
For robotic agents to interact with objects in their environment, they must know the position and orientation of objects around them. This information describes…
For robotic agents to interact with objects in their environment, they must know the position and orientation of objects around them. This information describes the six degrees of freedom (DOF) pose of a rigid body in 3D space, detailing the translational and rotational state.
Accurate pose estimation is necessary to determine how to orient a robotic arm to grasp or place objects in a specific way. Use cases include robotic manipulation for pick-and-place operations, especially applicable in warehouse scenarios for tasks like box packing, part loading, and food packaging. Knowing an object’s pose is also crucial for robot-to-human handoff and is useful in healthcare, retail, and household scenarios.
NVIDIA developed Deep Object Pose Estimation (DOPE) to find the six DOF pose of an object. In this post, we show how to generate synthetic data to train a DOPE model for an object.
Deep Object Pose Estimation
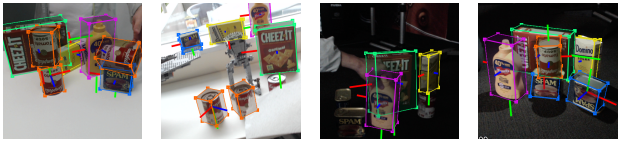 Figure 1. DOPE estimating six DOF poses of objects from an RGB image
Figure 1. DOPE estimating six DOF poses of objects from an RGB image
DOPE is a one-shot DNN developed by NVIDIA that estimates six DOF poses of objects of interest from an RGB image to enable robotic manipulation of objects in an environment. It is trained only on synthetic data and requires a textured 3D model. It provides enough accuracy for real-world grasping and gripper manipulation, with a tolerance of 2 cm.
DOPE is an instance-level model, meaning a DOPE model must be trained specifically for each object type within a class. For example, we can’t train a single DOPE model to detect all types of chairs and instead must train one model per chair type.
As another example, if an application is detecting four geometrically similar boxes of different colors, four instances of DOPE models are required for inference—one trained specifically on each colored box.
Advantages of DOPE
- It can be trained entirely on synthetic data, reducing data collection and annotation costs.
- Handles object occlusion.
- Reduces the reality gap challenge by combining domain randomized and photorealistic synthetic data for training.
- It works on different camera intrinsics without retraining through using the Perspective-n-point (PnP) algorithm.
- DOPE is supported in NVIDIA Isaac ROS to provide GPU-accelerated object pose estimation.
Reality gap challenge
Networks trained only on synthetic data often perform poorly on real-world data. Techniques like fine-tuning or domain randomization help improve performance.
Domain randomization is the method of varying parameters like scene lighting, scale, pose, color, and texture of objects in a simulation environment. This is done to provide a sufficient variety of domain parameters to the neural network to improve generalization to real-world environments. This way, real data appears as just another variation to the network.
DOPE bridges the reality gap by combining domain randomized and photorealistic synthetic data for training, and generalizes well to real-world use cases.
Architecture
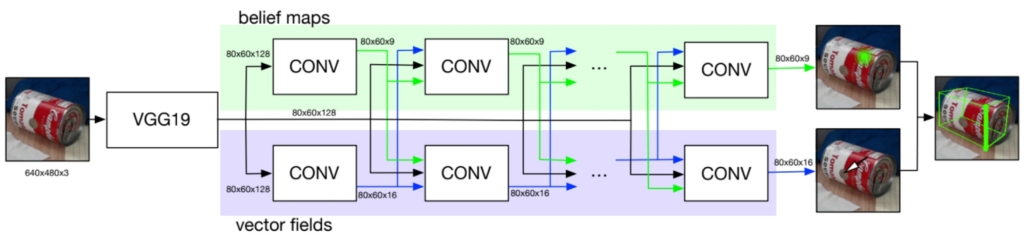 Figure 2. Overview of DOPE network architecture
Figure 2. Overview of DOPE network architecture
DOPE is a one-shot fully convolutional neural network, inspired by convolutional pose machines (CPMs) and a multi-person pose estimator. The architecture consists of a standard CNN such as VGG19 or RESNET with additional convolution layers.
