
Generative AI is rapidly transforming computing, unlocking new use cases and turbocharging existing ones. Large language models (LLMs), such as OpenAI’s GPT…
Generative AI is rapidly transforming computing, unlocking new use cases and turbocharging existing ones. Large language models (LLMs), such as OpenAI’s GPT models and Meta’s Llama 2, skillfully perform a variety of tasks on text-based content. These tasks include summarization, translation, classification, and generation of new content such as computer code, marketing copy, poetry, and much more.
In addition, diffusion models, such as Stable Diffusion developed by Stability.ai, enable users to generate incredible images using simple text prompts.
The capabilities enabled by state-of-the-art generative AI are considerable—but so, too, is the amount of compute performance required to train them. LLMs, for example, have grown into hundreds of billions of parameters, with each model being trained on enormous amounts of data. The large and growing compute demands of training state-of-the-art LLMs are beyond the scope of a single GPU or even a single node packed with GPUs.
Instead, training these LLMs requires accelerated computing at the scale of an entire data center. This is why the NVIDIA accelerated computing platform scales to many thousands of high-performance GPUs, interconnected with the highest-bandwidth networking fabrics, all efficiently orchestrated by carefully crafted software.
MLPerf Training v3.1 is the latest edition of the long-running suite of AI training benchmarks, and serves as a trusted, peer-reviewed measure of AI training performance. After adding an LLM training benchmark in the prior round based on OpenAI’s GPT-3 175 billion parameter model, this round sees the addition of a text-to-image generative AI training benchmark based on Stable Diffusion.
And, reflecting the rapid convergence of traditional HPC workloads with AI, MLPerf HPC v3.0 measures training performance of AI models that are used for scientific computing applications. In this round, a protein structure prediction test using OpenFold has been added, complementing the existing tests which cover climate atmospheric river identification, cosmology parameter prediction, and quantum molecular modeling.
In just one MLPerf Training round, NVIDIA demonstrated unprecedented performance and scalability for LLM training, tripling submission scale and nearly tripling performance. This shattered the performance record previously set by the NVIDIA platform and NVIDIA H100 Tensor Core GPUs just 6 months ago. And, with continued software improvements, the NVIDIA MLPerf submissions also boosted the per-accelerator performance of the H100 GPU, translating into faster time to train and lower cost to train.
NVIDIA also submitted results on the newly added text-to-image training benchmark, achieving record performance both on a per-accelerator basis as well as at scale.
In addition, NVIDIA set new performance records at scale on the DLRM-dcnv2, BERT-large, RetinaNet, and 3D U-Net workloads, extending the record-setting performance achieved by the NVIDIA platform and H100 GPUs in the prior round. For these benchmarks, collective operations were accelerated using NVIDIA Quantum-2 InfiniBand switches and in-network computing with NVIDIA SHARP to help achieve record performance at scale.
Finally, NVIDIA also made its first MLPerf HPC submissions with H100 GPUs and ran all workloads and scenarios.
The following sections take a closer look at these incredible results.
Supercharging GPT-3 175B training performance
In MLPerf Training v3.1, NVIDIA raised the bar for LLM training performance through both dramatically greater submission scale as well as software enhancements that achieved greater performance per GPU.
Record-setting performance and excellent scaling efficiency
NVIDIA made several very large-scale LLM submissions at a maximum submission scale of 10,752 H100 GPUs. This tripled the maximum scale submitted in the prior round, representing the largest number of accelerators ever used in an MLPerf submission. NVIDIA achieved a time-to-train score of 3.92 minutes in its largest-scale submission, a 2.8x performance boost and a new LLM benchmark record.
In addition, NVIDIA partnered closely with Microsoft Azure on a joint LLM submission, also using 10,752 H100 GPUs and Quantum-2 InfiniBand networking, achieving a time to train of 4.01 minutes, nearly identical to that of the NVIDIA submission. Achieving this level of performance on two entirely different, giant-scale systems in the same MLPerf round is a singular technical achievement.
