
Large language model (LLM) applications are essential in enhancing productivity across industries through natural language. However, their effectiveness is…
Large language model (LLM) applications are essential in enhancing productivity across industries through natural language. However, their effectiveness is often limited by the extent of their training data, resulting in poor performance when dealing with real-time events and new knowledge the LLM isn’t trained on.
Retrieval-augmented generation (RAG) solves these problems. By augmenting models with an external knowledge base, RAG can ground LLMs with relevant data. This enhances the quality of their response, improving accuracy, and reducing hallucinations. RAG not only extends the utility of LLMs but also provides a cheaper alternative to time-consuming re-training runs.
Deploying and scaling RAG applications for tens of thousands to millions of users comes with its own set of challenges, specifically around GPU memory management. Developers need access to state-of-the-art infrastructure with robust memory capabilities that runs real-time RAG applications performantly and within stringent service level agreements (SLAs).
This is where the NVIDIA end-to-end full-stack accelerated computing solution shines. In this post, we discuss how the NVIDIA GH200 Grace Hopper Superchip can help solve these issues.
Comparing the GH200 to NVIDIA A100 Tensor Core GPUs, we observed up to a 2.7x increase in speed for embedding generation, 2.9x for index build, 3.3x for vector search time, and 5.7x for Llama-2-70B (FP8) inference performance.
Memory challenges when deploying RAG applications at scale
One significant challenge for developers deploying large-scale RAG applications is managing GPU memory usage. Both GPU memory capacity and bandwidth are vital for optimal inference performance, and when limited, often act as a bottleneck for crucial tasks such as:
- Hosting LLMs
- Processing batched requests
- Handling Key-Value (KV) cache in attention mechanisms
- Facilitating efficient data transfer between the GPU and CPU
Model hosting
While larger models tend to provide more precise and comprehensive responses, they require more GPU memory. This can make deployments for models like Llama-2-70B difficult to manage.
Llama-2-70B (FP16) has weights that take up 140 GB of GPU memory alone. Developers often resort to techniques like model sharding across multiple GPUs, which ultimately add latency and complexity.
In addition to hosting the LLM, the GPU must host an embedding model and a vector database. These components may not require much additional GPU memory (about 10 GB depending on the size of the model and knowledge base.) However, generating embeddings and executing vector search at scale are highly parallel operations and can significantly benefit from GPU acceleration and strong bandwidth between the GPU and CPU.
Batch processing and KV cache
Batching enables the GPU to handle multiple requests simultaneously in a single pass through the neural network to boost throughput effectively. However, batch size is directly proportional to KV (key-value) cache size, which represents the memory occupied by the caching of self-attention tensors to avoid redundant computation, and results in large GPU memory requirements. For example, when deploying Llama-2-70B (80 layers) with FP16 precision, batch size 32, and context size 4096, the size of the KV cache comes out to around 40 GB.
In a RAG application that is already GPU memory-constrained from model hosting, there exists an upper limit to the batch size during inference. While larger batch sizes do boost throughput, they can also result in higher latency. To meet SLAs, developers must optimize for this throughput and latency tradeoff according to the RAG application’s intended use.
For instance, an application generating detailed reports from extensive enterprise data can afford higher latency, and therefore larger batch sizes, compared to an application providing real-time customer support.
Data transfer
RAG applications at scale require rapid data transfer between the GPU and CPU. For example, during the embedding generation process, the CPU preprocessing (for example, tokenization, cleaning, and so on) of new data takes place before the data is sent to the GPU for accelerated embedding generation. This requires strong bandwidth between the GPU and CPU, which is essential for applications where delays in processing large amounts of new information at scale can lead to outdated or irrelevant results.
Hardware: NVIDIA GH200 Grace Hopper Superchip
The NVIDIA GH200 Grace Hopper Superchip tackles GPU memory deployment challenges head-on with its state-of-the-art memory capabilities.
GH200 is a high-performance GPU-CPU superchip designed for the world’s most demanding AI inference workloads. The architecture combines the performance of the NVIDIA Hopper GPU and the versatility of the NVIDIA Grace CPU in one superchip. They are connected by a high-bandwidth, memory-coherent NVIDIA NVLink-C2C interconnect. This enables the CPU and GPU to talk to each other at 900 GB/s, which is 7x the bandwidth of traditional PCIe Gen5 lanes and 5x the power efficiency.