For a comprehensive understanding of the DOPE architecture and data generation pipeline, refer to Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects.
Dataset
NVIDIA provides pretrained DOPE models trained on the NVIDIA Household Objects for Pose Estimation (HOPE) dataset. It is a collection of 28 toy grocery objects in varying environments and is part of the Benchmark for 6D Object Pose Estimation.
Being instance-level, DOPE must be trained with a dataset targeting objects of interest relevant to the application. To generate a dataset for training DOPE, a 3D model of the object is required. 3D object models can be generated using BundleSDF. The method, developed by NVIDIA, uses monocular RGBD cameras and removes the need for expensive 3D sensors.
Data generation
Synthetic data can be generated for DOPE using NVIDIA Isaac Sim for domain randomization. We focus on two datasets—MESH and DOME—and implement randomization techniques similar to those shown for these datasets in the NViSII paper.
These datasets add flying distractors to the scene around the object of interest and randomize lighting conditions, distractors’ colors, and materials. DOME uses fewer distractors than MESH and provides more realistic backgrounds.
 Figure 3. Example of DOME data (left) and MESH data (right)
Figure 3. Example of DOME data (left) and MESH data (right)
Information on how to use Isaac Sim to create training data for DOPE is available in NVIDIA docs.
You can specify the number of images you want to generate of each type (MESH and DOME). A good MESH / DOME split depends on the use case. Experiment to find heuristics that work well for your model (for instance, 25 / 75 between MESH / DOME). If you’re generating data and training DOPE on a single object, a training dataset of around 20k images is generally enough.
The generated dataset includes images and annotated JSON files. Each JSON file contains information about the object, including object class, position, orientation, and visibility in the corresponding image. Visibility represents how much of the object is visible (in the case of occlusions) and can be used to filter images for training.
This data generation method using Isaac Sim can also write data in a format similar to the YCB Video Dataset, which can then be used to train other 6D pose estimation models.
Object symmetry
DOPE is trained on cuboid corners that bound an object of interest. Rotational symmetries in this object could result in multiple frames that are identical pixel-wise but marked by different cuboid corners.
Watch this Deep Object Pose video on GitHub to learn more.
The Isaac Sim data generation method doesn’t explicitly handle rotational symmetries at the moment. However, NVIDIA also provides synthetic data generation scripts using NViSII that can handle symmetry.
Training DOPE
After you’ve generated your training dataset, NVIDIA provides a script to train DOPE. You can point the script to your training data and specify the batch size and number of epochs you want to train your model for.
The script saves useful training information (including loss graphs and belief maps) which you can view using TensorBoard.
Inference and evaluation
After you’ve trained your DOPE model, you can run inference on a test dataset. Depending on the images in your test data, you can specify configuration parameters in the provided configuration files or write your own.
Include the physical dimensions of the object of interest in the object config file (I used a 3D viewer online to load the 3D model and find the dimensions). The inference workflow uses these dimensions to generate results with bounding boxes around the detected objects.
 Figure 4. Qualitative result showing a bounding box around an object with an accurate pose from DOPE
Figure 4. Qualitative result showing a bounding box around an object with an accurate pose from DOPE
After running inference, we provide an evaluation workflow to evaluate the performance of your model quantitatively. Ground truth data predicted results from the inference step and a 3D model of the object of interest (in .obj format) are required for evaluation. The object’s 3D model is rendered to calculate the 3D error between ground truth and predicted results.
The ADD metric is used and we provide two options for calculating error:
- Average distance (ADD) is the average distance calculated using the closest point distance between the predicted pose and the ground-truth pose.
- Cuboid distance calculates the average distance using the eight cuboid points of the 3D models (ground truth) and predicted cuboid points. This is faster to calculate than ADD but less accurate.
