
Graphs form the foundation of many modern data and analytics capabilities to find relationships between people, places, things, events, and locations across…
Graphs form the foundation of many modern data and analytics capabilities to find relationships between people, places, things, events, and locations across diverse data assets. According to one study, by 2025 graph technologies will be used in 80% of data and analytics innovations, which will help facilitate rapid decision making across organizations.
When working with graphs containing millions of nodes, the execution duration of algorithms such as Louvain on a CPU can stretch up to several hours. This prolonged processing time not only impacts developer productivity, but also leads to suboptimal overall performance outcomes.
Harnessing the parallel processing power of GPUs can significantly accelerate graph training times. The benchmark results demonstrate the remarkable potential of GPU acceleration in outpacing CPU-based computations by more than 100x.
This significant increase in speed showcases the clear advantages of incorporating GPUs into graph analytics. This post explains the architecture behind achieving these 100x performance gains.
Understanding the components
At the core of this game-changing architecture are the following three key components, each playing a crucial role.
GPU acceleration with cuGraph
cuGraph, the NVIDIA GPU-accelerated graph analytics library, takes the lead in turbocharging your graph computations. Traditional CPU-based graph processing can often be a bottleneck, especially when dealing with large-scale graphs. cuGraph unleashes the raw processing power of NVIDIA A100 GPUs, specifically designed for high-performance computing (HPC), to handle complex graph algorithms with unrivaled speed.
Graph algorithms such as PageRank, Louvain, and Betweenness Centrality are inherently parallelizable, making them ideal candidates for GPU acceleration. The thousands of cores in the NVIDIA A100 GPUs enable simultaneous processing of data, drastically reducing computation times compared to CPU-based approaches.
TigerGraph graph database capabilities
While cuGraph optimizes graph analytics with GPUs, the TigerGraph graph database complements the GPU acceleration with its efficiency in storing and querying interconnected data. TigerGraph’s distributed architecture, along with its Turing-complete GSQL language and native support for graph data, enable it to handle complex relationships and real-time queries and updates with remarkable flexibility.
TigerGraph’s data structure, known as the Graph Model, provides a highly scalable representation of graph data. It optimizes data locality and traversal, reducing I/O bottlenecks during graph processing. The seamless integration of TigerGraph with cuGraph ensures that data flows effortlessly between the graph database and the GPU-accelerated analytics, maximizing performance gains.
Enhancing GSQL with advanced functionality
To complete this fusion, ZettaBolt has designed custom user-defined functions (UDFs) that act as the bridge between TigerGraph and cuGraph. UDFs enable you to write and seamlessly integrate your own C++ code into the TigerGraph ecosystem.
They enable communication between GSQL and cuGraph’s Python service over the Thrift RPC layer. This enables the smooth flow of data and computations between the graph database and the GPU-accelerated analytics, unlocking new possibilities for graph algorithm optimization.
Traditional and accelerated PageRank calculation
This section explores how to put this powerful GPU-CPU fusion to work with practical examples. It introduces two distinct methods for running PageRank calculations: the traditional CPU-based tg_pagerank and the accelerated accel_pagerank that leverages the GPU-CPU fusion architecture.
Traditional approach: tg_pagerank
This traditional approach employs the tg_pagerank query to calculate PageRank scores. It relies on CPU-based processing and is suitable for scenarios where GPU acceleration is not available or required. For more details, see tigergraph/gsql-graph-algorithms on GitHub.
Query tg_pagerank(
v_type, # Vertex type representing persons in the graph
e_type", # Edge type representing friendships between persons
max_change=0.001, # Maximum change in PageRank scores for convergence
maximum_iteration=25,# Maximum number of iterations for convergence
damping=0.85, # Damping factor for the PageRank calculation
top_k=100, # Number of top results to display
print_results=True,# Whether to print the PageRank results
result_attribute="", # Optional attribute to store the PageRank results
file_path="", # Optional file path to save the results
display_edges=False# Whether to display the edges during computation
)
Accelerated approach: accel_pagerank
Accelerate your PageRank computations with accel_pagerank. This query harnesses the GPU-CPU fusion architecture to significantly boost performance, making it ideal for large-scale graph processing (GSQL).