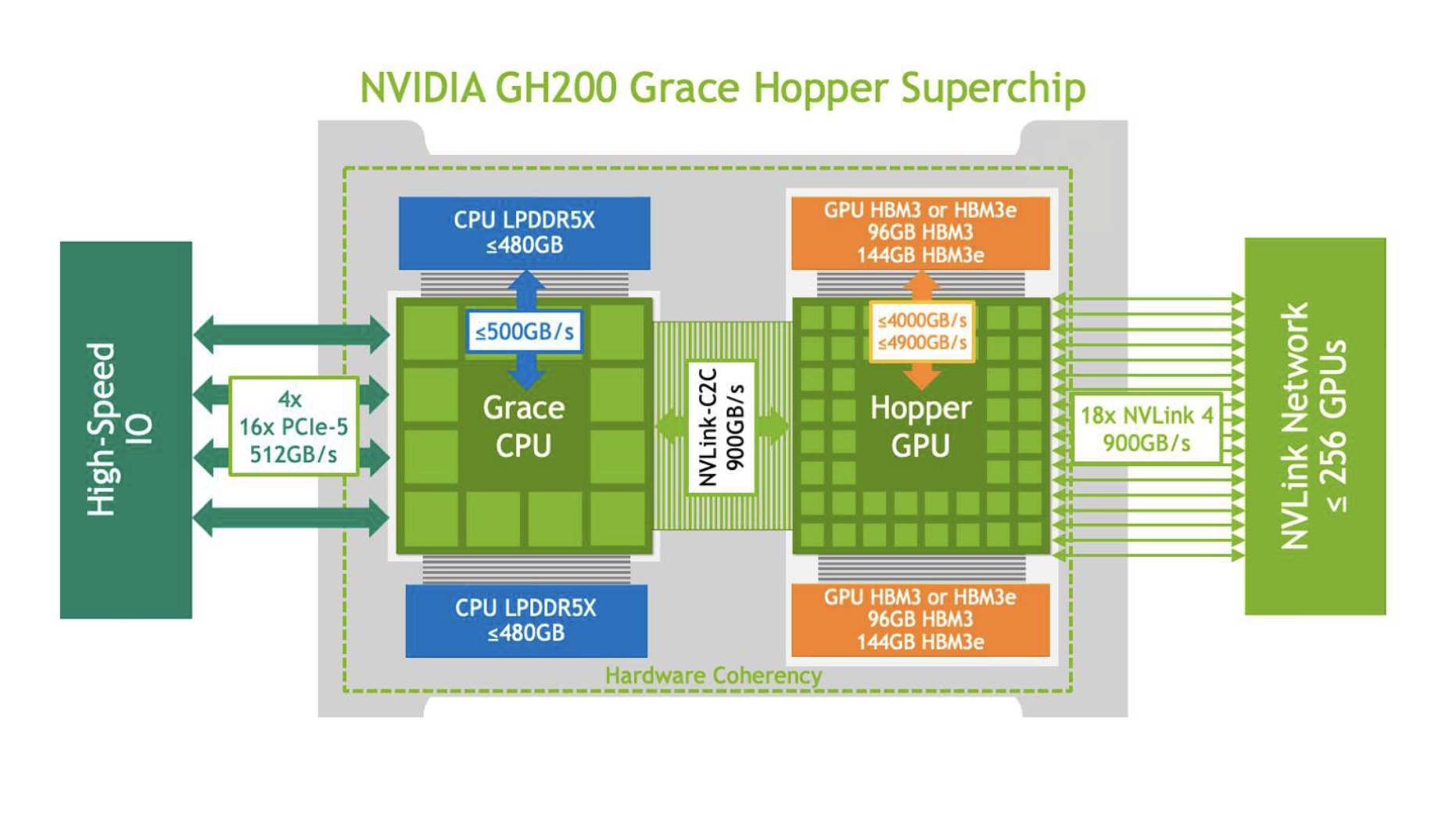 Figure 1. GH200 Architecture
Figure 1. GH200 Architecture
This design, as shown in Figure 1, expands memory capacity significantly. The GH200 features up to 480 GB of LPDDR5X CPU memory and supports up to 144 GB of HBM3e GPU memory, offering up to 624 GB of fast-access memory on a single GPU-CPU superchip. This ultimately increases developer productivity and performance, enabling concurrent, transparent access to both CPU and GPU-resident memory.
The expanded memory capacity simplifies algorithms and memory management. It also makes the GH200 ideal for handling large batch sizes, making the GPU-CPU superchip an optimal choice for RAG applications generating content for complex queries at scale. However, expanded memory capacity isn’t the only feature that addresses GPU memory bottlenecks.