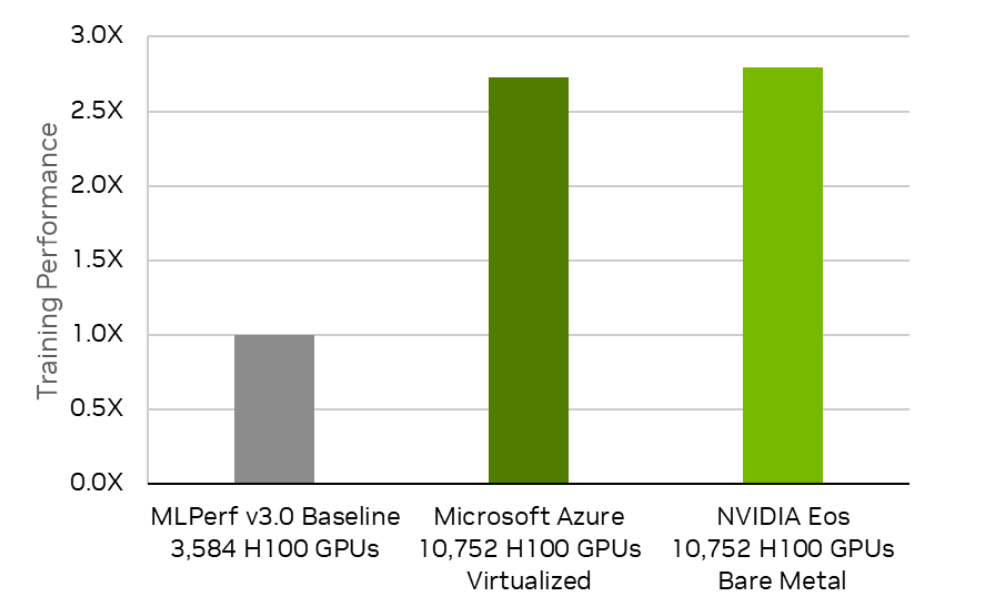 Figure 1. Relative performance of the NVIDIA and Microsoft Azure 10,752 H100 GPU joint submission on the MLPerf Training LLM test
Figure 1. Relative performance of the NVIDIA and Microsoft Azure 10,752 H100 GPU joint submission on the MLPerf Training LLM test
MLPerf Training v3.0 and v3.1. Results retrieved from www.mlperf.org on November 8, 2023, from entries 3.0-2003, 3.1-2002, 3.1-2007. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
The NVIDIA submissions also demonstrated near-linear performance scaling, as submission sizes scaled from 4,096 H100 GPUs to 10,752 H100 GPUs.
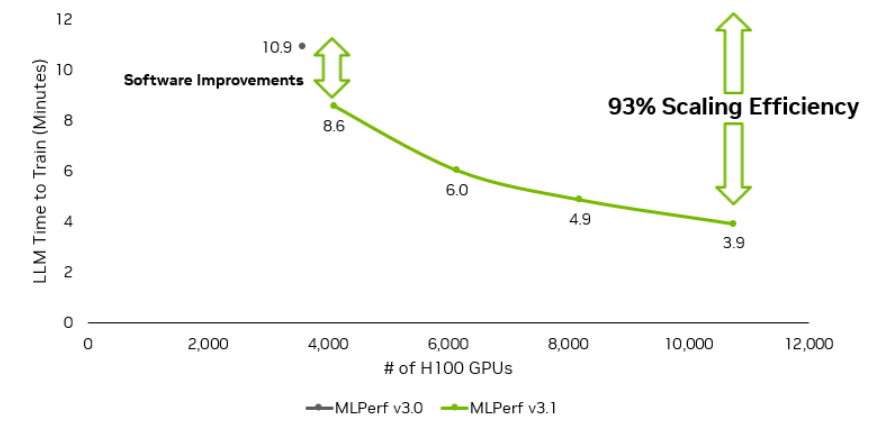 Figure 2. MLPerf Training LLM performance compared to H100 GPU count used to achieve that performance
Figure 2. MLPerf Training LLM performance compared to H100 GPU count used to achieve that performance
MLPerf Training v3.0 and v3.1. Results retrieved from www.mlperf.org on November 8, 2023, from entries 3.0-2003, 3.1-2005, 3.1-2007, 3.1-2008, 3.1-2009. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
To keep the benchmark duration within a reasonable time, MLPerf benchmarks represent a fraction of whole end-to-end workloads. As reported in Training Compute-Optimal Large Language Models, a GPT-3 175 billion model requires 3.7T tokens to train on to be compute-optimal. Projecting our MLPerf 10,752-GPU record of 3.92 minutes, the compute-optimal training on 3.7T tokens would complete in 8 days.
This result was achieved through the full array of NVIDIA technologies, including the latest, fourth-generation NVLink interconnect combined with the latest third-generation NVSwitch chip to enable 900 GB/s all-to-all communication between H100 GPUs, NVIDIA Quantum-2 InfiniBand networking, as well as NVIDIA’s exceptional software stack, including the NVIDIA NeMo framework, NVIDIA Transformer Engine library, NVIDIA cuBLAS library, and the NVIDIA Magnum IO NCCL documentation.
