
NVIDIA Jetson Orin is the best-in-class embedded AI platform. The Jetson Orin SoC module has the NVIDIA Ampere architecture GPU at its core but there is a lot…
NVIDIA Jetson Orin is the best-in-class embedded AI platform. The Jetson Orin SoC module has the NVIDIA Ampere architecture GPU at its core but there is a lot more compute on the SoC:
- A dedicated deep learning inference engine in the Deep Learning Accelerator (DLA) for deep learning workloads
- The Programmable Vision Accelerator (PVA) engine for image processing and computer vision algorithms
- The Multi-Standard Video Encoder (NVENC) and Multi-Standard Video Decoder (NVDEC)
The NVIDIA Orin SoC is powerful, with 275 peak AI TOPs, making it the best embedded and automotive AI platform. Did you know that almost 40% of these AI TOPs come from the two DLAs on NVIDIA Orin? While NVIDIA Ampere GPUs have the best-in-class throughput, the second-generation DLA has the best-in-class power efficiency. As applications of AI have rapidly grown in recent years, so has the demand for more efficient computing. This is especially true on the embedded side where power efficiency is always a key KPI.
That’s where DLA comes in. DLA is designed specifically for deep learning inference and can perform compute-intensive deep learning operations like convolutions much more efficiently than a CPU.
When integrated into an SoC as on Jetson AGX Orin or NVIDIA DRIVE Orin, the combination of GPU and DLA provides a complete solution for your embedded AI applications. In this post, we discuss the Deep Learning Accelerator to help you stop missing out. We cover a couple of case studies in automotive and robotics to demonstrate how DLA enables AI developers to add more functionality and performance to their applications. Finally, we look at how vision AI developers can use the DeepStream SDK to build application pipelines that use DLA and the entire Jetson SoC for optimal performance.
But first, here are some key performance indicators that DLA has a significant impact on.
Key performance indicators
When you are designing your application, you have a few key performance indicators or KPIs to meet. Often it’s a design tradeoff, for example, between max performance and power efficiency, and this requires the development team to carefully analyze and design their application to use the different IPs on the SoC.
If the key KPI for your application is latency, you must pipeline the tasks within your application under a certain latency budget. You can use DLA as an additional accelerator for tasks that are parallel to more compute-intensive tasks running on GPU. The DLA peak performance contributes between 38% and 74% to the NVIDIA Orin total deep learning (DL) performance, depending on the power mode.
Power mode: MAXNPower mode: 50WPower mode: 30WPower mode: 15WGPU sparse INT8 peak DL performance171 TOPs109 TOPs41 TOPs14 TOPs2x DLA sparse INT8 peak performance105 TOPs92 TOPs90 TOPs40 TOPsTotal NVIDIA Orin peak INT8 DL performance275 TOPs200 TOPs131 TOPs54 TOPsPercentage: DLA peak INT8 performance of total NVIDIA Orin peak DL INT8 performance38%46%69%74%Table 1. DLA throughput
The DLA TOPs of the 30 W and 50 W power modes on Jetson AGX Orin 64GB are comparable to the maximum clocks on NVIDIA DRIVE Orin platforms for Automotive.
If power is one of your key KPIs, then you should consider DLA to take advantage of its power efficiency. DLA performance per watt is on average 3–5x more compared to the GPU, depending on the power mode and the workload. The following charts show performance per watt for three models representing common use cases.
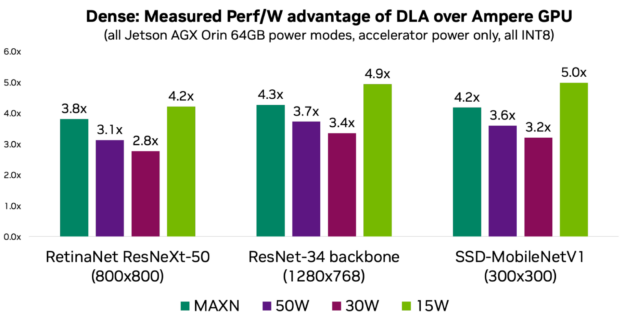 Figure 1. DLA power efficiency
Figure 1. DLA power efficiency
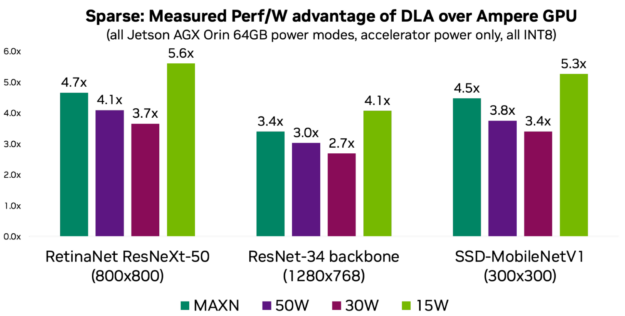 Figure 2. Structured Sparsity and performance per watt advantage
Figure 2. Structured Sparsity and performance per watt advantage
Put differently, without DLA’s power efficiency, it would not be possible to achieve up to 275 peak DL TOPs on NVIDIA Orin at a given platform power budget. For more information and measurements for more models, see the DLA-SW GitHub repo.