With domain randomized data alone for an arbitrary object, the highest area under the curve (AUC) observed was 66.64 for 300k images. 62.94 AUC was observed when using a dataset of 600k photorealistic images alone. Accuracy was highest when domain randomized and photorealistic synthetic images were combined (77.00 AUC).
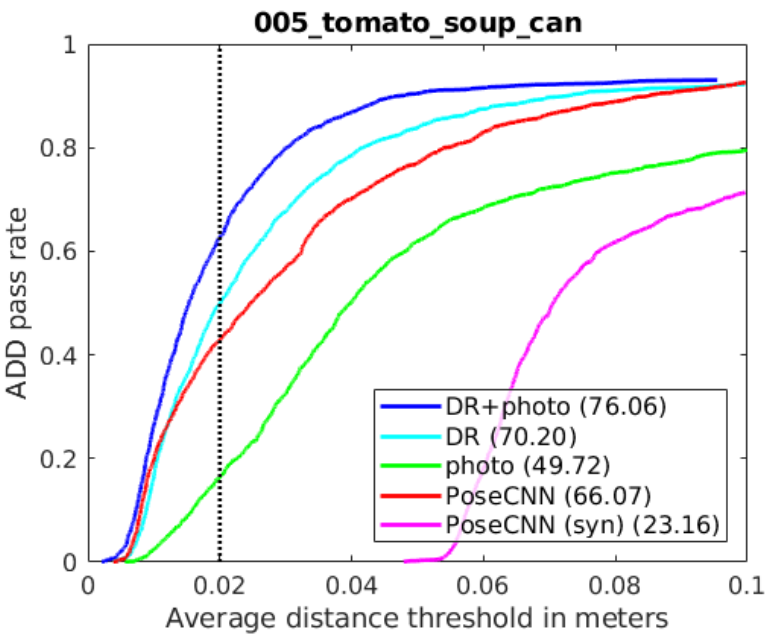 Figure 5. Accuracy-threshold curve for DOPE compared with PoseCNN for an object on the YCB-Video dataset
Figure 5. Accuracy-threshold curve for DOPE compared with PoseCNN for an object on the YCB-Video dataset
DOPE has been trained on synthetic images only. Yet it still performs well on scenes captured with a different camera, even when there are occlusions and extreme lighting changes. Its performance is better than PoseCNN and BB8, which have been trained on real data or a combination of synthetic and real data.
For a direct comparison, five objects were selected from the YCB dataset, and DOPE achieved a higher AUC than PoseCNN for four of the five objects.
More details can be found in the DOPE paper. Check out our GitHub for information on inference and evaluation.
Using Isaac ROS pose estimation
Isaac ROS provides a ROS 2 package for pose estimation using DOPE. It performs GPU-accelerated inference using NVIDIA Triton or NVIDIA TensorRT with Isaac ROS DNN Inference.
After training your DOPE model, you can run inference using this package on NVIDIA Jetson or a system with an NVIDIA GPU.
You can also perform inference on live images from a camera stream, however, this it is a compute-intensive task. Pose estimation is done at a lower frame rate than the camera input rate. Our DOPE graph runs at 39.8 FPS on an NVIDIA Jetson AGX Orin and 89.2 FPS on an NVIDIA RTX 4060 Ti—based on the Isaac ROS Benchmark workflow.
