figure below: ".format(encoded_string.decode('UTF-8')),
"role": "user"
}
],
"temperature": 0.1,
"top_p": 0.7,
"max_tokens": 1024,
"stream": False
}
response = session.post(invoke_url, headers=headers, json=payload)
while response.status_code == 202:
request_id = response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
response = session.get(fetch_url, headers=headers)
response.raise_for_status()
response_body = response.json()
print(response_body)
".format(encoded_string.decode('UTF-8')),
"role": "user"
}
],
"temperature": 0.1,
"top_p": 0.7,
"max_tokens": 1024,
"stream": False
}
response = session.post(invoke_url, headers=headers, json=payload)
while response.status_code == 202:
request_id = response.headers.get("NVCF-REQID")
fetch_url = fetch_url_format + request_id
response = session.get(fetch_url, headers=headers)
response.raise_for_status()
response_body = response.json()
print(response_body)
The output looks like the following:
{'id': '4423f30d-2d88-495d-83cc-710da97889e3', 'choices': [{'index': 0, 'message': {'role': 'assistant', 'content': "Entity | Individuals responsibility | Government's responsibility <0x0A> MEDIAN | 39.0 | 55.0 <0x0A> Germany | nan | 35.0 <0x0A> UK | 45.0 | 49.0 <0x0A> Sweden | 37.0 | 53.0 <0x0A> Denmark | 42.0 | 54.0 <0x0A> France | 38.0 | 55.0 <0x0A> Netherla nns | 40.0 | 58.0 <0x0A> Spain | 29.0 | 63.0 <0x0A> Italy | 22.0 | 74.0"}, 'finish_reason': 'stop'}], 'usage': {'completion_tokens': 149, 'prompt_tokens': 0, 'total_tokens': 149}}
The response body includes the output of DePlot along with additional metadata. The output is generated left-to-right autoregressively as a textual sequence in Markdown format, with separators -, |, and (newline).
Visualize the output table
response_table = response_body['choices'][0]['message']['content']
# Replace the <0x0A> with n for better readability
print(response_table.replace("<0x0A>", "n"))
The output looks like the following:
Entity | Individuals responsibility | Government's responsibility MEDIAN | 39.0 | 55.0 Germany | nan | 35.0 UK | 45.0 | 49.0 Sweden | 37.0 | 53.0 Denmark | 42.0 | 54.0 France | 38.0 | 55.0 Netherla nns | 40.0 | 58.0 Spain | 29.0 | 63.0 Italy | 22.0 | 74.0
In this case, the response was largely accurate. This output can be used as part of the input context to an LLM for a downstream task like question answering (QA).
Enterprise-grade AI runtime for model deployments
Security, reliability, and enterprise support are critical when AI models are ready to deploy for business operations.
NVIDIA AI Enterprise, an end-to-end AI runtime software platform, is designed to accelerate the data science pipeline and streamline the development and deployment of production-grade generative AI applications.
NVIDIA AI Enterprise provides the security, support, stability, and manageability to improve the productivity of AI teams, reduce the total cost of AI infrastructure, and ensure a smooth transition from POC to production.
Get started
Try the DePlot model through the UI or the API. If this model is the right fit for your application, optimize the model with NVIDIA TensorRT-LLM.
If you’re building an enterprise application, sign up for an NVIDIA AI Enterprise trial to get support for taking your application to production.
Source:: NVIDIA