
At AWS re:Invent 2023, AWS and NVIDIA announced that AWS will be the first cloud provider to offer NVIDIA GH200 Grace Hopper Superchips interconnected with…
At AWS re:Invent 2023, AWS and NVIDIA announced that AWS will be the first cloud provider to offer NVIDIA GH200 Grace Hopper Superchips interconnected with NVIDIA NVLink technology through NVIDIA DGX Cloud and running on Amazon Elastic Compute Cloud (Amazon EC2). This is a game-changing technology for cloud computing.
The NVIDIA GH200 NVL32, a rack-scale solution within NVIDIA DGX Cloud or an Amazon instance, boasts a 32-GPU NVIDIA NVLink domain and a massive 19.5 TB of unified memory. Breaking through the memory constraints of a single system, it is 1.7x faster for GPT-3 training and 2x faster for large language model (LLM) inference compared to NVIDIA HGX H100.
NVIDIA GH200 Grace Hopper Superchip-powered instances in AWS will feature 4.5 TB of HBM3e memory, a 7.2x increase compared to current-generation NVIDIA H100-powered EC2 P5 instances. This enables developers to run larger models, while improving training performance.
Additionally, the CPU to GPU memory interconnect is 900 GB/s, which is 7x faster than PCIe Gen 5. GPUs access CPU memory in a cache-coherent way, extending the total memory available for applications. This is the first use of the NVIDIA GH200 NVL32 scale-out design, a modular reference design for supercomputing, data centers, and cloud infrastructure. It provides a common architecture for GH200 and successor processor configurations.
This post explains the reference design that makes this possible and includes some representative application performance results.
NVIDIA GH200 NVL32
NVIDIA GH200 NVL32 is a rack-scale reference design for NVIDIA GH200 Grace Hopper Superchips connected through NVLink targeted for hyperscale data centers. NVIDIA GH200 NVL32 supports 16 dual NVIDIA Grace Hopper server nodes compatible with the NVIDIA MGX chassis design and can be liquid cooled to maximize compute density and efficiency.
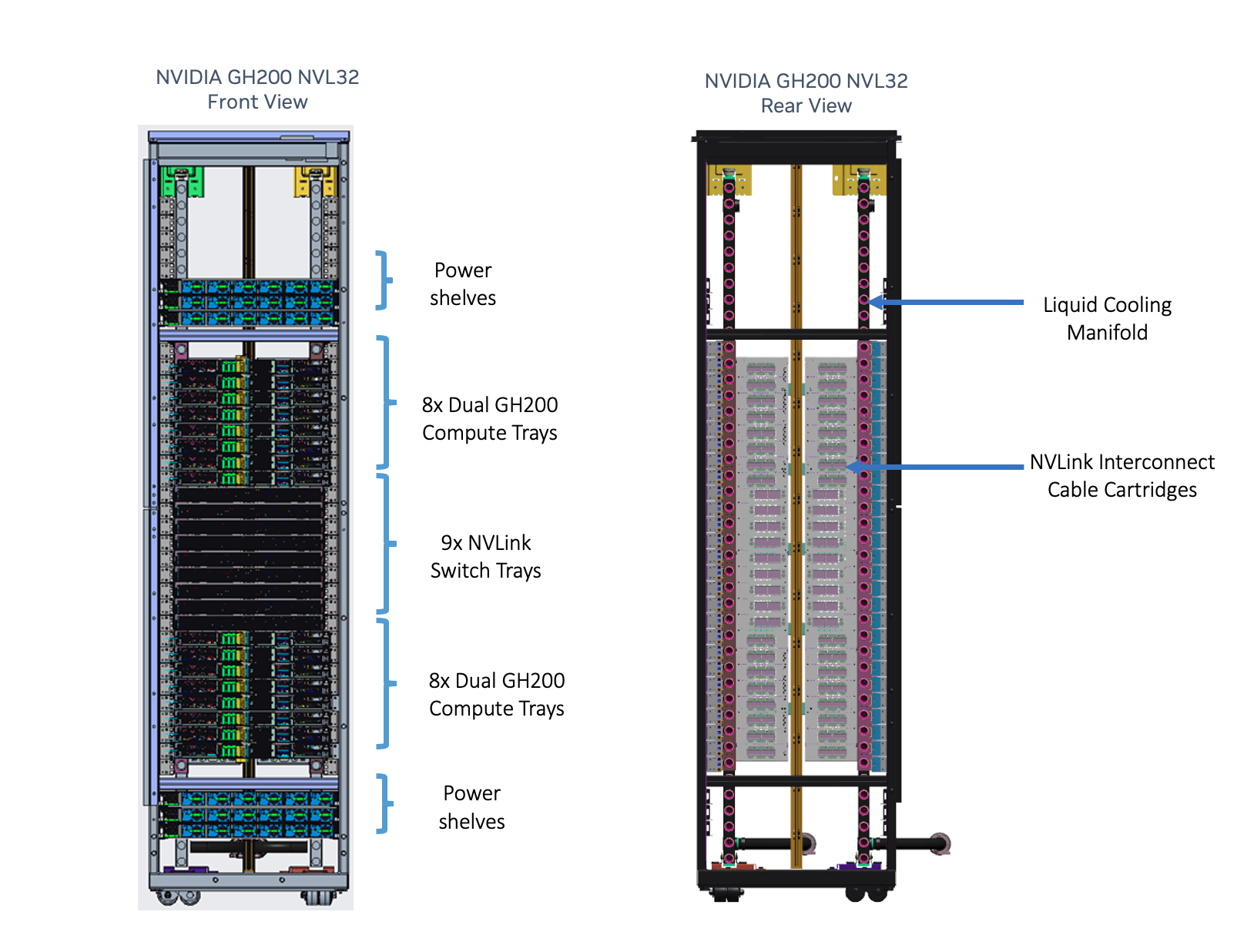 Figure 1. NVIDIA GH200 NVL32 is a rack-scale solution delivering a 32-GPU NVLink domain and 19.5 TB of unified memory
Figure 1. NVIDIA GH200 NVL32 is a rack-scale solution delivering a 32-GPU NVLink domain and 19.5 TB of unified memory