QUERY accel_pagerank(
INT numServers, #Number of servers to distribute computation
INT seg_size, #Segment size for processing
STRING v_type, #Vertex type
STRING e_type, #Edge type
FLOAT max_change=0.00001,#Maximum change threshold for convergence
INT maximum_iteration=50,# Maximum number of iterations
FLOAT damping=0.85, #Damping factor for PageRank calculation
INT top_k=100, #Top-k results to retrieve
BOOL print_accum=TRUE, #Print accumulated results (default: TRUE)
STRING result_attr="", #Result attribute name
STRING file_path, #File path for storing results
BOOL display_edges=FALSE,#Display edges in results (default: FALSE)
STRING profile_path, #Path for profiling data
STRING graph_name, #Name of the graph
STRING server_name, #Server address
UINT port, #Port for communication
UINT total_segments, #Total segments for computation
STRING tmp_dir, #Temporary directory for processing
INT streaming_limit=300000, #Streaming data limit
BOOL cache_graph=FALSE #Cache the graph (default: FALSE)
)
Seamless transition
Switching between the traditional tg_pagerank and accelerated accel_pagerank queries is as simple as changing your API call. You don’t need to worry about the underlying technical details. The transition is designed to be effortless, so you can easily adapt the graph processing to your needs. Whether you require the raw power of GPU acceleration or prefer the familiarity of CPU-based processing, your graph analytics will seamlessly align with your requirements.
Creating the architecture
This section walks you through the step-by-step process of the architecture, where the magic of GPU-CPU fusion comes to life.
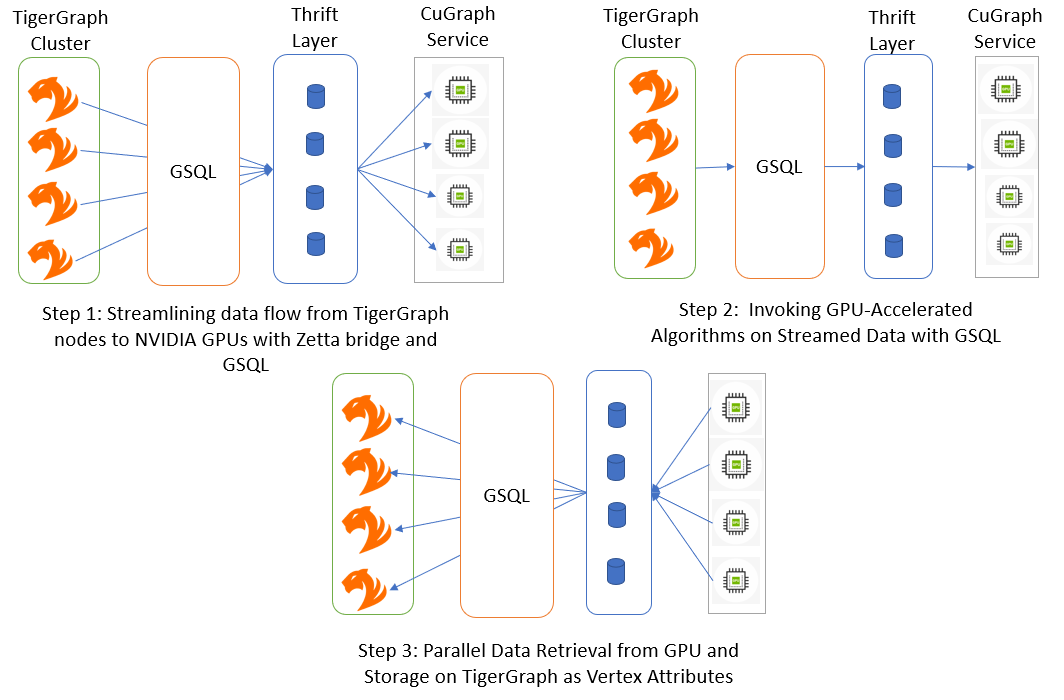 Figure 1. Process for high-performance graph analytics with TigerGraph, cuGraph, and GSQL
Figure 1. Process for high-performance graph analytics with TigerGraph, cuGraph, and GSQL
Streaming edges from TigerGraph to cuGraph
The journey begins with the efficient streaming of edges from TigerGraph to cuGraph for GPU-accelerated processing. As the edges are read in parallel from TigerGraph, they are collected in batches until the edge count reaches a predetermined threshold (1 million, for example). Once the batch is complete, it is flushed to cuGraph through the Thrift RPC layer.
