
Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming…
Heterogeneous Memory Management (HMM) is a CUDA memory management feature that extends the simplicity and productivity of the CUDA Unified Memory programming model to include system allocated memory on systems with PCIe-connected NVIDIA GPUs. System allocated memory refers to memory that is ultimately allocated by the operating system; for example, through malloc, mmap, the C++ new operator (which of course uses the preceding mechanisms), or related system routines that set up CPU-accessible memory for the application.
Previously, on PCIe-based machines, system allocated memory was not directly accessible by the GPU. The GPU could only access memory that came from special allocators such as cudaMalloc or cudaMallocManaged.
With HMM enabled, all application threads (GPU or CPU) can directly access all of the application’s system allocated memory. As with Unified Memory (which can be thought of as a subset of, or precursor to HMM), there is no need to manually copy system allocated memory between processors. This is because it is automatically placed on the CPU or GPU, based on processor usage.
Within the CUDA driver stack, CPU and GPU page faults are typically used to discover where the memory should be placed. Again, this automatic placement already happens with Unified Memory—HMM simply extends the behavior to cover system allocated memory as well as cudaMallocManaged memory.
This new ability to directly read or write to the full application memory address space will significantly improve programmer productivity for all programming models built on top of CUDA: CUDA C++, Fortran, standard parallelism in Python, ISO C++, ISO Fortran, OpenACC, OpenMP, and many others.
In fact, as the upcoming examples demonstrate, HMM simplifies GPU programming to the point that GPU programming is nearly as accessible as CPU programming. Some highlights:
- Explicit memory management is not required for functionality when writing a GPU program; therefore, an initial “first draft” program can be small and simple. Explicit memory management (for performance tuning) can be deferred to a later phase of development.
- GPU programming is now practical for programming languages that do not distinguish between CPU and GPU memory.
- Large applications can be GPU-accelerated without requiring large memory management refactoring, or changes to third-party libraries (for which source code is not always available).
As an aside, new hardware platforms such as NVIDIA Grace Hopper natively support the Unified Memory programming model through hardware-based memory coherence among all CPUs and GPUs. For such systems, HMM is not required, and in fact, HMM is automatically disabled there. One way to think about this is to observe that HMM is effectively a software-based way of providing the same programming model as an NVIDIA Grace Hopper Superchip.
To learn more about CUDA Unified Memory, see the resources section at the end of this post.
Unified Memory before HMM
The original CUDA Unified Memory feature introduced in 2013 enables you to accelerate a CPU program with only a few changes, as shown below:
Before HMM
CPU only
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, cmp);
use_data(data);
free(data);
}
After HMM
CUDA Unified Memory (2013)
void sortfile(FILE* fp, int N) {
char* data;
cudaMallocManaged(&data, N);
fread(data, 1, N, fp);
qsort<<<...>>>(data, N, 1, cmp);
cudaDeviceSynchronize();
use_data(data);
cudaFree(data);
}
This programming model is simple, clear, and powerful. Over the past 10 years, this approach has enabled countless applications to easily benefit from GPU acceleration. And yet, there is still room for improvement: note the need for a special allocator: cudaMallocManaged, and the corresponding cudaFree.
What if we could go even further, and get rid of those? That’s exactly what HMM does.
Unified Memory after HMM
On systems with HMM (detailed below), continue using malloc and free:
Before HMM
CPU only
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort(data, N, 1, cmp);
use_data(data);
free(data);
}
After HMM
CUDA Unified Memory + HMM (2023)
void sortfile(FILE* fp, int N) {
char* data;
data = (char*)malloc(N);
fread(data, 1, N, fp);
qsort<<<...>>>(data, N, 1, cmp);
cudaDeviceSynchronize();
use_data(data);
free(data)
}
With HMM, the memory management is now identical between the two.