The NVIDIA GH200 Grace Hopper Superchip with a coherent NVLink-C2C creates an NVLink addressable memory address space to simplify model programming. It combines high-bandwidth and low-power system memory, LPDDR5X, and HBM3e to take full advantage of NVIDIA GPU acceleration and high-performance Arm cores in a well-balanced system.
GH200 server nodes are connected with an NVLink passive copper cable cartridge to enable each Hopper GPU to access the memory of any other Grace Hopper Superchip in the network, providing 32 x 624 GB, or 19.5 TB of NVLink addressable memory (Figure 1).
This update to the NVLink Switch System uses the NVLink copper interconnect to connect 32 GH200 GPUs together using nine NVLink switches incorporating third-generation NVSwitch chips. The NVLink Switch System implements a fully connected fat-tree network for all the GPUs in the cluster. For larger scale requirements, scaling with 400 Gb/s InfiniBand or Ethernet delivers incredible performance and an energy-efficient AI supercomputing solution.
NVIDIA GH200 NVL32 is supported by the NVIDIA HPC SDK and the full suite of CUDA, NVIDIA CUDA-X, and NVIDIA Magnum IO libraries, accelerating over 3,000 GPU applications.
Use cases and performance results
NVIDIA GH200 NVL32 is ideal for LLM training and inference, recommender systems, graph neural networks (GNNs), vector databases, and retrieval-augmented generation (RAG) models, as detailed below.
AI training and inference
Generative AI has taken the world by storm, exemplified by the groundbreaking capabilities of services like ChatGPT. LLMs such as GPT-3 and GPT-4 are enabling the integration of AI capabilities into every product in every industry, and their adoption rate is astounding.
ChatGPT became the fastest application to reach 100 million users, achieving that milestone in just 2 months. The demand for generative AI applications is immense and growing exponentially.
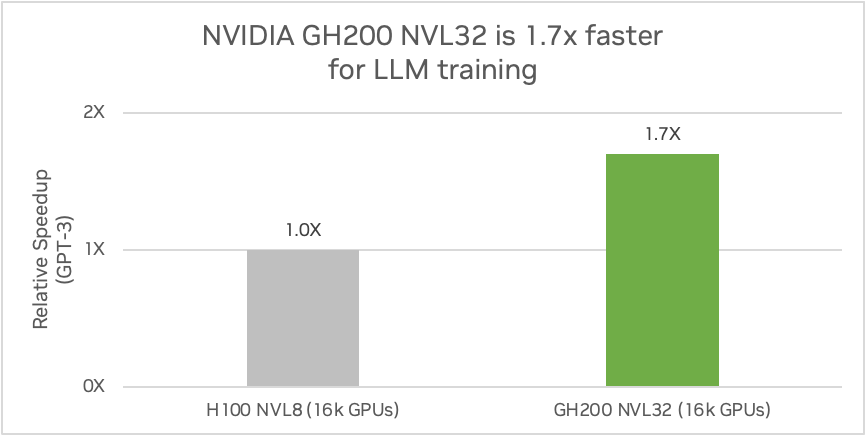 Figure 2. An Ethernet data center with 16K GPUs using NVIDIA GH200 NVL32 will deliver 1.7x the performance of one composed of H100 NVL8, which is an NVIDIA HGX H100 server with eight NVLink-connected H100 GPUs. (Preliminary performance estimates subject to change.)