Increasing performance per H100 GPU
NVIDIA made significant software improvements that yielded about 10% faster time to train in both 512-GPU and 768-GPU submissions compared to their corresponding submissions in the prior round, achieving 797 TFLOPS of training throughput per H100 GPU. These improvements were seen in the larger-scale NVIDIA submissions as well, with the 4,096 H100 GPU submission demonstrating nearly 28% more performance with only 14% more GPUs.
By continuing to deliver more performance from NVIDIA GPUs with ongoing software enhancements, customers benefit from greater productivity through shorter model training times, faster time to deployment, and lower costs–particularly in the cloud. This is achieved by requiring fewer GPU hours to perform the same work, and the ability to train increasingly complex models on the same hardware.
Setting the standard for Stable Diffusion training
The NVIDIA platform and H100 GPUs submitted record-setting results for the newly-added Stable Diffusion workloads. The NVIDIA submission using 64 H100 GPUs completed the benchmark in just 10.02 minutes, and that time to train was reduced to just 2.47 minutes using 1,024 H100 GPUs.
Figure 3 shows some of the optimizations used in the NVIDIA Stable Diffusion submission. All the optimizations are available in NeMo Multimodal Release 23.09.
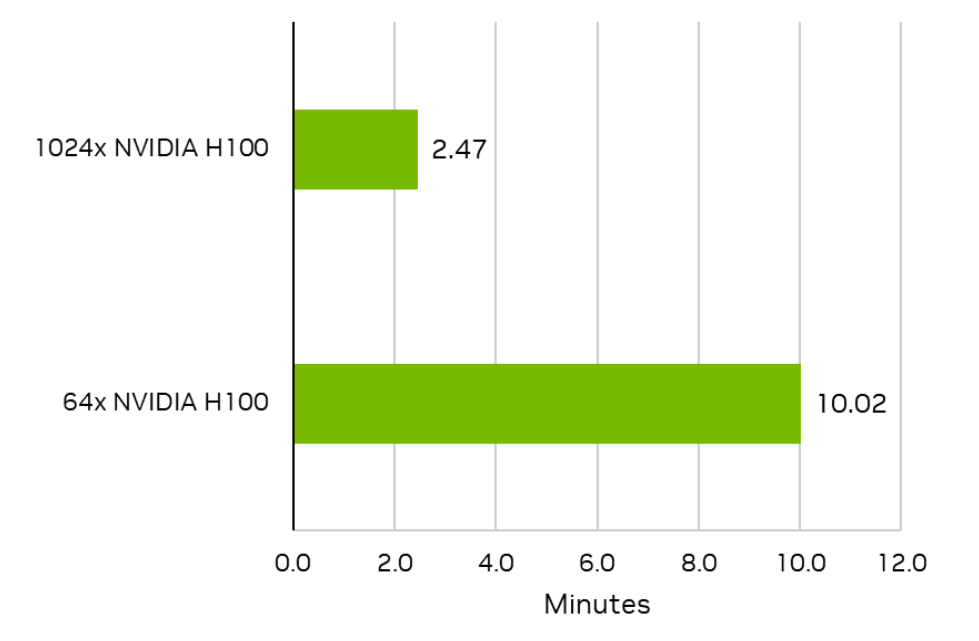 Figure 3. Time to train for the 64 and 1,024 NVIDIA H100 submissions on the MLPerf text-to-image (Stable Diffusion) benchmark
Figure 3. Time to train for the 64 and 1,024 NVIDIA H100 submissions on the MLPerf text-to-image (Stable Diffusion) benchmark
MLPerf Training v3.1. Results retrieved from www.mlperf.org on November 8, 2023, from entries 3.1-2050, 3.1-2060. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
GroupNorm with Channels Last support
Most diffusion models are composed of two basic building blocks, ResBlock and SpatialTransformer. For ResBlock, and other convolutional neural network (CNN)-based networks, using a Channels Last memory format is preferred for performance. To avoid layout transformations around GroupNorm, which would incur additional memory accesses, the NVIDIA Stable Diffusion submission added support for a GroupNorm that employs a Channels Last memory format. Using a Channels Last layout in combination with APEX GroupNorm led to a 14% performance improvement.
