
Nested data types are a convenient way to represent hierarchical relationships within columnar data. They are frequently used as part of extract, transform,…
Nested data types are a convenient way to represent hierarchical relationships within columnar data. They are frequently used as part of extract, transform, load (ETL) workloads in business intelligence, recommender systems, cybersecurity, geospatial, and other applications.
List types can be used to easily attach multiple transactions to a user without creating a new lookup table, for example. Struct types can be used to attach flexible metadata and many key-value pairs within the same column. In web and mobile applications, nested types represent raw JSON objects as elements in a column of data, enabling this data to feed into machine learning (ML) training pipelines. And many data science applications rely on nested types to model, manage, and process complex data inputs.
In the RAPIDS suite of accelerated data science libraries, libcudf is the CUDA C++ library for columnar data processing. RAPIDS libcudf is based on the Apache Arrow memory format and supports GPU-accelerated readers, writers, relational algebra functions and column transformations.
In addition to flat data types like numbers and strings, libcudf also supports nested data types such as variable-length lists, structs, and arbitrarily nested combinations of list and struct types. In the releases from 23.02 to 23.12, RAPIDS libcudf has expanded support for nested data types in algorithms including aggregations, joins, and sorting.
This post showcases data processing with nested data types, introduces the “row operators” that make nested data processing possible, and explores how nested data types impact performance.
Data processing with nested types
One common workflow in database management is monitoring and managing data duplicates. RAPIDS libcudf now includes a C++ nested_types example that reads in JSON data as a libcudf table, computes the count of each distinct element from the first column, joins the count to the original table, and writes the data back as JSON. The libcudf public API enables data processing applications to work with flat types like numbers or strings and nested types like structs and lists, both with equal ease.
The C++ nested_types example uses the libcudf JSON reader to ingest nested data in a columnar format as a table object. The accelerated JSON reader is also available to C++ developers. JSON provides a human-readable way to create and inspect nested columns. To learn about patterns for using the JSON reader in the Python layer, see GPU-Accelerated JSON Data Processing with RAPIDS.
The read_json function in the C++ nested_types example accepts a filepath and returns a table_with_metadata object:
cudf::io::table_with_metadata read_json(std::string filepath)
{
auto source_info = cudf::io::source_info(filepath);
auto builder = cudf::io::json_reader_options::builder(source_info).lines(true);
auto options = builder.build();
return cudf::io::read_json(options);
}
Once the JSON data is read and parsed into a table object, the first processing step is a count aggregation to track the number of occurrences for each distinct element. The count_aggregate function in the example populates an aggregation request, executes the aggregate function, and then constructs an output table:
std::unique_ptr count_aggregate(cudf::table_view tbl)
{
// Get count for each key
auto keys = cudf::table_view{{tbl.column(0)}};
auto val = cudf::make_numeric_column(cudf::data_type{cudf::type_id::INT32}, keys.num_rows());
cudf::groupby::groupby grpby_obj(keys);
std::vector requests;
requests.emplace_back(cudf::groupby::aggregation_request());
auto agg = cudf::make_count_aggregation();
requests[0].aggregations.push_back(std::move(agg));
requests[0].values = *val;
auto agg_results = grpby_obj.aggregate(requests);
auto result_key = std::move(agg_results.first);
auto result_val = std::move(agg_results.second[0].results[0]);
auto left_cols = result_key->release();
left_cols.push_back(std::move(result_val));
// Join on keys to get
return std::make_unique(std::move(left_cols));
}
With the counts data in hand, the next processing step joins this data to the original table, adding this information to inform count-based filtering and root-cause investigations in downstream analysis. The join_count function in the C++ nested_types example accepts two table_view objects, joins them on their first columns, and then constructs an output table:
std::unique_ptr join_count(cudf::table_view left, cudf::table_view right)
{
auto [left_indices, right_indices] =
cudf::inner_join(cudf::table_view{{left.column(0)}}, cudf::table_view{{right.column(0)}});
auto new_left = cudf::gather(left, cudf::device_span{*left_indices});
auto new_right = cudf::gather(right, cudf::device_span{*right_indices});
auto left_cols = new_left->release();
auto right_cols = new_right->release();
left_cols.push_back(std::move(right_cols[1]));
return std::make_unique(std::move(left_cols));
}
The last data processing step sorts the table based on the elements in the first column. Sorting is useful for providing a deterministic ordering that facilitates downstream steps like partitioning and merging. The sort_keys function in the C++ nested_types example accepts a table_view, computes indices with sorted_order, and then gathers the table based on the ordering:
std::unique_ptr sort_keys(cudf::table_view tbl)
{
auto sort_order = cudf::sorted_order(cudf::table_view{{tbl.column(0)}});
return cudf::gather(tbl, *sort_order);
}
Finally, the processed data is serialized back to disk using a GPU-accelerated JSON writer, which uses the metadata from read_json to preserve the nested struct key names from the input data. The write_json function in the C++ nested_types example accepts a table_view, table_metadata, and a filepath:
void write_json(cudf::table_view tbl, cudf::io::table_metadata metadata, std::string filepath)
{
auto sink_info = cudf::io::sink_info(filepath);
auto builder = cudf::io::json_writer_options::builder(sink_info, tbl).lines(true);
builder.metadata(metadata);
auto options = builder.build();
cudf::io::write_json(options);
}
Taken together, the C++ nested_types example makes a count of each distinct element in the first column, joins those values to the original table, and then sorts the table on the first column. Note that no part of the code in this example is specific to nested types. In fact, this example is compatible with any supported data type in libcudf, flat or nested, demonstrating the power and flexibility of libcudf nested type support.