Streaming edges in batches optimizes data transfer, reducing overhead and ensuring that the GPU-accelerated processing receives a continuous flow of data. The streaming process efficiently prepares the graph data for subsequent GPU-based computations.
GPU-accelerated computation with PageRank
With the entire graph data now residing in cuGraph memory on the NVIDIA A100 GPUs, the architecture is poised to unleash its true potential.
Consider the classic PageRank algorithm as an example. PageRank calculates the importance of nodes in a graph based on the number and quality of incoming links. The algorithm is an excellent candidate for GPU acceleration because it is iterative and parallelizable. cuGraph’s GPU-based PageRank algorithm processes the entire graph in parallel, efficiently traversing the network and updating the PageRank scores iteratively.
Obtaining results using Thrift RPC layer
Once the GPU-accelerated computation is complete, it’s time to get the results. The PageRank scores, now residing in cuGraph memory, are obtained using the Thrift RPC layer and brought back to the UDFs.
Achieving the 100x speedup breakthrough
The performance comparisons speak for themselves—real-world benchmarks demonstrate the awe-inspiring results achieved with this hybrid architecture. The 100x speedup is a significant leap in graph algorithm performance.
With this architecture, developers gain a competitive edge in diverse domains including social networks, recommendation systems, graph-based machine learning (ML), and more.
Graph algorithm performance comparison
This benchmark demonstrates the performance of two prominent graph algorithms, Louvain and PageRank, using TigerGraph and TigerGraph alongside cuGraph on a high-performance GPU infrastructure powered by the NVIDIA A100 80GB GPUs and the AMD EPYC 7713 64-Core Processor, with a single-node configuration featuring 512GB of RAM.
Benchmark dataset
Graphalytics, developed by the Linked Data Benchmark Council (LDBC), is a comprehensive benchmark suite designed for evaluating the performance of graph database management systems (GDBMSs) and graph processing frameworks. It offers real-world datasets, diverse workloads, and a range of graph algorithms to help researchers and organizations assess system efficiency and scalability. For more information, see LDBC Graphalytics Benchmark.
GraphLouvainPageRankVerticesEdgesCPU
(sec)CPU + GPU
(sec)Speedup
(x)CPU
(sec)CPU + GPU
(sec)Speedup
(x)2,396,65764,155,7351,26571721,03071474,610,222129,333,6772,288121882,142191138,870,942260,379,5204,723271744,5423812017,062,472523,602,8319,977771308,64346188Table 1. The TigerGraph CPU-based solution compared to its cuGraph-accelerated counterpart
Best practices and considerations
As you embark on your own GPU-CPU fusion journey, consider the following best practices and considerations to optimize your graph analytics.
Algorithm selection for GPU acceleration
The synergy between CPU and GPU is crucial in selecting the right algorithms for GPU acceleration. While some graph algorithms are highly parallelizable and benefit significantly from the thousands of cores in NVIDIA A100 GPUs, others may require more sequential processing, making CPU a better choice. By strategically offloading parallelizable algorithms to the GPU, you can achieve remarkable speedup and efficiency in graph computations, while leveraging the strengths of both CPU and GPU for optimal performance.
