
With the advent of large language models (LLMs) such as GPT-3, Megatron-Turing, Chinchilla, PaLM-2, Falcon, and Llama 2, remarkable progress in natural language…
With the advent of large language models (LLMs) such as GPT-3, Megatron-Turing, Chinchilla, PaLM-2, Falcon, and Llama 2, remarkable progress in natural language generation has been made in recent years. However, despite their ability to produce human-like text, foundation LLMs can fail to provide helpful and nuanced responses aligned with user preferences.
The current approach to improving LLMs involves supervised fine-tuning (SFT) on human demonstrations followed by reinforcement learning from human feedback (RLHF). While RLHF can enhance performance, it has some limitations, including training complexity and a lack of user control.
To overcome these challenges, the NVIDIA Research Team has developed and released SteerLM, a new four-step technique that simplifies LLM customization while enabling dynamic steering of model outputs based on attributes you specify, as part of NVIDIA NeMo. This post provides an in-depth look at how SteerLM works, why it marks a significant advance, and how to train a SteerLM model.
Language models bring promise and potential pitfalls
By pretraining on massive text corpora, LLMs acquire broad linguistic capabilities and world knowledge. Researchers have successfully applied LLMs to diverse natural language processing (NLP) tasks like translation, question answering, and text generation. However, these models often fail to follow user-provided instructions, and instead produce generic, repetitive, or nonsensical text. Access to human feedback is essential for customizing LLMs.
Opportunities with existing approaches
SFT augments model capabilities, but causes responses to become short and mechanical. RLHF further optimizes models by favoring human-preferred responses over alternatives. However, RLHF requires an extremely complex training infrastructure, hindering broad adoption.
Introducing SteerLM
SteerLM leverages a supervised fine-tuning method that empowers you to control responses during inference. It overcomes the limitations of prior alignment techniques, and consists of four key steps:
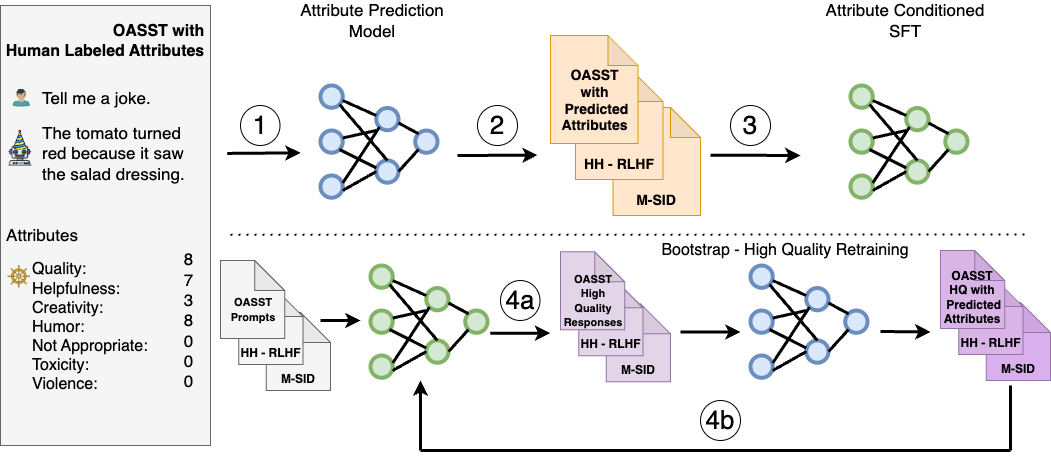 Figure 1. The four steps of SteerLM
Figure 1. The four steps of SteerLM
By relying solely on the standard language modeling objective, SteerLM simplifies alignment compared to RLHF. It supports user-steerable AI by enabling you to adjust attributes at inference time. This enables the developer to define preferences relevant to the application, unlike other techniques that require using predetermined preferences.
Unlocking customizable AI with user steering
A key innovation of SteerLM is enabling the user to specify desired attributes (humor level and toxicity tolerance, for example) at inference time when querying models. You can move from running one customization with SteerLM, to serving many use cases at inference time.
SteerLM empowers a range of applications, including:
- Gaming: Vary non-player character dialogue for game scenarios. To learn more, see NVIDIA ACE Adds Emotion to AI-Powered NPCs with NeMo SteerLM.
- Education: Maintain formal and helpful persona for student queries.
- Enterprise: Serve multiple teams in an organization with personalized capabilities.
- Accessibility: Curb undesired model biases by controlling sensitive attributes.
Such flexibility promises to unlock a new generation of bespoke AI systems tailored to individual needs.