The GH200 features the NVIDIA Transformer Engine as part of the Hopper architecture. It can natively support FP8, which reduces the memory footprint for LLMs like Llama2-70B through quantization methods implemented in optimized software like NVIDIA TensorRT-LLM. This enables large models to fit onto a single GH200.
Software: NVIDIA NeMo Framework, NVIDIA Triton Inference Server, NVIDIA TensorRT-LLM, and NVIDIA RAFT
A RAG pipeline includes various software components working together in harmony.
Optimized software tools sit within different components of the broader RAG architecture (Figure 2) from embedding generation, vector search, to LLM inference, and ensure a fully accelerated RAG pipeline that delivers the best performance. It includes elements such as the deployment software optimized for LLMs like NVIDIA NeMo Framework, NVIDIA Triton Inference Server and TensorRT-LLM, and the GPU-accelerated vector database running NVIDIA RAFT.
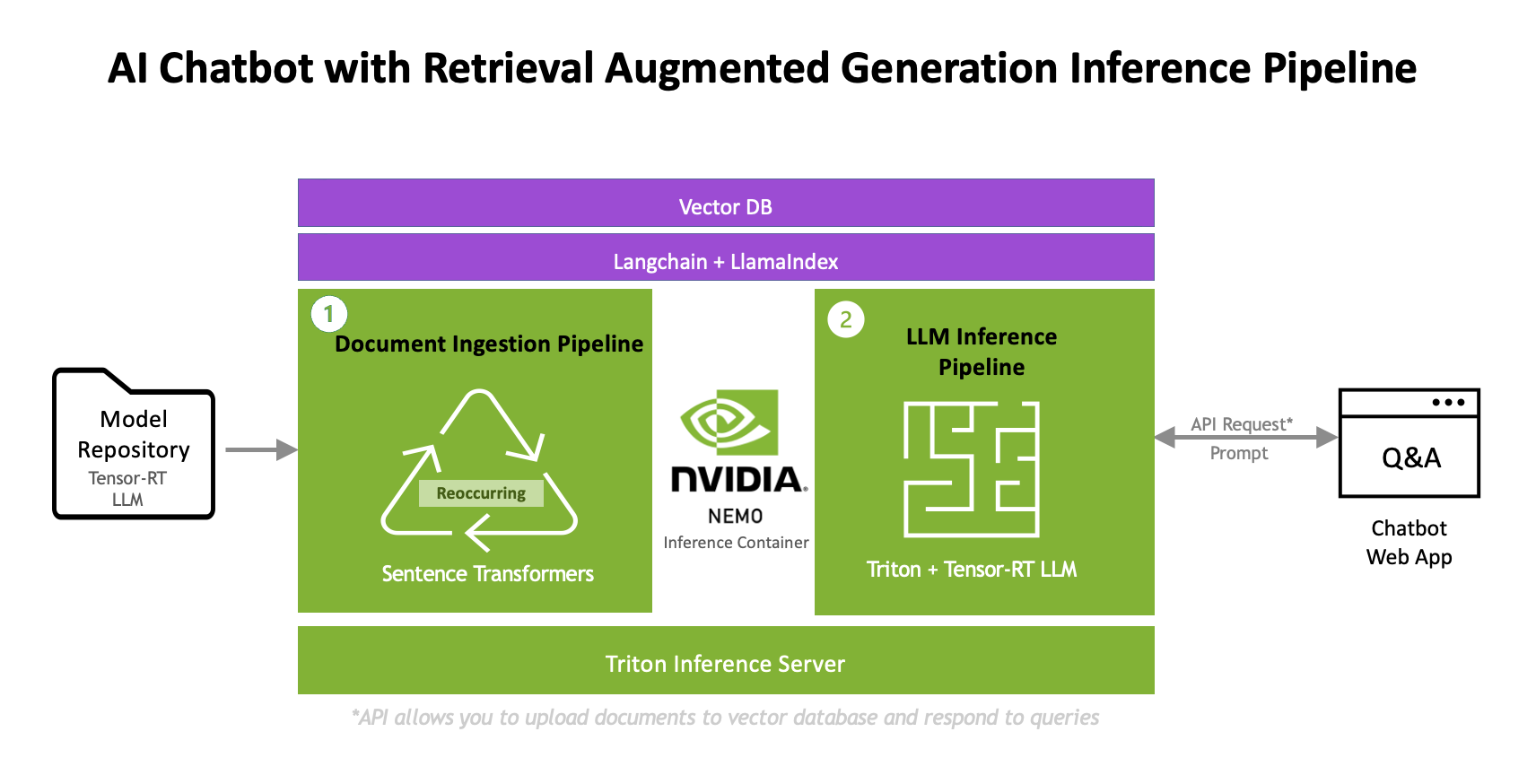 Figure 2. RAG Architecture
Figure 2. RAG Architecture
While each component of this architecture is designed to be open-source and modular, we recommend implementing this RAG architecture with the best NVIDIA models, libraries, tools, and support for optimal performance.