Introducing libcudf row operators
Under the hood, libcudf supports equality comparison, inequality comparison, and element hashing using a few key “row operators.” These row operators are reused in algorithms throughput libcudf and enable the separation of data type support from other algorithm details.
Taking hash-based aggregations as an example, the hashing and equality operators are used when building and probing the hash tables. For sort-based aggregations, the lexicographic operator identifies one element as less than another element and is a key component of any sorting algorithm. The new row operators unlock support for nested types across the relational algebra functions in libcudf.
For flat types such as numeric and strings, the row operators process the value and null state for each element. Strings types add more complexity with integer offsets associating a variable number of characters with each element. For struct types, the row operators process the null state for the struct parent as well as the values and null state for each child column.
Variable-length list types add another layer of complexity, where the row operators account for the hierarchical structure, including null state, list depth, and list length at each nested level. If the hierarchical structure is matching, list operators then consider the value and null state for each leaf element. Of the row operators, hashing and equality are simpler because they can process the data from each element in any order. However, for types that include lists, lexicographic comparison must produce consistent ordering and so requires sequential parsing of null states, hierarchy, and values.
The treatment for list types in the libcudf lexicographic operator is inspired by the Dremel encoding algorithm used in the Parquet format. In Dremel encoding, the list columns are represented using three data streams: the definition stream for recording null state and nesting depth, the repetition stream for recording list lengths, and the value stream for recording leaf values. The encoding gives a flat data structure that’s more efficient to process than the recursive variable-length list representation in Arrow.
One limitation of Dremel encoding for lists is that the value stream only supports flat types. To extend support for lists containing structs, a preprocessing step replaces a nested struct column with an integer column corresponding to the rank of each struct element. This recursive preprocessing step extends the lexicographic operator type support to include any combination of lists and structs in the data type.
How data types impact performance
The C++ nested_types example is compatible with any supported data type in libcudf. Comparing performance is easy using the command line interface in the example. The following performance data was collected based on timing implemented in the example and run on NVIDIA DGX H100 hardware.
The data type of the column impacts the overall runtime of the example, with more complex data types increasing the runtime of sort-based processing steps (Figure 1). Across a range of data types, the results show 2-5 ms runtime for count aggregation step and 10-25 ms runtime for the inner join step. Both of these steps use hash-based implementations and rely on the hashing and equality row operators.
However, the sorting step shows that runtimes increased to 60-90 ms for variable-sized types that include strings or lists. The sorting step relies on the more complex lexicographic row operator. While hash-based algorithms show relatively consistent runtimes as a function of data type, sort-based algorithms show longer runtimes for variable-sized types.
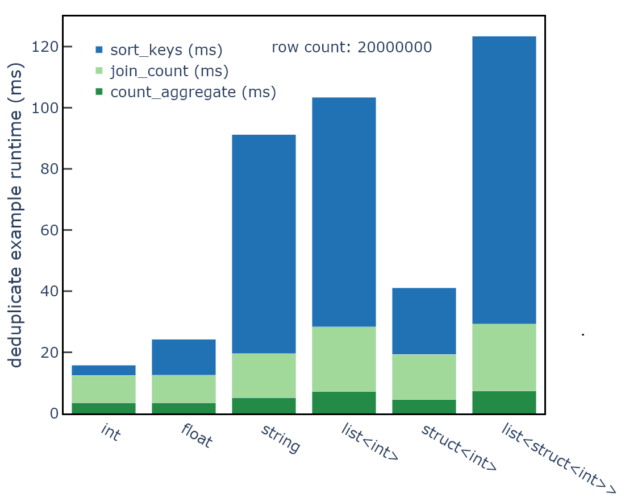 Figure 1. Runtime of
Figure 1. Runtime of count_aggregate, join_count, and sort_keys steps by data type, with 85% distinct elements and 20 million rows
Row count and nesting depth also impact the performance of the example, with higher row counts and simpler data types showing the highest data processing throughput. Figure 2 shows count_aggregate performance from the C++ nested_types example, where throughput generally increases as the row count increases from 100K to 20 million rows. Data types marked with ‘8’ have eight levels of nesting depth. int and float refer to 64-bit types.