System allocated memory and CUDA allocators
GPU applications using CUDA memory allocators work “as is” on systems with HMM. The main difference in these systems is that system allocation APIs like malloc, C++ new, or mmap now create allocations that may be accessed from GPU threads, without having to call any CUDA APIs to tell CUDA about the existence of these allocations. Table 1 captures the differences between the most common CUDA memory allocators on systems with HMM:
Memory allocators on systems with HMMPlacementMigratableAccessible from:CPUGPURDMASystem allocatedmalloc, mmap, …
First-touch
GPU or CPUYYYYCUDA managedcudaMallocManagedYYY NCUDA device-onlycudaMalloc, …GPUNNY Y CUDA host-pinnedcudaMallocHost, …CPUNYY Y Table 1. Overview of system and CUDA memory allocators on systems with HMM
In general, selecting the allocator that better expresses the application intent may enable CUDA to deliver better performance. With HMM, these choices become performance optimizations that do not need to be done upfront, before accessing the memory from the GPU for the first time. HMM enables developers to focus on parallelizing algorithms first, and performing memory allocator-related optimizations later, when their overhead improves performance.
Seamless GPU acceleration for C++, Fortran, and Python
HMM makes it significantly easier to program NVIDIA GPUs with standardized and portable programming languages like Python that do not distinguish between CPU and GPU memory and assume all threads may access all memory, as well as programming languages described by international standards like ISO Fortran and ISO C++.
These languages provide concurrency and parallelism facilities that enable implementations to automatically dispatch computations to GPUs and other devices. For example, since C++ 2017, the standard library algorithms from the header accept execution policies that enable implementations to run them in parallel.
Sorting a file in place from the GPU
For example, before HMM, sorting a file larger than CPU memory in-place was complicated, requiring sorting smaller parts of the file first, and merging them into a fully-sorted file afterwards. With HMM, the application may map the file on disk into memory using mmap, and read and write to it directly from the GPU. For more details, see the HMM sample code file_before.cpp and file_after.cpp on GitHub.
Before HMM
Dynamic Allocation
void sortfile(FILE* fp, int N) {
std::vector buffer;
buffer.resize(N);
fread(buffer.data(), 1, N, fp);
// std::sort runs on the GPU:
std::sort(std::execution::par,
buffer.begin(), buffer.end(),
std::greater{});
use_data(std::span{buffer});
}
After HMM
CUDA Unified Memory + HMM (2023)
void sortfile(int fd, int N) {
auto buffer = (char*)mmap(NULL, N,
PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// std::sort runs on the GPU:
std::sort(std::execution::par,
buffer, buffer + N,
std::greater{});
use_data(std::span{buffer});
}
The NVIDIA C++ Compiler (NVC++) implementation of the parallel std::sort algorithm sorts the file on the GPU when using the -stdpar=gpu option. There are many restrictions on the use of this option, as detailed in the HPC SDK documentation.
- Before HMM: GPU may only access dynamically allocated memory on the heap within code compiled by NVC++. That is, automatic variables on CPU thread stacks, global variables, and memory-mapped files are not accessible from the GPU (see examples below).
- After HMM: GPU may access all system allocated memory, including data dynamically allocated on the heap in CPU code compiled by other compilers and third-party libraries, automatic variables on CPU thread stacks, global variables in CPU memory, memory-mapped files, and so on
Atomic memory operations and synchronization primitives
HMM supports all memory operations, which includes atomic memory operations. That is, programmers may use atomic memory operations to synchronize GPU and CPU threads with flags. While certain parts of the C++ std::atomic APIs use system calls that are not available on the GPU yet, such as std::atomic::wait and std::atomic::notify_all/_one APIs, most of the C++ concurrency primitive APIs are available and readily useful to perform message passing between GPU and CPU threads.
For more information, see the documentation of HPC SDK C++ Parallel Algorithms: Interoperability with the C++ Standard Library) and atomic_flag.cpp HMM sample code on GitHub. You can extend this set using CUDA C++. See the ticket_lock.cpp HMM sample code on GitHub for more details.
