
Large language models offer incredible new capabilities, expanding the frontier of what is possible with AI. But their large size and unique execution…
Large language models offer incredible new capabilities, expanding the frontier of what is possible with AI. But their large size and unique execution characteristics can make them difficult to use in cost-effective ways.
NVIDIA has been working closely with leading companies, including Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML, now a part of Databricks, OctoML, Tabnine, and Together AI, to accelerate and optimize LLM inference.
Those innovations have been integrated into the open-source NVIDIA TensorRT-LLM software, set for release in the coming weeks. TensorRT-LLM consists of the TensorRT deep learning compiler and includes optimized kernels, pre- and post-processing steps, and multi-GPU/multi-node communication primitives for groundbreaking performance on NVIDIA GPUs. It enables developers to experiment with new LLMs, offering peak performance and quick customization capabilities, without requiring deep knowledge of C++ or NVIDIA CUDA.
TensorRT-LLM improves ease of use and extensibility through an open-source modular Python API for defining, optimizing, and executing new architectures and enhancements as LLMs evolve, and can be customized easily.
For example, MosaicML has added specific features that it needs on top of TensorRT-LLM seamlessly and integrated them into their inference serving. Naveen Rao, vice president of engineering at Databricks notes that “it has been an absolute breeze.”
“TensorRT-LLM is easy to use, feature-packed with streaming of tokens, in-flight batching, paged-attention, quantization, and more, and is efficient,” Rao said. “It delivers state-of-the-art performance for LLM serving using NVIDIA GPUs and allows us to pass on the cost savings to our customers.”
Performance comparison
Summarizing articles is just one of the many applications of LLMs. The following benchmarks show performance improvements brought by TensorRT-LLM on the latest NVIDIA Hopper architecture.
The following figures reflect article summarization using an NVIDIA A100 and NVIDIA H100 with CNN/Daily Mail, a well-known dataset for evaluating summarization performance.
In Figure 1, H100 alone is 4x faster than A100. Adding TensorRT-LLM and its benefits, including in-flight batching, result in an 8X total increase to deliver the highest throughput.
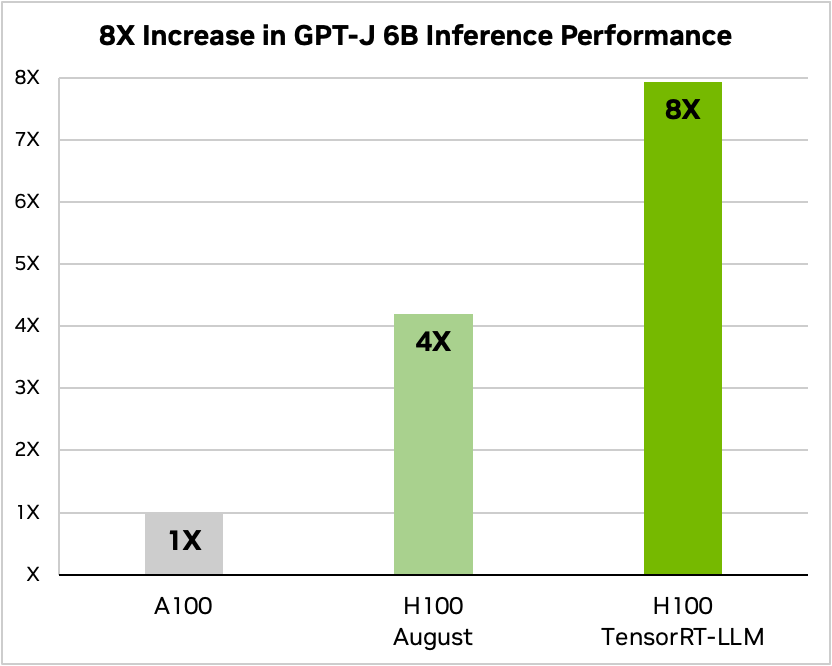 Figure 1. GPT-J-6B A100 compared to H100 with and without TensorRT-LLM
Figure 1. GPT-J-6B A100 compared to H100 with and without TensorRT-LLM
Text summarization, variable I/O length, CNN / DailyMail dataset | A100 FP16 PyTorch eager mode | H100 FP8 | H100 FP8, in-flight batching, TensorRT-LLM
On Llama 2—a popular language model released recently by Meta and used widely by organizations looking to incorporate generative AI—TensorRT-LLM can accelerate inference performance by 4.6x compared to A100 GPUs.