For example, TensorRT-LLM can supercharge LLM inference beyond quantization methods by implementing techniques like tensor parallelism, which enables model weights to be split across devices when GPU memory is constrained. Triton Model Analyzer, a tool that automatically evaluates model deployment configurations in Triton Inference Server, helps developers optimize for the best dynamic batching and model concurrency parameters that maximize inference performance under strict latency constraints. The NVIDIA RAFT library also includes widely used NVIDIA CUDA-accelerated algorithms like IVF-PQ for developers to simplify GPU-accelerated vector search.
Triton and TensorRT-LLM are part of NVIDIA AI Enterprise, which features support services along with enterprise-grade stability, security, and manageability for open-sourced containers and frameworks that support the RAG pipeline.
Further details on NVIDIA best practices for the RAG workflow can be found on GitHub.
GH200 RAG inference performance benchmarks
When deploying a single GH200 GPU-CPU superchip optimized with NVIDIA software throughout the RAG pipeline, we observe incredible speedups. This includes an increase of 2.7x in embedding generation, 2.9x in index build, 3.3x in vector search time, and 5.7x in Llama-2-70B inference performance (2048 input length and 128 output length) running on TensorRT-LLM relative to A100.
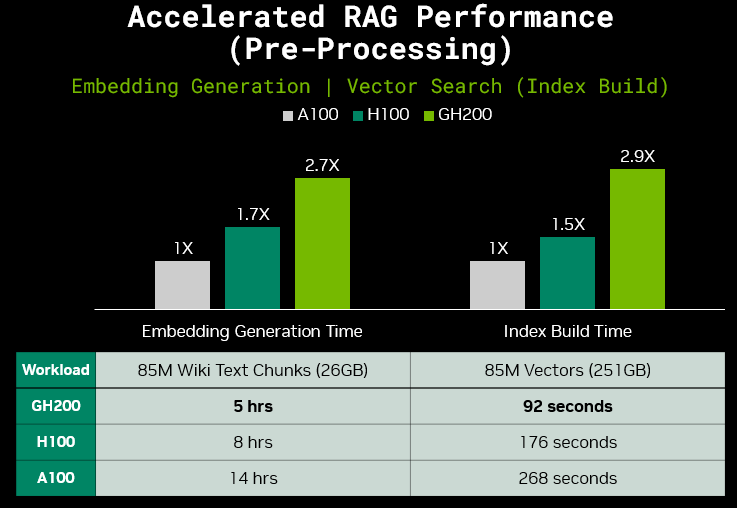 Figure 3. Accelerated RAG performance (preprocessing) for embedding generation and index build (GH200 and H100 speedup over A100)
Figure 3. Accelerated RAG performance (preprocessing) for embedding generation and index build (GH200 and H100 speedup over A100)
Preliminary measured performance per GPU, subject to change.
Embedding Generation Time: 1x GH200 (144 GB HBM3e GPU memory) | 1x H100 (80 GB HBM3 GPU Memory) | 1x A100 (80 GB HBM2e GPU memory) | Batch Size = 1024 | Output Vectors = 85M of size 768 (251 GB) | Model = Sentence Transformer Paraphrase Multilingual MPNET Base v2 from Hugging Face | Performance scaled linearly from a measurement of 10K text chunks
Index Build Time: 1x GH200 (144 GB HBM3e GPU memory) | 1x H100 (80 GB HBM3 GPU Memory) | 1x A100 (80 GB HBM2e GPU memory)
Figure 3 shows GH200 speedups of 2.7x in embedding generation over A100, saving 9 hours on a sample Wikipedia dataset in the RAG preprocessing pipeline. The index build time on GH200 following the embedding generation process shows speedups of 2.9x over A100.