FlashAttention-2
Each SpatialTransformer module contains a self-attention and a cross-attention block. Using FlashAttention-2 for these blocks achieved a 21% speedup.
Host-device synchronization removals
PyTorch models can suffer from significant CPU overheads. To reduce this overhead, several synchronization points between the CPU and the GPU were eliminated. This removes the host from the critical path, and enables end-to-end application performance to correlate much better with GPU performance.
Host execution also results in significant execution time variability, causing variations in iteration times across different workers. This is further exacerbated in multi-GPU settings, where all workers need to synchronize once at each iteration. These optimizations also reduce runtime variations across each worker, improving multi-GPU training performance. Overall, these optimizations boosted performance by 11%.
CUDA graphs
The NVIDIA submission also uses CUDA graphs to further reduce runtime overhead, boosting GPU utilization. Use of CUDA graphs for the U-Net model that is part of Stable Diffusion delivered a 4% performance increase. Similar to the previous optimization, this helps with reducing CPU overhead, as well as multi-GPU performance by reducing runtime variability across workers.
Reduced kernel launch overheads
Diffusion models tend to include many small CUDA kernels, and they can occur at many points across the model. To both reduce kernel launch overheads and minimize the trips to GPU memory, we applied fusion engines such as TorchInductor, yielding a 6% speedup.
Removing type-casting overheads
To make full use of NVIDIA Tensor Cores, modern diffusion models adopt Automatic Mixed Precision (AMP) to enable training using lower precision data formats, such as FP16. The PyTorch implementation of AMP stores model parameters in FP32 precision, which means that dynamic type-casting operations between FP16 and FP32 need to be performed. To avoid such overhead, the model is first cast to FP16 precision, resulting in FP16 model parameters and gradients that can be directly used without the need for type-casting operations.
The optimizer is also modified to maintain an FP32 copy of the model parameters, which are used to update the model instead of the FP16 model parameters. This enables faster model training while maintaining accuracy.
Unlocking faster DLRMv2 training
As in the prior round, NVIDIA made submissions using 8, 64, and 128 H100 GPUs. Due to software improvements, the performance of each of these submissions increased round-over-round, with the largest improvement of 57% achieved in the 128 H100 GPU submission. Key to our DLRMv2 submissions this round was an extensive focus on removing host CPU bottlenecks. This is mostly achieved by using statically linked CUDART, instead of dynamically linking it at runtime. This is because dynamically linked CUDART has additional locking overhead due to its requirement of allowing loading/unloading of modules at any point.
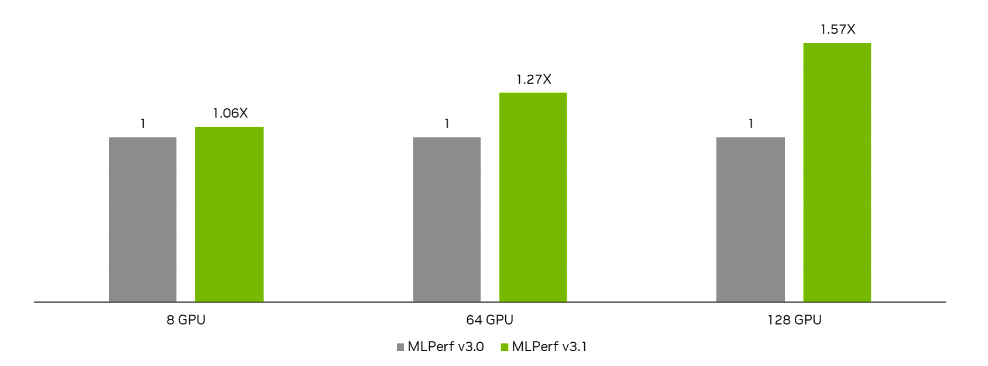 Figure 4. DLRMv2 performance increases in MLPerf Training v3.1 compared to the prior MLPerf Training v3.0 round
Figure 4. DLRMv2 performance increases in MLPerf Training v3.1 compared to the prior MLPerf Training v3.0 round
MLPerf Training v3.1. Results retrieved from www.mlperf.org on November 8, 2023 from entries: 128x 3.0-2065, 128x 3.1-2051. The MLPerf name and logo are trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
Additionally, by making use of data-parallel embeddings for small embedding tables, the NVIDIA submission this round reduced the all-to-all traffic associated with embedding operations. Although data-parallel embedding naturally avoids all-to-all operations, it still requires an allreduce operation to accumulate gradients across GPUs. So, to further enhance performance, a grouped AllReduce technique that fuses the AllReduce operation with the AllReduce operation from the data-parallel dense network is used.