Democratizing state-of-the-art customization through simplified training
Compared to the specialized infrastructure required for other advanced customization techniques, the straightforward training scheme of SteerLM makes state-of-the-art customization capabilities more accessible to developers. Its performance clearly demonstrates that techniques like reinforcement learning are not required for robust instruction tuning.
Leveraging standard techniques such as SFT simplifies the complexity, requiring minimal changes to infrastructure and code. Reasonable results can be achieved with limited hyperparameter optimization.
Overall, this leads to a simple and practical approach to obtaining highly accurate customized LLMs. In our experiments, SteerLM 43B achieved state-of-the-art performance on the Vicuna benchmark, outperforming existing RLHF models like LLaMA 30B RLHF. Specifically, SteerLM 43B obtained an average score of 655.75 on the Vicuna automatic evaluation, compared to scores of 646.25 for Guanaco 65B and 612.75 for LLaMA 30B RLHF.
These results highlight that the straightforward training process of SteerLM can lead to customized LLMs with accuracy on par with more complex RLHF techniques. Through simplified training, SteerLM makes achieving such high levels of accuracy more accessible, enabling easier democratization of customization among developers.
For more details, see our paper, SteerLM: Attribute Conditioned SFT as an (User-Steerable) Alternative to RLHF. You can also get information about how to experiment with a Llama 2 13B model customized using the SteerLM method.
How to train a SteerLM model
This section is a step-by-step tutorial that walks you through how to run a full SteerLM pipeline on OASST data with a 2B NeMo LLM model. It includes the following:
- Data cleaning and preprocessing
- Training the attribute prediction (value model)
- Training the attribute-conditioned SFT (SteerLM model)
- Inference on the SteerLM model with different attribute values
Step 1: Install requirements
Start by installing the necessary Python libraries:
pip install fire langchain==0.0.133Get access to NeMo Framework.
Step 2: Download and subset data
This tutorial uses a small subset of the OASST dataset. OASST contains open-domain conversations with human annotations for 13 different quality attributes.
First download and subset it:
mkdir -p data
cd data
wget https://huggingface.co/datasets/OpenAssistant/oasst1/resolve/main/2023-04-12_oasst_all.trees.jsonl.gz
gunzip -f 2023-04-12_oasst_all.trees.jsonl.gz
mv 2023-04-12_oasst_all.trees.jsonl data.jsonl
head -5000 data.jsonl > subset_data.jsonl
cd -Step 3: Download Llama 2 LLM model and tokenizer and convert
Download the Llama 2 7B LLM model and tokenizer into the models folder.
Then convert the Llama 2 LLM into .nemo format:
python NeMo/scripts/nlp_language_modeling/convert_hf_llama_to_nemo.py --in-file /path/to/llama --out-file /output_path/llama7b.nemoUntar the .nemo file to obtain the tokenizer in NeMo format:
tar /llama7b.nemo
mv ba4632640484461f8ae9d61f6dfe0d0b_tokenizer.model tokenizer.model
The prefix for the tokenizer would be different when extracted. Ensure that the correct tokenizer file is used when running the preceding command.
Step 4: Preprocess OASST data
Preprocess the data using the NeMo preprocessing scripts. Then create separate text-to-value and value-to-text versions:
python scripts/nlp_language_modeling/sft/preprocessing.py
--input_file=data/subset_data.jsonl
--output_file_prefix=data/subset_data_output
--mask_role=User
--type=TEXT_TO_VALUE
--split_ratio=0.95
--seed=10
python scripts/nlp_language_modeling/sft/preprocessing.py
--input_file=data/subset_data.jsonl
--output_file_prefix=data/subset_data_output_v2t
--mask_role=User
--type=VALUE_TO_TEXT
--split_ratio=0.95
--seed=10
Step 5: Clean text-to-value data
Running the following script will remove the records if all the tokens are masked due to truncation by sequence length.
python scripts/nlp_language_modeling/sft/data_clean.py
--dataset_file=data/subset_data_output_train.jsonl
--output_file=data/subset_data_output_train_clean.jsonl
--library sentencepiece
--model_file tokenizer.model
--seq_len 4096
python scripts/nlp_language_modeling/sft/data_clean.py
--dataset_file=data/subset_data_output_val.jsonl
--output_file=data/subset_data_output_val_clean.jsonl
--library sentencepiece
--model_file tokenizer.model
--seq_len 4096
Step 6: Train the value model on cleaned OASST data
For this tutorial, train the value model for 1K steps. Note that we recommend training much longer on more data to get a good value model.