Figure 2. An Ethernet data center with 16K GPUs using NVIDIA GH200 NVL32 will deliver 1.7x the performance of one composed of H100 NVL8, which is an NVIDIA HGX H100 server with eight NVLink-connected H100 GPUs. (Preliminary performance estimates subject to change.)
LLMs require large-scale, multi-GPU training. The memory requirements for GPT-175B would be 700 GB, as each parameter needs four bytes (FP32). A combination of model parallelism and fast communications is used to avoid running out of memory with smaller memory GPUs.
NVIDIA GH200 NVL32 is built for inference and for training the next generation of LLMs. Breaking through memory, communications, and computational bottlenecks with 32 NVLink-connected GH200 Grace Hopper Superchips, the system can train a trillion-parameter model over 1.7x faster than NVIDIA HGX H100.
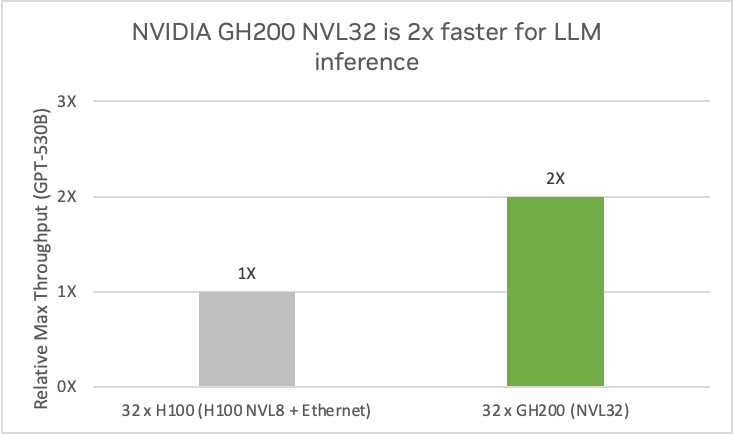 Figure 3. NVIDIA GH200 NVL32 shows 2x faster GPT-3 530B model inference performance compared to H100 NVL8 with 80 GB GPU memory. (Preliminary performance estimates subject to change.)
Figure 3. NVIDIA GH200 NVL32 shows 2x faster GPT-3 530B model inference performance compared to H100 NVL8 with 80 GB GPU memory. (Preliminary performance estimates subject to change.)
Figure 3 shows that the NVIDIA GH200 NVL32 system outperforms four H100 NVL8 systems by 2x on a GPT-530B inference model. The large memory space of NVIDIA GH200 NVL32 also improves operational efficiency, with the ability to store multiple models on the same node and quickly swap models in to maximize utilization.
Recommender systems
Recommender systems are the engine of the personalized internet. They’re used across e-commerce and retail, media and social media, digital ads, and more to personalize content. This drives revenue and business value. Recommenders use embeddings that represent users, products, categories, and context, and can range up to tens of terabytes in size.
A highly accurate recommender system will provide a more engaging user experience, but also requires a larger embedding and more precise recommender. Embeddings have unique characteristics for AI models, requiring large amounts of memory at high bandwidth and lightning-fast networking.
NVIDIA GH200 NVL32 with Grace Hopper provides 7x the amount of fast-access memory compared to four HGX H100 and delivers 7x the bandwidth compared to the PCIe Gen5 connections to the GPU in conventional x86-based designs. It enables 7x more detailed embeddings compared to H100 with x86.
NVIDIA GH200 NVL32 can also deliver up to 7.9x the training performance for models with massive embedding tables. Figure 4 shows a comparison of one GH200 NVL32 system with 144 GB HBM3e memory and 32-way NVLink interconnect compared to four HGX H100 servers with 80 GB HBM3 memory connected with 8-way NVLink interconnect using a DLRM model. The comparisons were made between GH200 and H100 systems using 10 TB embedding tables and using 2 TB embedding tables.
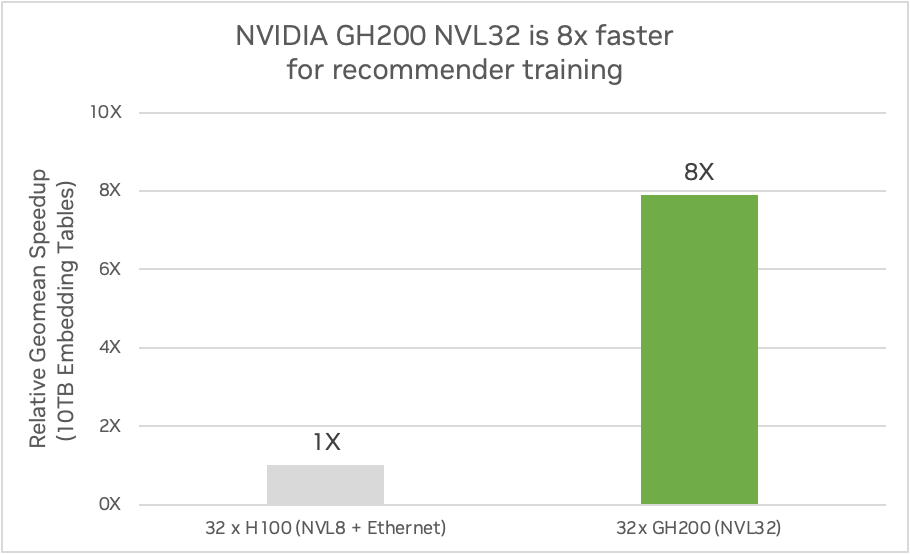 Figure 4. A comparison of one NVIDIA GH200 NVL32 system to four HGX H100 servers on recommender training. (Preliminary performance estimates subject to change.)