Note that the input data uses structs with one child and lists with length one. The performance data shows primitive types with about 45 GB/s peak throughput, singly nested types with about 30 GB/s peak throughput, and deeply nested types with 10-25 GB/s peak throughput. Struct levels incur less overhead than list levels, and mixed struct/list nesting incurs the largest overhead.
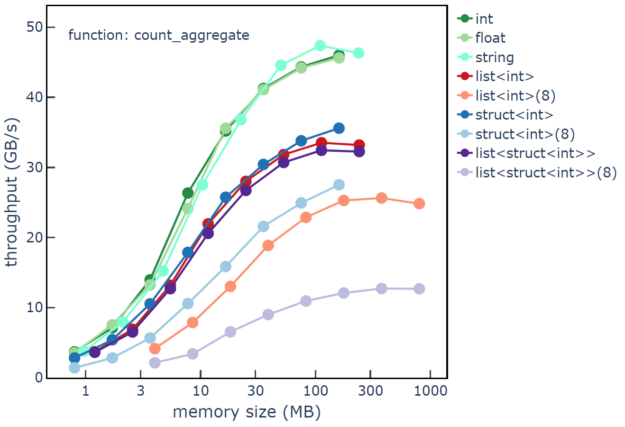 Figure 2. Data processing throughput versus memory size of data for the
Figure 2. Data processing throughput versus memory size of data for the count_aggregate example function. Each line shows the effect of sweeping from 100K rows to 20 million rows
Finally, the length of list elements also impacts performance, with longer lengths showing higher throughput due to early exits in comparators. Figure 3 shows the impact of list length on data processing throughput using list columns with list lengths from 1 to 16. As list length increases, the total integer leaf count and total memory size also increase, and the number of rows and total size of the offsets data are held constant.
The data in Figure 3 uses randomly-ordered leaf values, so the comparators will often only need to examine the first element of each list. Performance data collected from lengths increasing from 1 to 16 shows a 7x increase in throughput for the count_aggregate step and a 4x increase in throughput for the sort_keys step. The data uses 10 million rows, 64-bit integer leaf elements, 85% distinct leaf values, and list length held constant within each table.
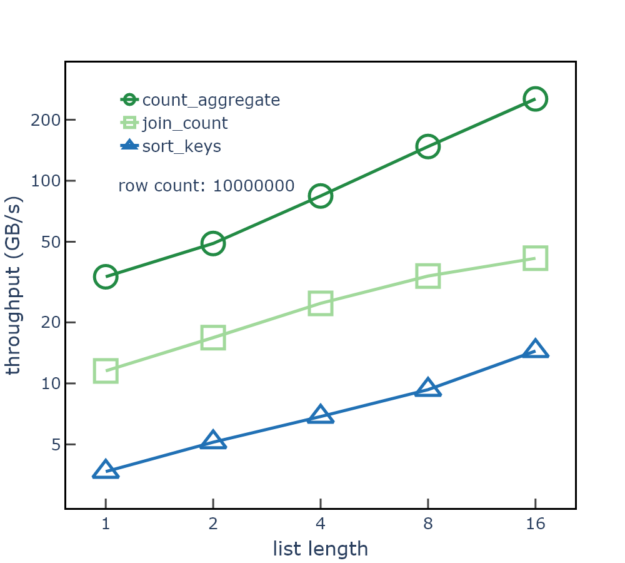 Figure 3. Data processing throughput of the count_aggregate, join_count, and sort_keys steps for singly nested list types with varying list lengths
Figure 3. Data processing throughput of the count_aggregate, join_count, and sort_keys steps for singly nested list types with varying list lengths
Summary
RAPIDS libcudf provides powerful, flexible, and accelerated tools for working with nested data types. Relational algebra algorithms such as aggregations, joins, and sorting are tuned and optimized for any supported nested data type, even deeply nested and mixed list and struct nested data types.
Build and run a few examples to get started with RAPIDS libcudf. For more information about CUDA-accelerated dataframes, see the cuDF documentation and the rapidsai/cudf GitHub repo. For easier testing and deployment, RAPIDS Docker containers are also available for releases and nightly builds. If you’re already using cuDF, you can run the new C++ nested_types example by visiting rapidsai/cudf/tree/HEAD/cpp/examples/nested_types on GitHub.
Acknowledgements
Thank you Devavret Makkar, Jake Hemstad, and the rest of the RAPIDS team for contributing to this work.
Source:: NVIDIA