These workloads are highly parallel operations, and at scale, can benefit significantly from additional GPUs and a strong connection between the GPU and CPU to reduce data transfer time and prevent bottlenecks.
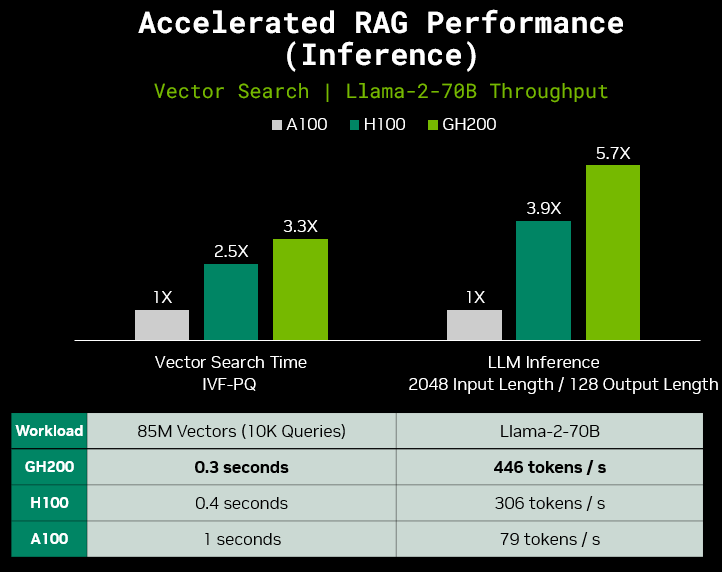 Figure 4. Accelerated RAG inference performance for vector search (IVF-PQ) and Llama-2-70B inference (GH200 and H100 speedup over A100)
Figure 4. Accelerated RAG inference performance for vector search (IVF-PQ) and Llama-2-70B inference (GH200 and H100 speedup over A100)
Preliminary measured performance per GPU, subject to change.
Vector Search Time: 1x GH200 (144 GB HBM3e GPU memory) | 1x H100 (80 GB HBM3 GPU Memory) | 1x A100 (80 GB HBM2e GPU memory) | Batch Size = 10,000 | Queries = 10,000 over 85M vectors
Llama-2-70B Inference: 1x GH200 (144 GB HBM3e GPU memory) | 2x H100 (80 GB HBM3 GPU Memory) | 4x A100 SXM (80 GB HBM2e GPU memory) | Batch Size = 64 (GH200), 96 (H100s), and 120 (A100s) | Precision = FP8 (GH200 and H100) and FP16 (A100s) | TensorRT-LLM
Throughput is measured by output tokens per second per GPU =
(Output Length * Batch Size) / (Total end-to-end Latency) / (# GPUs)
After the preprocessing tasks of setting up the external knowledge base are complete, the GH200 further accelerates the RAG inference pipeline. For example, during vector search, the GH200 achieves a 3.3x speedup over A100 as shown in Figure 4.
Given the need for handling extensive contextual data and producing concise responses, RAG applications often require long input lengths and short output lengths during LLM inference. Figure 4 illustrates results under such conditions, in which GH200 achieves a speedup of 5.7x over A100 for Llama-2-70B inference given an input length of 2048 and an output length of 128. Not only does GH200 deliver superior performance, but it also excels in power efficiency, offering favorable performance per watt. We expect these results to continue to improve with future TensorRT-LLM data offloading optimizations, further leveraging GH200 NVLink-C2C capability.
When testing the GH200-powered RAG pipeline in over 200 real-world sample queries, it computed embeddings for the queries, ran vector search, and retrieved the necessary information from the external knowledge base all in 0.6 seconds.
Conclusion
When deploying compute-intensive LLM applications using RAG, it’s essential to consider GPU memory and GPU-CPU bandwidth to unlock high-performance inference at scale. The GH200 GPU-CPU Superchip paired with software solutions like TensorRT-LLM play a pivotal role in addressing large-scale RAG deployment challenges. It enables efficient handling of new data, large batch sizes, and complex queries, for further performance gains in memory-constrained systems.
Check out our cloud partners that announced NVIDIA GH200 instances like AWS, CoreWeave, Lambda, OCI, Vultr, and others, and familiarize yourself with the NVIDIA RAG example published on the NVIDIA generative AI GitHub.
Learn more about RAG by watching our on-demand content from NVIDIA LLM Day, which includes a session ‘Tailoring LLMs to Your Use Case’ where you can learn about strategies to build RAG-based systems.
Source:: NVIDIA