Figure 4. A comparison of one NVIDIA GH200 NVL32 system to four HGX H100 servers on recommender training. (Preliminary performance estimates subject to change.)
Graph neural networks
GNNs apply the predictive power of deep learning to rich data structures that depict objects and their relationships as points connected by lines in a graph. Many branches of science and industry already store valuable data in graph databases.
Deep learning is used to train predictive models that unearth fresh insights from graphs. An expanding list of organizations are applying GNNs to improve drug discovery, fraud detection, computer graphics, cybersecurity, genomics, materials science, and recommendation systems. Today’s most complex graphs processed by GNNs have billions of nodes, trillions of edges, and features spread across nodes and edges.
NVIDIA GH200 NVL32 provides massive CPU-GPU memory to store these complex data structures for accelerated computing. Furthermore, graph algorithms often require random accesses over these large datasets storing vertex properties.
These accesses are typically bottlenecked by internode communication bandwidth. The GPU-to-GPU NVLink connectivity of NVIDIA GH200 NVL32 provides massive speedups to such random accesses. GH200 NVL32 can increase GNN training performance by up to 5.8x compared to NVIDIA H100.
Figure 5 shows a comparison of one GH200 NVL32 system with 144 GB HBM3e memory and 32-way NVLink interconnect compared to four HGX H100 servers with 80 GB HBM3 memory connected with 8-way NVLink interconnect using GraphSAGE. GraphSAGE is a general inductive framework to efficiently generate node embeddings for previously unseen data.
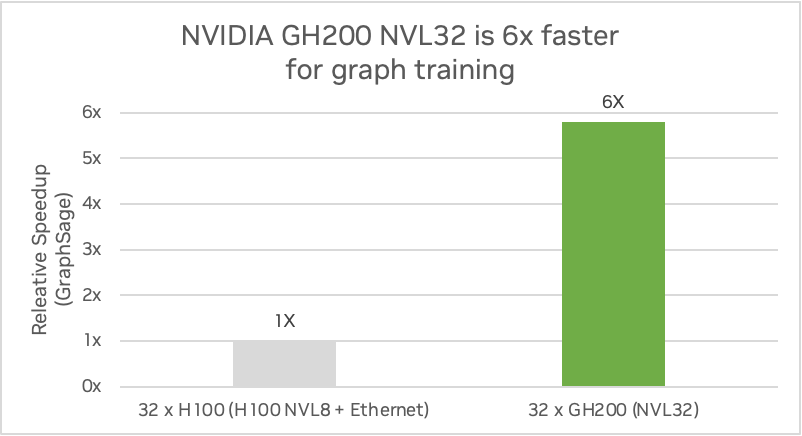 Figure 5. A comparison of one NVIDIA GH200 NVL32 system to four HGX H100 servers on graph training. (Preliminary performance estimates subject to change.)
Figure 5. A comparison of one NVIDIA GH200 NVL32 system to four HGX H100 servers on graph training. (Preliminary performance estimates subject to change.)
Summary
Amazon and NVIDIA have announced that NVIDIA DGX Cloud is coming to AWS. AWS will be the first cloud service provider to offer NVIDIA GH200 NVL32 in DGX Cloud and as an EC2 instance. The NVIDIA GH200 NVL32 solution boasts a 32-GPU NVLink domain and a massive 19.5 TB of unified memory. This setup significantly outperforms previous models in GPT-3 training and LLM inference.
The CPU-GPU memory interconnect of the NVIDIA GH200 NVL32 is remarkably fast, enhancing memory availability for applications. This technology is part of a scalable design for hyperscale data centers, supported by a comprehensive suite of NVIDIA software and libraries, accelerating thousands of GPU applications. NVIDIA GH200 NVL32 is ideal for tasks like LLM training and inference, recommender systems, GNNs, and more, offering significant performance improvements to AI and computing applications.
To learn more, check out the AWS re:Invent Keynote and the NVIDIA GH200 Grace Hopper Superchip Architecture Whitepaper. You can also watch the NVIDIA SC23 Special Address.
Source:: NVIDIA