Before HMM
CPU←→GPU message passing
void main() {
// Variables allocated with cudaMallocManaged
std::atomic* flag;
int* msg;
cudaMallocManaged(&flag, sizeof(std::atomic));
cudaMallocManaged(&msg, sizeof(int));
new (flag) std::atomic(0);
*msg = 0;
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread writes message…
*msg = 42; // all accesses via ptrs
// …and signals completion…
flag->store(1); // all accesses via ptrs
});
});
// CPU thread waits on GPU thread
while (flag->load() == 0); // all accesses via ptrs
// …and reads the message:
std::cout << *msg << std::endl;
// …the GPU kernel and thread
// may still be running here…
}
After HMM
CPU←→GPU message passing
void main() {
// Variables on CPU thread stack:
std::atomic flag = 0; // Atomic
int msg = 0; // Message
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread writes message…
msg = 42;
// …and signals completion…
flag.store(1);
});
});
// CPU thread waits on GPU thread
while (flag.load() == 0);
// …and reads the message:
std::cout << msg << std::endl;
// …the GPU kernel and thread
// may still be running here…
}
Before HMM
CPU←→GPU locks
void main() {
// Variables allocated with cudaMallocManaged
ticket_lock* lock; // Lock
int* msg; // Message
cudaMallocManaged(&lock, sizeof(ticket_lock));
cudaMallocManaged(&msg, sizeof(int));
new (lock) ticket_lock();
*msg = 0;
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread takes lock…
auto g = lock->guard();
// … and sets message (no atomics)
msg += 1;
}); // GPU thread releases lock here
});
{ // Concurrently with GPU thread
// … CPU thread takes lock…
auto g = lock->guard();
// … and sets message (no atomics)
msg += 1;
} // CPU thread releases lock here
t.join(); // Wait on GPU kernel completion
std::cout << msg << std::endl;
}
After HMM
CPU←→GPU locks
void main() {
// Variables on CPU thread stack:
ticket_lock lock; // Lock
int msg = 0; // Message
// Start a different CPU thread…
auto t = std::jthread([&] {
// … that launches and waits
// on a GPU kernel completing
std::for_each_n(
std::execution::par,
&msg, 1, [&](int& msg) {
// GPU thread takes lock…
auto g = lock.guard();
// … and sets message (no atomics)
msg += 1;
}); // GPU thread releases lock here
});
{ // Concurrently with GPU thread
// … CPU thread takes lock…
auto g = lock.guard();
// … and sets message (no atomics)
msg += 1;
} // CPU thread releases lock here
t.join(); // Wait on GPU kernel completion
std::cout << msg << std::endl;
}
Accelerate complex HPC workloads with HMM
Research groups working on large and long-lived HPC applications have yearned for years for more productive and portable programming models for heterogeneous platforms. m-AIA is a multi-physics solver spanning almost 300,000 lines of code developed at the Institute of Aerodynamics at RWTH Aachen, Germany. See Accelerating a C++ CFD Code with OpenACC for more information. Instead of using OpenACC for the initial prototype, it is now partially accelerated on GPUs using the ISO C++ programming model described above, which was not available when the prototype work was done.
HMM enabled our team to accelerate new m-AIA workloads that interface with GPU-agnostic third-party libraries such as FFTW and pnetcdf, which are used for initial conditions and I/O and are oblivious to the GPU directly accessing the same memory.
Leverage memory-mapped I/O for fast development
One of the interesting features that HMM provides is memory-mapped file I/O directly from the GPU. It enables developers to directly read files from supported storage or /disk without staging them in system memory and without copying the data to the high bandwidth GPU memory. This also enables application developers to easily process input data larger than the available physical system memory, without constructing an iterative data ingestion and computation workflow.
To demonstrate this functionality, our team wrote a sample application that builds a histogram of hourly total precipitation for every day of the year from the ERA5 reanalysis dataset. For more details, see The ERA5 global reanalysis.
The ERA5 dataset consists of hourly estimates of several atmospheric variables. In the dataset, total precipitation data for each month is stored in a separate file. We used 40 years of total precipitation data from 1981–2020, which sum to 480 input files aggregating to ~1.3 TB total input data size. See Figure 1 for example results.