Here are some case studies within NVIDIA on how we used the AI compute offered by DLA: Automotive and Robotics
Case study: Automotive
NVIDIA DRIVE AV is the end-to-end autonomous driving solution stack for automotive OEMs to add autonomous driving and mapping features to their automotive product portfolio. It includes perception, mapping, and planning layers, as well as diverse DNNs trained on high-quality, real-world driving data.
Engineers from the NVIDIA DRIVE AV team work on designing and optimizing the perception, mapping, and planning pipelines by leveraging the entire NVIDIA Orin SoC platform. Given the large number of neural networks and other non-DNN tasks to process in the self-driving stack, they rely on DLA as the dedicated inference engine on the NVIDIA Orin SoC, to run DNN tasks. This is critical because the GPU compute is reserved to process non-DNN tasks. Without DLA compute, the team would not meet their KPIs.
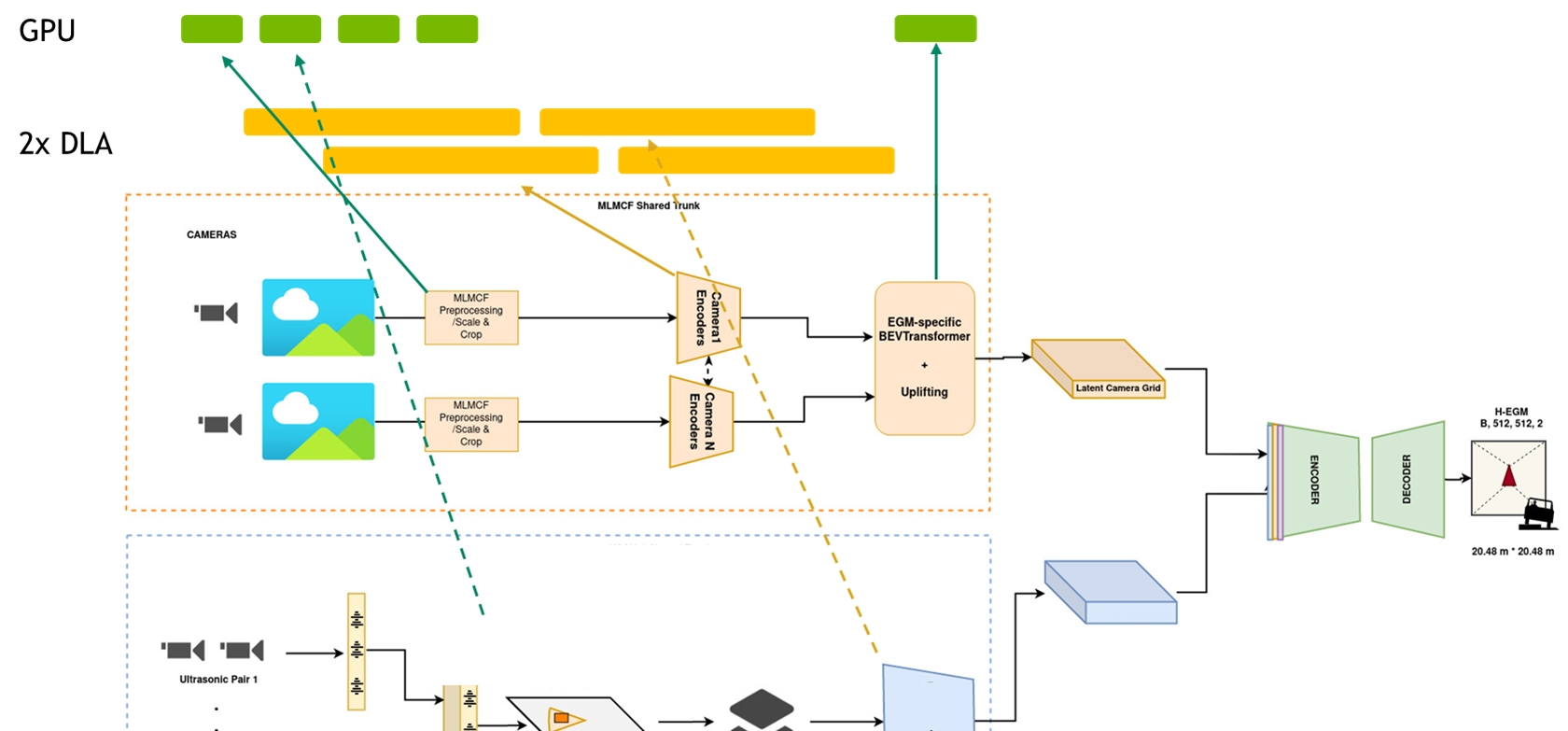 Figure 3. Part of the perception pipeline
Figure 3. Part of the perception pipeline
For more information, see Near-Range Obstacle Perception with Early Grid Fusion.
For instance, for the perception pipeline, they have inputs from eight different camera sensors and the latency of the entire pipeline must be lower than a certain threshold. The perception stack is DNN-heavy and accounts for more than 60% of all the compute.
To meet these KPIs, parallel pipeline tasks are mapped to GPU and DLA, where almost all the DNNs are running on DLAs and non-DNN tasks on the GPU to achieve the overall pipeline latency target. The outputs are then consumed sequentially or in parallel by other DNNs in other pipelines like mapping and planning. You may view the pipelines as a giant graph with tasks running in parallel on GPU and DLA. Using DLA, the team reduced their latency 2.5x.