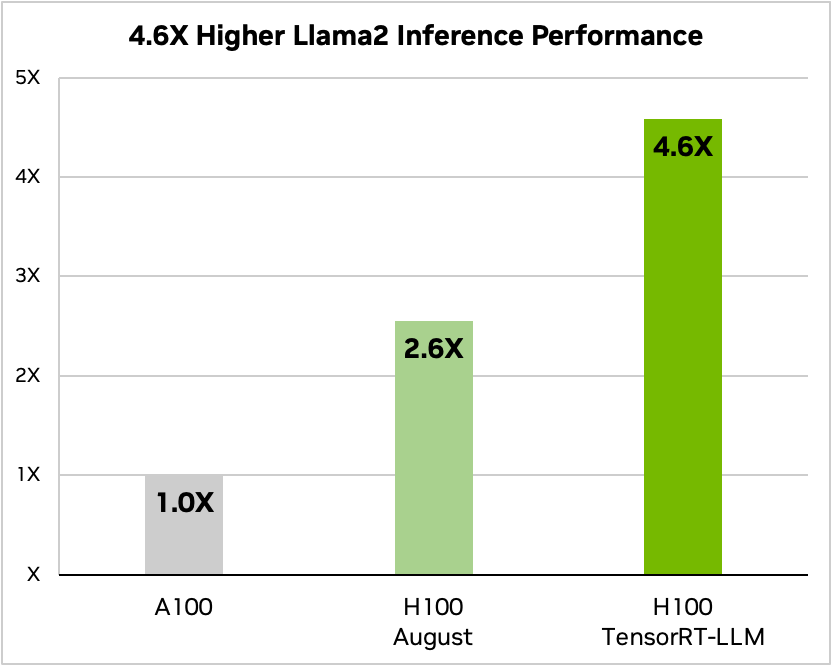 Figure 2. Llama 2 70B, A100 compared to H100 with and without TensorRT-LLM
Figure 2. Llama 2 70B, A100 compared to H100 with and without TensorRT-LLM
Text summarization, variable I/O length, CNN / DailyMail dataset | A100 FP16 PyTorch eager mode| H100 FP8 | H100 FP8, in-flight batching, TensorRT-LLM
LLM ecosystem explosion
The ecosystem is innovating rapidly, developing new and diverse model architectures. Larger models unleash new capabilities and use cases. Some of the largest, most advanced language models, like Meta’s 70-billion-parameter Llama 2, require multiple GPUs working in concert to deliver responses in real time. Previously, developers looking to achieve the best performance for LLM inference had to rewrite and manually split the AI model into fragments and coordinate execution across GPUs.
TensorRT-LLM uses tensor parallelism, a type of model parallelism in which individual weight matrices are split across devices. This enables efficient inference at scale–with each model running in parallel across multiple GPUs connected through NVLink and across multiple servers–without developer intervention or model changes.
As new models and model architectures are introduced, developers can optimize their models with the latest NVIDIA AI kernels available open source in TensorRT-LLM. The supported kernel fusions include cutting-edge implementations of FlashAttention and masked multi-head attention for the context and generation phases of GPT model execution, along with many others.
Additionally, TensorRT-LLM includes fully optimized, ready-to-run versions of many LLMs widely used in production today. This includes Meta Llama 2, OpenAI GPT-2 and GPT-3, Falcon, Mosaic MPT, BLOOM, and a dozen others, all of which can be implemented with the simple-to-use TensorRT-LLM Python API.