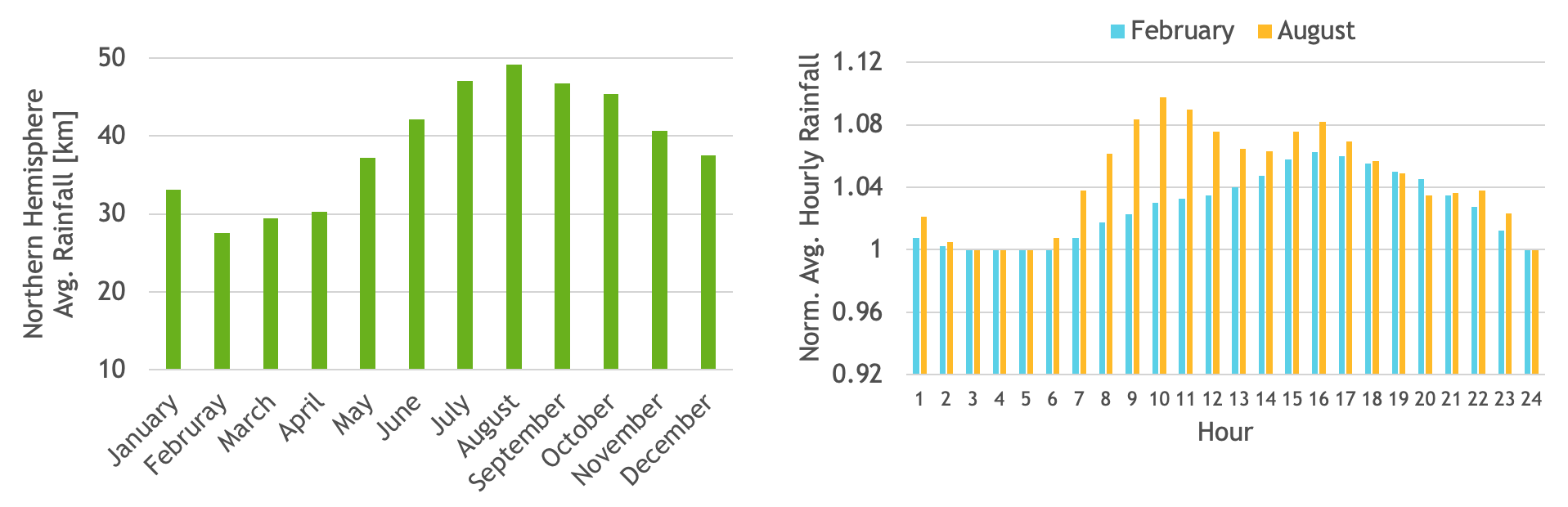 Figure 1. Average monthly rainfall over the northern hemisphere (left) and normalized average hourly rainfall for the months of February and August (right)
Figure 1. Average monthly rainfall over the northern hemisphere (left) and normalized average hourly rainfall for the months of February and August (right)
Using the Unix mmap API, input files can be mapped to a contiguous virtual address space. With HMM, this virtual address can be passed as input to a CUDA kernel which can then directly access the values to build a histogram of total precipitation for each hour for all the days in a year.
The resulting histogram will reside in GPU memory and can be used to easily compute interesting statistics such as average monthly precipitation over the northern hemisphere. As an example, we also computed average hourly precipitation for the months of February and August. To see the code for this application, visit HMM_sample_code on GitHub.
Before HMM
Batch and pipeline memory transfers
size_t chunk_sz = 70_gb;
std::vector buffer(chunk_sz);
for (fp : files)
for (size_t off = 0; off < N; off += chunk_sz) {
fread(buffer.data(), 1, chunk_sz, fp);
cudeMemcpy(dev, buffer.data(), chunk_sz, H2D);
histogram<<<...>>>(dev, N, out);
cudaDeviceSynchronize();
}After HMM
Memory map and transfer on demand
void* buffer = mmap(NULL, alloc_size,
PROT_NONE, MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
for (fd : files)
mmap(buffer+file_offset, fileByteSize,
PROT_READ, MAP_PRIVATE|MAP_FIXED, fd, 0);
histogram<<<...>>>(buffer, total_N, out);
cudaDeviceSynchronize();
Enabling and detecting HMM
The CUDA Toolkit and driver will automatically enable HMM whenever it detects that your system can handle it. The requirements are documented in detail in the CUDA 12.2 Release Notes: General CUDA. You’ll need:
- NVIDIA CUDA 12.2 with the open-source r535_00 driver or newer. See NVIDIA Open GPU Kernel Modules Installation Documentation for details.
- A sufficiently recent Linux kernel: 6.1.24+, 6.2.11+, or 6.3+.