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py
++trainer.limit_val_batches=10
trainer.num_nodes=1
trainer.devices=2
trainer.max_epochs=null
trainer.max_steps=1000
trainer.val_check_interval=100
trainer.precision=bf16
model.megatron_amp_O2=False
model.restore_from_path=/model/llama7b.nemo
model.tensor_model_parallel_size=2
model.pipeline_model_parallel_size=1
model.optim.lr=5e-6
model.optim.name=distributed_fused_adam
model.optim.weight_decay=0.01
model.answer_only_loss=True
model.activations_checkpoint_granularity=selective
model.activations_checkpoint_method=uniform
model.data.chat=True
model.data.train_ds.max_seq_length=4096
model.data.train_ds.micro_batch_size=1
model.data.train_ds.global_batch_size=1
model.data.train_ds.file_names=[data/subset_data_output_train_clean.jsonl]
model.data.train_ds.concat_sampling_probabilities=[1.0]
model.data.train_ds.num_workers=0
model.data.train_ds.hf_dataset=True
model.data.train_ds.prompt_template='{input}{output}'
model.data.train_ds.add_eos=False
model.data.validation_ds.max_seq_length=4096
model.data.validation_ds.file_names=[data/subset_data_output_val_clean.jsonl]
model.data.validation_ds.names=["oasst"]
model.data.validation_ds.micro_batch_size=1
model.data.validation_ds.global_batch_size=1
model.data.validation_ds.num_workers=0
model.data.validation_ds.metric.name=loss
model.data.validation_ds.index_mapping_dir=/indexmap_dir
model.data.validation_ds.hf_dataset=True
model.data.validation_ds.prompt_template='{input}{output}'
model.data.validation_ds.add_eos=False
model.data.test_ds.max_seq_length=4096
model.data.test_ds.file_names=[data/subset_data_output_val_clean.jsonl]
model.data.test_ds.names=["oasst"]
model.data.test_ds.micro_batch_size=1
model.data.test_ds.global_batch_size=1
model.data.test_ds.num_workers=0
model.data.test_ds.metric.name=loss
model.data.test_ds.hf_dataset=True
model.data.test_ds.prompt_template='{input}{output}'
model.data.test_ds.add_eos=False
exp_manager.explicit_log_dir="/home/value_model/"
exp_manager.create_checkpoint_callback=True
exp_manager.checkpoint_callback_params.monitor=val_loss
exp_manager.checkpoint_callback_params.mode=minStep 7: Generate annotations
To generate annotation, run the following command in the background to run an inference server:
python examples/nlp/language_modeling/megatron_gpt_eval.py
gpt_model_file=/models/
pipeline_model_parallel_split_rank=0
server=True
tensor_model_parallel_size=1
pipeline_model_parallel_size=1
trainer.precision=bf16
trainer.devices=1
trainer.num_nodes=1
web_server=False
port=1424
Now execute:
python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_train.jsonl --output_file_name=data/subset_data_v2t_train_value_output.jsonl --port_num=1424
python scripts/nlp_language_modeling/sft/attribute_annotate.py --batch_size=1 --host=localhost --input_file_name=data/subset_data_output_v2t_val.jsonl --output_file_name=data/subset_data_v2t_val_value_output.jsonl --port_num=1424
Step 8: Clean the value-to-text data
Remove the record if all tokens are masked after truncation by sequence length:
python scripts/data_clean.py
--dataset_file=data/subset_data_v2t_train_value_output.jsonl
--output_file=data/subset_data_v2t_train_value_output_clean.jsonl
--library sentencepiece
--model_file tokenizer.model
--seq_len 4096
python scripts/data_clean.py
--dataset_file=data/subset_data_v2t_val_value_output.jsonl
--output_file=data/subset_data_v2t_val_value_output_clean.jsonl
--library sentencepiece
--model_file tokenizer.model
--seq_len 4096Step 9: Train the SteerLM model
For the purposes of this tutorial, the SteerLM model is trained for 1K steps. Note that we recommend training much longer and on more data to get a well-tuned model.