Boosting RetinaNet performance
In this round, the NVIDIA submissions demonstrated both performance increases at the same scales submitted in the prior round, as well as a dramatic boost in maximum scale to 2,048 H100 GPUs (compared to 768 H100 GPUs in the previous round). As a result, NVIDIA set a new record time to train of 0.92 minutes for the MLPerf RetinaNet benchmark, a 64% performance boost compared to the previous NVIDIA submission.
These improvements were fueled by several optimizations, described below.
Avoiding gradient copies in PyTorch DDP
In the NVIDIA maximum-scale configuration with 2,048 H100 GPUs, device-to-device memory copies that were exposed between the end of backpropagation and the start of the optimizer step were observed. These were found to be copies between the model gradients and the AllReduce communication buckets used by PyTorch DistributedDataParallel.
Setting gradient_as_bucket_view=True for PyTorch DDP turns gradients into views (pointers) into the existing AllReduce buckets and avoids creating an extra buffer, reducing peak memory usage and avoiding the overhead of memory copies. This optimization improved training throughput by 3% in the largest-scale NVIDIA submission.
Improved evaluation performance
At large scales, evaluation time increasingly becomes an important factor in time to train. Evaluation in RetinaNet consists of two phases: inference, which is performed on GPUs, and asynchronous scoring, which is performed on CPUs. To improve inference performance at max-scale, the NVIDIA submission this round uses a specifically optimized batch size rather than the one used for training. It also binds processes to CPU cores and increases the number of CPU threads to improve scoring performance.
cuDNN optimizations
The cuDNN library has made improvements to computational kernels that use the fourth-generation Tensor Cores of the H100 GPU. This led to increased performance of convolutions across all sizes used in RetinaNet, delivering up to 3% higher training throughput compared to the previous NVIDIA submission. Improved convolution kernel performance in cuDNN has also led to up to 7% throughput improvement in other benchmarks, such as Resnet50.
Greater spatial parallelism for 3D U-Net
For the maximum-scale NVIDIA submission on the 3D U-Net workload in this round, the system configuration grew from 54 nodes (consisting of 42 training nodes and 12 evaluation nodes in the prior round) to 96 nodes (consisting of 84 training nodes and 12 training nodes).
By leveraging the capabilities of H100 GPUs and the latest version of NVLink, the NVIDIA submission in this round increased the level of spatial parallelism to 8x from a prior 4x. This means that instead of training one image across a set of four H100 GPUs, the latest NVIDIA submission trains one image across eight H100 GPUs, resulting in an end-to-end throughput improvement of over 6.2%.
Improving BERT score at-scale
The max-scale NVIDIA submission using 434 nodes achieved a 1.12x speedup over our previous submission using 384 nodes. This round, we additionally introduced a sample re-ordering optimization to improve load balancing for small per-GPU batch sizes, as is the case for max-scale. This resulted in 6% throughput improvement for the 434-node scale submission.
Sample reordering
Prior large-scale NVIDIA submissions used a packed dataset format where every sample had one to three actual sequences, so that the combined length is the same or slightly smaller than the maximum sequence length. Although this optimization minimizes the load imbalance among GPUs for large enough per-GPU batch sizes, the number of actual sequences processed by GPUs is different. This causes jitter at large-scale runs using small per-GPU batch size. Sample reordering optimization bucketizes the packed samples such that the number of actual sequences processed in each iteration remains constant across GPUs, thus minimizing jitter. We have verified that this optimization does not impact convergence for this benchmark.
Bringing H100 to MLPerf HPC v3.0
In MLPerf HPC v3.0, NVIDIA made its first submissions using H100 GPUs. The newer GPUs delivered a significant boost compared to the NVIDIA MLPerf HPC v2.0 submissions, which used prior-generation A100 GPUs.
The following sections cover some of the software work that was done to make optimized submissions using H100 on all MLPerf HPC v3.0 tests, including the new test based on OpenFold.
OpenFold
A common method for reducing training time is data parallelism, which equally distributes the global batch across GPUs. The degree of parallelism of data-parallel task partitioning is limited by the global batch size. Larger batch sizes, however, result in lower accuracy, limiting the global batch size for OpenFold, preventing the use of data parallelism.
FastFold introduces Dynamic Axial Parallelism (DAP), a way to increase the degree of parallelism. With DAP, the model can continue scaling up, but the scaling efficiency of DAP is low. In the initial phase, increasing GPU count by 4x yields only a 1.7x speedup, with no additional performance increase when GPU count is scaled to 8x.