Efficient data preprocessing
The efficient data preprocessing phase is where CPU and GPU synergy plays a vital role. While TigerGraph’s powerful graph database capabilities handle the initial data retrieval and processing on the CPU, the GPU-accelerated cuGraph library efficiently streams and batches the graph data for further computation. The parallel processing power of the GPU ensures a continuous flow of data, minimizing overhead and bottlenecks during the data transfer phase, leading to a seamless flow of data for accelerated analytics.
GPU memory management
Effective GPU memory management is a critical consideration to avoid performance bottlenecks during graph computations. Both CPU and GPU play significant roles in this process. The CPU ensures efficient data handling and allocation before transferring the relevant data to the GPU for processing. On the GPU side, the parallel processing capabilities efficiently utilize the available memory to perform computations on large-scale graphs. The tight collaboration between CPU and GPU in memory management contributes to smooth, optimized GPU-accelerated graph processing.
Future work and possibilities
There are exciting possibilities and enhancements to explore in the area of GPU-CPU fusion for graph analytics. Some key areas for future work and potential developments are detailed below.
Reducing GPU memory footprint
Optimizing GPU memory use is essential for handling massive graphs and increasing algorithm scalability. Future areas of focus include memory-efficient data structures, graph partitioning techniques, and smart caching mechanisms to reduce GPU memory footprint. Efficiently managing memory enables processing even larger graphs with improved performance.
Expanding the graph algorithm library
The current architecture supports graph algorithms like PageRank, Louvain, and Betweenness Centrality. However, there is a vast landscape of graph algorithms waiting to be explored. Expanding the graph algorithm library to include more diverse and complex algorithms will enable developers to address a broader range of graph analytics challenges.
Integrating support for GNN and other RAPIDS libraries
Generalized graph neural networks (GNNs) have become a popular choice for various graph-related tasks. Integrating support for GNN and other RAPIDS libraries, such as cuML and cuGraphML, will enrich the architecture with cutting-edge deep learning capabilities for graph-based ML tasks. This integration will enable seamless exploration of both traditional graph algorithms and emerging ML models, fostering innovation and versatility in graph analytics.
Performance optimization and tuning
Continuous performance optimization and tuning are critical to unlocking the full potential of GPU-CPU fusion. Conducting in-depth profiling and benchmarking, leveraging GPU-specific optimizations, and fine-tuning algorithms for specific graph characteristics will lead to more speedups and efficiency gains.
Summary
This post has explored how the seamless blending of GPUs and CPUs can supercharge graph algorithm performance. The power of TigerGraph’s database prowess combined with cuGraph GPU acceleration creates an unbeatable partnership. The smooth data flow achieves an astonishing 100x speed boost, propelling graph analytics into new frontiers.
GPU-CPU fusion is set to reshape how teams explore data and navigate intricate networks and relationships. From social networks to machine learning, GPU-CPU fusion unlocks endless possibilities. Future areas of work include optimizing memory efficiency, broadening algorithm coverage, and fine-tuning performance, ensuring that this architecture remains at the forefront of graph analytics. Embrace the fusion and redefine the boundaries of data exploration.
Ready to get started with accelerated graph processing? If you have TigerGraph (3.9.X) and NVIDIA GPUs (with RAPIDS support), reach out to TigerGraph or Zettabolt to express your interest in exploring accelerated graph processing. They will guide you through the initial steps, provide you with the necessary information, and assist in setting up the infrastructure for accelerated graph processing.
Once the infrastructure is in place, you’ll have access to accelerated queries designed to optimize your graph processing tasks. These queries harness the power of NVIDIA GPUs and the TigerGraph platform for enhanced performance. Explore and benchmark the accelerated graph processing capabilities to experience significantly improved performance in graph analytics.
TigerGraph and Zettabolt will continue to provide assistance and answer questions as you explore accelerated graph processing and new possibilities for handling large-scale graph data efficiently.
Source:: NVIDIA