These capabilities help developers create customized LLMs faster and more accurately to meet the needs of virtually any industry.
In-flight batching
Today’s large language models are extremely versatile. A single model can be used simultaneously for a variety of tasks that look very different from one another. From a simple question-and-answer response in a chatbot to the summarization of a document or the generation of a long chunk of code, workloads are highly dynamic, with outputs varying in size by several orders of magnitude.
This versatility can make it difficult to batch requests and execute them in parallel effectively—a common optimization for serving neural networks—which could result in some requests finishing much earlier than others.
To manage these dynamic loads, TensorRT-LLM includes an optimized scheduling technique called in-flight batching. This takes advantage of the fact that the overall text generation process for an LLM can be broken down into multiple iterations of execution on the model.
With in-flight batching, rather than waiting for the whole batch to finish before moving on to the next set of requests, the TensorRT-LLM runtime immediately evicts finished sequences from the batch. It then begins executing new requests while other requests are still in flight. In-flight batching and the additional kernel-level optimizations enable improved GPU usage and minimally double the throughput on a benchmark of real-world LLM requests on H100 Tensor Core GPUs, helping to minimize TCO.
H100 Transformer Engine with FP8
LLMs contain billions of model weights and activations, typically trained and represented with 16-bit floating point (FP16 or BF16) values where each value occupies 16 bits of memory. At inference time, however, most models can be effectively represented at lower precision, like 8-bit or even 4-bit integers (INT8 or INT4), using modern quantization techniques.
Quantization is the process of reducing the precision of a model’s weights and activations without sacrificing accuracy. Using lower precision means that each parameter is smaller, and the model takes up less space in GPU memory. This enables inference on larger models with the same hardware while spending less time on memory operations during execution.
NVIDIA H100 GPUs with TensorRT-LLM give users the ability to convert their model weights into a new FP8 format easily and compile their models to take advantage of optimized FP8 kernels automatically. This is made possible through Hopper Transformer Engine technology and done without having to change any model code.
The FP8 data format introduced by the H100 enables developers to quantize their models and radically reduce memory consumption without degrading model accuracy. FP8 quantization retains higher accuracy compared to other data formats like INT8 or INT4 while achieving the fastest performance and offering the simplest implementation.
Summary
LLMs are advancing rapidly. Diverse model architectures are being developed daily and contribute to a growing ecosystem. In turn, larger models unleash new capabilities and use cases, driving adoption across all industries.
LLM inference is reshaping the data center. Higher performance with increased accuracy yields better TCO for enterprises. Model innovations enable better customer experiences, translating into higher revenue and earnings.
When planning inference deployment projects, there are still many other considerations to achieve peak performance using state-of-the-art LLMs. Optimization rarely happens automatically. Users must consider fine-tuning factors such as parallelism, end-to-end pipelines, and advanced scheduling techniques. And they require a computing platform that can handle mixed precision without diminishing accuracy.
TensorRT-LLM comprises TensorRT’s Deep Learning Compiler, optimized kernels, pre- and post-processing, and multi-GPU/multi-node communication in a simple, open-source Python API for defining, optimizing, and executing LLMs for inference in production.
Get started with TensorRT-LLM
NVIDIA TensorRT-LLM is now available in early access and soon will be integrated into the NVIDIA NeMo framework—part of NVIDIA AI Enterprise, an enterprise-grade AI software platform with security, stability, manageability, and support. Developers and researchers will be able to access TensorRT-LLM through the NeMo framework on NGC or through the source repository on GitHub.
Note that you must be registered in the NVIDIA Developer Program to apply for the early access release. You must also be logged in using your organization’s email address. We cannot accept applications from accounts using Gmail, Yahoo, QQ, or other personal email accounts.
To participate, fill out the short application form and provide details about your use case.
Source:: NVIDIA