- A GPU with one of the following supported architectures: NVIDIA Turing, NVIDIA Ampere, NVIDIA Ada Lovelace, NVIDIA Hopper, or newer.
- A 64-bit x86 CPU.
Query the Addressing Mode property to verify that HMM is enabled:
$ nvidia-smi -q | grep Addressing
Addressing Mode : HMM
To detect systems in which GPUs may access system allocated memory, query the cudaDevAttrPageableMemoryAccess.
In addition, systems such as the NVIDIA Grace Hopper Superchip support ATS, which has similar behavior to HMM. In fact, the programming model for HMM and ATS systems is the same, so merely checking for cudaDevAttrPageableMemoryAccess suffices for most programs.
However, for performance tuning and other advanced programming, it is possible to discern between HMM and ATS by also querying for cudaDevAttrPageableMemoryAccessUsesHostPageTables. Table 2 shows how to interpret the results.
AttributeHMMATScudaDevAttrPageableMemoryAccess11cudaDevAttrPageableMemoryAccessUsesHostPageTables01Table 2. CUDA device attributes to query HMM and ATS support
For portable applications that are only interested in querying whether the programming model exposed by HMM or ATS is available, querying the ‘pageable memory access’ property usually suffices.
Unified Memory performance hints
There are no changes to the semantics of pre-existing Unified Memory performance hints. For applications that are already using CUDA Unified Memory on hardware-coherent systems like NVIDIA Grace Hopper, the main change is that HMM enables them to run “as is” on more systems within the limitations mentioned above.
The pre-existing Unified Memory hints also work with system allocated memory on HMM systems:
cudaMemPrefetchAsync(* ptr, size_t nbytes, int device):
asynchronously prefetches memory to a GPU (GPU device ID) or CPU (cudaCpuDeviceId).
- A preferred location for the memory:
cudaMemAdviseSetPreferredLocation, or - A device that will access the memory:
cudaMemAdviseSetAccessedBy, or - A device that will be mostly reading the memory that will be infrequently modified:
cudaMemAdviseSetReadMostly.
A little more advanced: there is a new CUDA 12.2 API, cudaMemAdvise_v2, that enables applications to choose which NUMA node a given memory range should prefer. This comes into play when HMM places the memory contents on the CPU side.
As always, memory management hints may either improve or degrade performance. Behavior is application and workload dependent, but none of the hints impacts the correctness of the application.
Limitations of HMM in CUDA 12.2
The initial HMM implementation in CUDA 12.2 delivers new features without regressing the performance of any pre-existing applications. The limitations of HMM in CUDA 12.2 are documented in detail in the CUDA 12.2 Release Notes: General CUDA. The main limitations are:
- HMM is only available for x86_64, and other CPU architectures are not yet supported.
- HMM on HugeTLB allocations is not supported.
- GPU atomic operations on file-backed memory and HugeTLBfs memory are not supported.
- fork(2) without a following exec(3) is not fully supported.
- Page migrations are handled in chunks of 4 KB-page size.
Stay tuned for future CUDA driver updates that will address HMM limitations and improve performance.
Summary
HMM simplifies the programming model by removing the need for explicit memory management for GPU programs that run on common PCIe-based (x86, typically) computers. Programmers can simply use malloc, C++ new, and mmap calls directly, just as they already do for CPU programming.
HMM further boosts programmer productivity by enabling a wide variety of standard programming language features to be safely used within CUDA programs. There is no need to worry about accidentally exposing system allocated memory to a CUDA kernel.
HMM enables a seamless transition to and from the new NVIDIA Grace Hopper Superchip, and similar machines. On PCIe-based machines, HMM provides the same simplified programming model as that used on the NVIDIA Grace Hopper Superchip.
Unified Memory resources
To learn more about CUDA Unified Memory, the following blog posts will help bring you up to date. You can also join the conversation at the NVIDIA Developer Forum for CUDA.
- An Easy Introduction to CUDA C and C++ | NVIDIA Technical Blog (2012)
- Unified Memory in CUDA 6 | NVIDIA Technical Blog (2013)
- An Even Easier Introduction to CUDA | NVIDIA Technical Blog (2017)
- Unified Memory for CUDA Beginners | NVIDIA Technical Blog (2017)
Source:: NVIDIA