In addition to scaling efficiency challenges, OpenFold contains about 150K operators, most of which are memory bandwidth bound, leading to suboptimal GPU utilization and high CPU launch overhead. Moreover, in the data load stage, all samples need to be cropped or padded into a fixed size. The time required to prepare these batches depends on both sequence length and the number of Multiple Sequence Alignment (MSA), which vary significantly. It was observed that 0.1% batches are very slow to prepare, blocking the training stage.
To resolve these problems, the NVIDIA OpenFold submission employs the following optimizations:
OpenCatalyst20
The NVIDIA OpenCatalyst20 submissions incorporate several optimizations to maximize performance. First, the submissions use FP16 precision. Next, the submissions perform evaluation asynchronously, which frees the training nodes from needing to perform evaluation. Finally, by disabling PyTorch garbage collection, CPU overhead was reduced.
DeepCAM
For the time-to-train metric, the NVIDIA DeepCAM submission on 2,048 GPUs uses a GPU local batch size of one. In the previous NVIDIA DeepCAM submissions, the PyTorch SyncBN kernel was used for distributed batch normalization. In the NVIDIA MLPerf HPC v3.0 submission, this kernel was replaced with a more efficient single-node group batch normalization kernel from APEX, boosting end-to-end performance.
For the throughput test, the NVIDIA DeepCAM submission ran on two nodes with a GPU local batch size of eight. In this scenario, a large portion of the dataset resides on the NVMe storage, and reading a large portion of this dataset during training thrashes the node’s page cache frequently. This resulted in stalls in the input pipeline, an issue that manifested itself when running on H100 GPUs, which feature much more compute performance than A100 GPUs.
To overcome this issue, the NVIDIA submission implements O_DIRECT in the data reader, bypassing the page cache entirely. This ensured that I/O operations can be hidden almost entirely behind the computations, leading to a 1.8x performance increase compared to the unimproved code.
Finally, enhancements to group convolution kernels designed for the NVIDIA Hopper architecture contributed another 2% speedup.
CosmoFlow
For the CosmoFlow throughput benchmark, the NVIDIA submission runs on 32 GPUs using a global batch size of 32 and a local batch size of one. As the compute performance of H100 GPUs is much greater than A100 GPUs, the training pipeline began to stall, waiting for additional data to arrive.
To fix this, the NVIDIA submission implements support for O_DIRECT in the data reader. Previously, the GPU would make requests to the CPU, the CPU would perform the data read access, and then pass the data back to the GPU. With O_DIRECT, the GPU makes the data requests directly and receives the data back, bypassing the CPU. This decreased data latency and enabled the data input pipeline to remain mostly hidden behind the math computation.
The CosmoFlow network is primarily a series of 3D convolutions and MaxPool layers. For both the time-to-train and throughput benchmark runs, the individual kernels were slower than their maximum theoretical speed. Several low-level optimizations were made to the kernels to increase their performance in the forward and backward passes. In the time-to-train configuration, Cosmoflow ran on 512 GPUs with a global batch size of 512, local batch size of one. Kernel optimizations also improved the time to train by a few percentage points.
MLPerf Training v3.1 and HPC v3.0 takeaways
The NVIDIA platform, powered by NVIDIA H100 GPUs and Quantum-2 InfiniBand, yet again raised the bar for AI training. From powering two LLM submissions at an unprecedented scale of 10,752 H100 GPUs, to unmatched performance on the newly added text-to-image test, to continued performance boosts for classic MLPerf workloads, the NVIDIA platform continues to demonstrate the highest performance and the greatest versatility for the most demanding AI training challenges.
Additionally, the NVIDIA platform demonstrated how it is accelerating the convergence of HPC and AI with the latest MLPerf HPC results, with the H100 GPU enabling substantial speedups compared to prior NVIDIA submissions using the A100 GPU. In addition to delivering the highest performance across all MLPerf HPC workloads and scenarios, only the NVIDIA platform ran every test, demonstrating remarkable versatility.
In addition to exceptional performance and versatility, the NVIDIA platform is broadly available from both cloud service providers and system makers worldwide. All software used for NVIDIA MLPerf submissions is available from the MLPerf repository, enabling users to reproduce results. All NVIDIA AI software used to achieve these results is also available in the enterprise-grade software suite, NVIDIA AI Enterprise.
Source:: NVIDIA