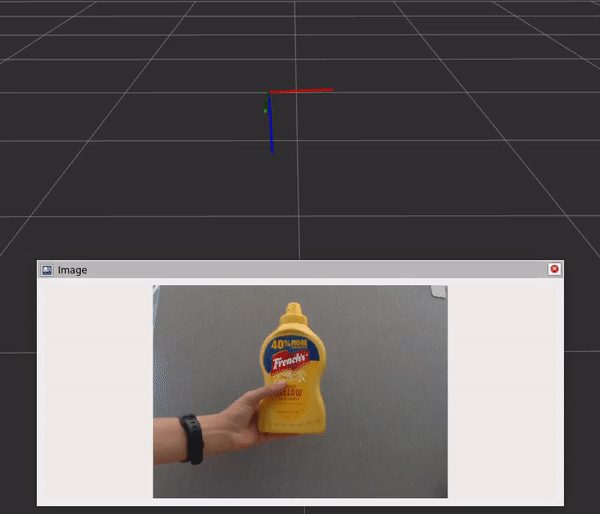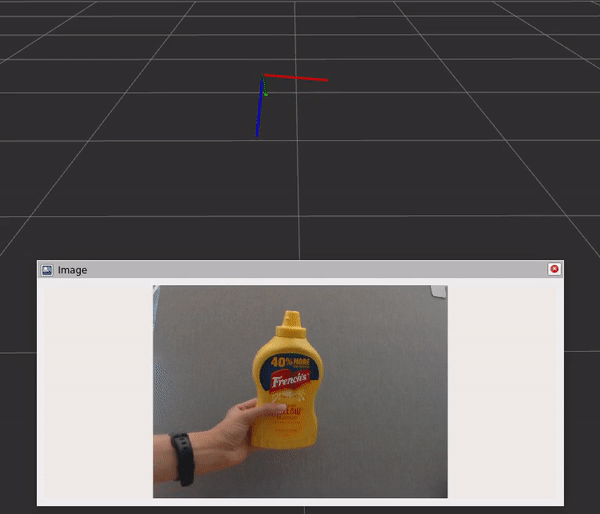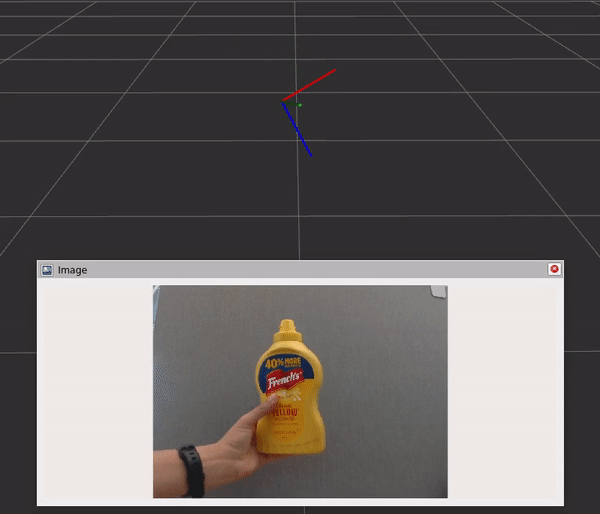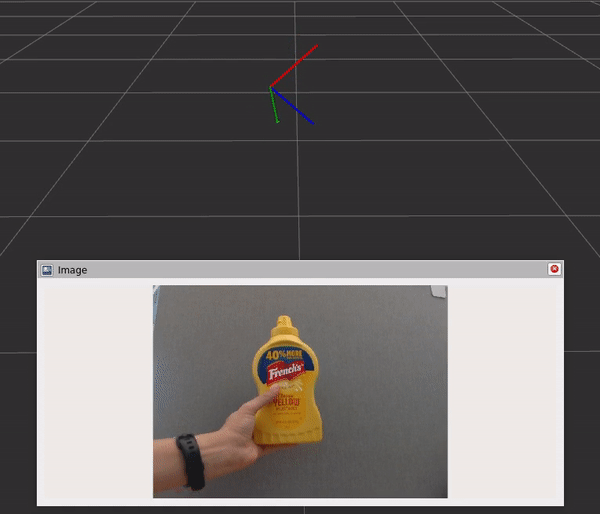 Fig 6. Running Isaac ROS DOPE with live camera input and visualizing pose on RViz
Fig 6. Running Isaac ROS DOPE with live camera input and visualizing pose on RViz
The graph includes three components and steps:
- The DNN image encoder node turns a raw image into a resized, normalized tensor.
- TensorRT node converts an input tensor into a tensor of belief maps.
- The DOPE decoder node converts a belief map into an array of poses.
Learn more about the performance of different Isaac ROS packages and benchmarking methodology in the performance summary.
Source:: NVIDIA