python examples/nlp/language_modeling/tuning/megatron_gpt_sft.py
++trainer.limit_val_batches=10
trainer.num_nodes=1
trainer.devices=2
trainer.max_epochs=null
trainer.max_steps=1000
trainer.val_check_interval=100
trainer.precision=bf16
model.megatron_amp_O2=False
model.restore_from_path=/model/llama7b.nemo
model.tensor_model_parallel_size=2
model.pipeline_model_parallel_size=1
model.optim.lr=5e-6
model.optim.name=distributed_fused_adam
model.optim.weight_decay=0.01
model.answer_only_loss=True
model.activations_checkpoint_granularity=selective
model.activations_checkpoint_method=uniform
model.data.chat=True
model.data.train_ds.max_seq_length=4096
model.data.train_ds.micro_batch_size=1
model.data.train_ds.global_batch_size=1
model.data.train_ds.file_names=[data/subset_data_v2t_train_value_output_clean.jsonl]
model.data.train_ds.concat_sampling_probabilities=[1.0]
model.data.train_ds.num_workers=0
model.data.train_ds.prompt_template='{input}{output}'
model.data.train_ds.add_eos=False
model.data.validation_ds.max_seq_length=4096
model.data.validation_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl]
model.data.validation_ds.names=["oasst"]
model.data.validation_ds.micro_batch_size=1
model.data.validation_ds.global_batch_size=1
model.data.validation_ds.num_workers=0
model.data.validation_ds.metric.name=loss
model.data.validation_ds.index_mapping_dir=/indexmap_dir
model.data.validation_ds.prompt_template='{input}{output}'
model.data.validation_ds.add_eos=False
model.data.test_ds.max_seq_length=4096
model.data.test_ds.file_names=[data/subset_data_v2t_val_value_output_clean.jsonl]
model.data.test_ds.names=["oasst"]
model.data.test_ds.micro_batch_size=1
model.data.test_ds.global_batch_size=1
model.data.test_ds.num_workers=0
model.data.test_ds.metric.name=loss
model.data.test_ds.prompt_template='{input}{output}'
model.data.test_ds.add_eos=False
exp_manager.explicit_log_dir="/home/steerlm_model/"
exp_manager.create_checkpoint_callback=True
exp_manager.checkpoint_callback_params.monitor=val_loss
exp_manager.checkpoint_callback_params.mode=min Step 10: Inference
To start inference, run an inference server in the background using the following command:
python examples/nlp/language_modeling/megatron_gpt_eval.py
gpt_model_file=/models/
pipeline_model_parallel_split_rank=0
server=True
tensor_model_parallel_size=1
pipeline_model_parallel_size=1
trainer.precision=bf16
trainer.devices=1
trainer.num_nodes=1
web_server=False
port=1427Next, create Python helper functions:
def get_answer(question, max_tokens, values, eval_port='1427'):
prompt = f"""System
A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user's questions.
User
{question}
Assistant
{values}
"""
prompts = [prompt]
data = {
"sentences": prompts,
"tokens_to_generate": max_tokens,
"top_k": 1,
'greedy': True,
'end_strings': ["", "quality:", "quality:4", "quality:0"]
}
url = f"http://localhost:{eval_port}/generate"
response = requests.put(url, json=data)
json_response = response.json()
response_sentence = json_response['sentences'][0][len(prompt):]
return response_sentence
def encode_labels(labels):
items = []
for key in labels:
value = labels[key]
items.append(f'{key}:{value}')
return ','.join(items)
Next, change the values below to steer the language model:
values = OrderedDict([
('quality', 4),
('toxicity', 0),
('humor', 0),
('creativity', 0),
('violence', 0),
('helpfulness', 4),
('not_appropriate', 0),
('hate_speech', 0),
('sexual_content', 0),
('fails_task', 0),
('political_content', 0),
('moral_judgement', 0),
])
values = encode_labels(values)
Finally, ask questions and generate responses:
question = """Where and when did techno music originate?""" print (get_answer(question, 4096, values))
SteerLM users can perform additional bootstrapping steps using the scripts and utilities mentioned in this tutorial. This step can help further improve model accuracy on different benchmarks.
The future of AI with SteerLM
SteerLM provides a novel technique for realizing a new generation of AI systems aligned with human preferences in a controllable manner. Its conceptual simplicity, performance gains, and customizability highlight the transformative possibilities of user-steerable AI. SteerLM is now available as open-source software, accessible through the NVIDIA/NeMo GitHub repo. You can also get information about how to experiment with a Llama 2 13B model customized using the SteerLM method.
For full enterprise security and support, SteerLM will be integrated into NVIDIA NeMo, a rich framework for building, customizing, and deploying large generative AI models. The SteerLM method works on all models supported on NeMo, including popular community-built pretrained LLMs such as Llama 2, Falcon LLM, and MPT. We hope our work catalyzes further research into developing models that empower users rather than constrain them. The future of AI is steerable with SteerLM.
Acknowledgments
We would like to thank Xianchao Wu and Oleksii Kuchaiev for contributing to this post and to the inception of SteerLM.
Source:: NVIDIA