
In the realm of generative AI, building enterprise-grade large language models (LLMs) requires expertise in collecting high-quality data, setting up the…
In the realm of generative AI, building enterprise-grade large language models (LLMs) requires expertise in collecting high-quality data, setting up the accelerated infrastructure, and optimizing the models.
Developers can begin with pretrained models and fine-tune them for their use case, saving time and getting their solutions faster to market. Developers need an easy way to try out models and evaluate their capabilities by integrating them through APIs. This helps them decide which model is best for their application.
NVIDIA AI Foundation Models
NVIDIA AI Foundation Models are a curated set of community and NVIDIA-built models, optimized for peak performance. Developers can quickly use them directly from their browser through API or graphical user interface, without any setup. The models were optimized with NVIDIA TensorRT-LLM and Activation-aware Weight Quantization (AWQ) to identify the configuration for the highest throughput and lowest latency and run at scale on the NVIDIA accelerated computing stack.
Introducing the NVIDIA Nemotron-3 8B family of LLMs
The NVIDIA Nemotron-3 8B family of models offers a foundation for customers looking to build production-ready generative AI applications. These models are constructed on responsibly sourced datasets and operate at comparable performance to much larger models, making them ideal for enterprise deployments.
A key differentiator of the NVIDIA Nemotron-3 8B family of models is its multilingual capabilities, which make it ideal for global enterprise. Out of the box, these models are proficient in 53 languages, including English, German, Russian, Spanish, French, Japanese, Chinese, Italian, and Dutch.
The family of models also features a range of alignment techniques, including supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and the new NVIDIA SteerLM customization technique, where customers can tune models at inference. These variants provide a variety of starting points for supporting different use cases, whether customizing or running the models from scratch.
The Nemotron-3 8B family of models includes:
- Nemotron-3-8B-Chat-SteerLM, a generative language model based on the NV-Nemotron-3-8B base model that is customized for user control of model outputs during inference using the SteerLM technique
- Nemotron-3-8B-QA, a generative language model based on the NV-Nemotron-3-8B base model further fine-tunes for instructions for Question Answering.
NVIDIA-optimized community models
Additionally, NVIDIA offers leading community models that are optimized using NVIDIA TensorRT-LLM to deliver the highest performance per dollar that organizations can customize for their enterprise applications. These include:
- Llama 2 is one of the most popular LLMs capable of generating text from prompts.
- Stable Diffusion XL is a popular Generative AI model that can create expressive images with text.
- Code Llama is a fine-tuned version of the Llama 2 model that can generate code in several popular languages such as Java, C++, Python, and more.
- Mistral 7B is an LLM that can follow instructions, complete requests, and generate creative text formats.
- Contrastive Language-Image Pre-Training (CLIP) is a popular open-source model that understands images and text together, enabling tasks like image classification and object detection.
As developers identify the right foundation models, there’s an easy path for them to fine-tune and deploy these models either on their own or on NVIDIA-maintained infrastructure through NVIDIA DGX Cloud.
Let’s walk through the steps to experience, customize, and deploy the fine-tuned Llama 2 model.
Experience Llama 2
NVIDIA offers an easy-to-use interface to interact with the Llama 2 model directly from your browser. Simply enter the text in the prompt field, click generate, and the model will begin generating informative responses instantly.
In Figure 1, a user asked the model for an SQL query to retrieve the list of customers who spent at least $50,000 in the first quarter of 2021. The model interpreted the user’s query correctly and provided the answer with a detailed explanation.
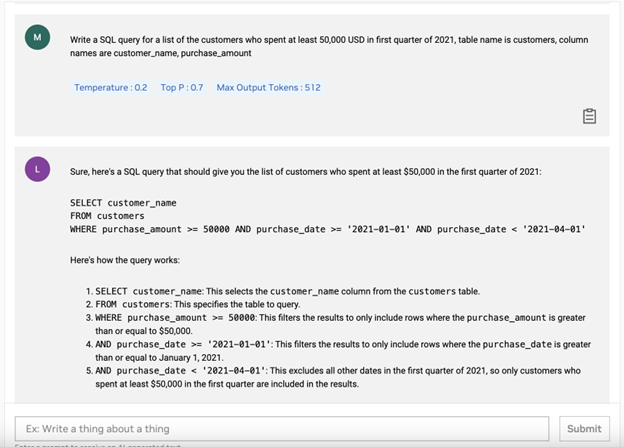 Figure 1. Image of the Llama 2 model response for an SQL query to get the list of customers who spent at least $50,000 in the first quarter of 2021
Figure 1. Image of the Llama 2 model response for an SQL query to get the list of customers who spent at least $50,000 in the first quarter of 2021
Developers are often more interested in working with code. NVIDIA also offers an API widget directly in the browser, making it seamless to experience the models through an API.
To try the in-browser API, click on API mode, and select the language you prefer from the dropdown. Figure 2 shows the API instructions for calling the API through cURL.
 Figure 2. Picture of the in-browser API widget for the Llama 2 model for cURL
Figure 2. Picture of the in-browser API widget for the Llama 2 model for cURL
Customize the model
It’s often the case that the models don’t meet the developer’s needs as-is and must be fine-tuned with proprietary data. NVIDIA offers various paths for customizing the available models.
NVIDIA NeMo is an end-to-end, enterprise-grade cloud-native framework for developers to build, customize, and deploy generative AI models with billions of parameters. NeMo also provides APIs to fine-tune LLMs like Llama 2.
To get started quickly, we are offering an NVIDIA LaunchPad lab—a universal proving ground, offering comprehensive testing of the latest NVIDIA enterprise hardware and software.
The following example in the LaunchPad lab experience fine-tunes a Llama 2 7B text-to-text model using a custom dataset to perform a Question-Answering task better.
dataset = load_dataset("aisquared/databricks-dolly-15k")A sample of the data is shown. The datasets can be swapped to fit specific use cases.
{
"question": "When did Virgin Australia start operating?",
"context": "Virgin Australia, the trading name of Virgin Australia Airlines Pty Ltd, is an Australian-based airline. It is the largest airline by fleet size to use the Virgin brand. It commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.[3] It suddenly found itself as a major airline in Australia's domestic market after the collapse of Ansett Australia in September 2001. The airline has since grown to directly serve 32 cities in Australia, from hubs in Brisbane, Melbourne and Sydney.[4]",
"answer": "Virgin Australia commenced services on 31 August 2000 as Virgin Blue, with two aircraft on a single route.",
"taskname": "genqa"
}The model accurately grasped the context and responded with a “Yes.” Fine-tuning the model enabled it to respond accurately to our questions from the provided context.
"input": "Context: The Auto Chef Master is a personal kitchen robot that effortlessly turns raw ingredients into gourmet meals with the precision of a Michelin-star chef. The Eco Lawn Mower is a solar powered high-tech lawn mower that provides an eco-friendly and efficient way to maintain your lawn. Question: Is the lawn mower product solar powered?
Answer:",
"pred": "Yes",
"label": "Yes, the Eco Lawn Mower is solar powered.",
"taskname": "genqa"
}Deploy the model
NVIDIA AI Foundation Endpoints provide fully serverless and scalable APIs that can be deployed on either your own or NVIDIA DGX Cloud. Complete this form to get started with AI Foundation Endpoints.
You can also deploy on your own cloud or data center infrastructure with NVIDIA AI Enterprise. This end-to-end, cloud-native software platform accelerates the development and deployment of production-grade generative AI with enterprise-grade security, stability, manageability, and support. When you are ready to move from experimentation to production, you can leverage NVIDIA AI Enterprise for enterprise-grade runtimes to fine-tune and deploy these models.
Learn more
In this post, we explored how NVIDIA AI Foundation models can help enterprise developers identify the most suitable model for their use cases. We looked at the features of these models, including an easy-to-use interface to trial them, and how to fine-tune and deploy them.
Explore the different AI Foundation models available on the NVIDIA NGC Catalog and find the right model for you.
Source:: NVIDIA