 Figure 4. Object detection as part of the perception stack
Figure 4. Object detection as part of the perception stack
“Leveraging the entire SoC, especially the dedicated deep learning inference engine in DLA, is enabling us to add significant functionality to our software stack while still meeting latency requirements and KPI targets. This is only possible with DLA,” said Abhishek Bajpayee, engineering manager of the Autonomous Driving team at NVIDIA.
Case study: Robotics
NVIDIA Isaac is a powerful, end-to-end platform for the development, simulation, and deployment of AI-enabled robots used by robotics developers. For mobile robots in particular, the available DL compute, deterministic latencies, and battery endurance are important factors. This is why mapping DL inference to DLA is important.
A team of engineers from the NVIDIA Isaac team have developed a library for proximity segmentation using DNNs. Proximity segmentation can be used to determine whether an obstacle is within a proximity field and to avoid collisions with obstacles during navigation. They implemented the BI3D network on DLA that performs binary depth classification from a stereo camera.
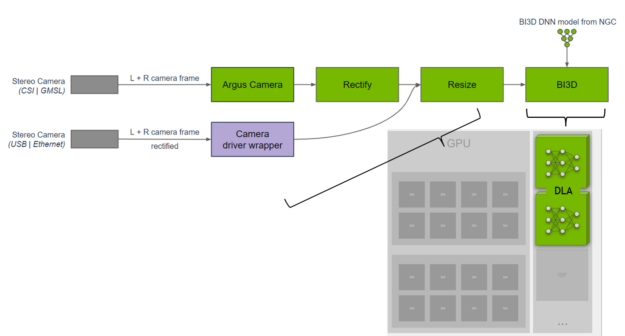 Figure 5. Proximity segmentation pipeline
Figure 5. Proximity segmentation pipeline
Figure 5. Proximity segmentation pipeline NEEDS ALT TEXT
A key KPI is ensuring real-time 30-fps detection from a stereo camera input. The NVIDIA Isaac team distributes the tasks across the SoC and uses DLA for the DNNs, while providing functional safety diversity in hardware and software from what is run on the GPU. For more information, see NVIDIA Isaac ROS Proximity Segmentation.
 Figure 6. Proximity segmentation on a stereo input using BI3D.
Figure 6. Proximity segmentation on a stereo input using BI3D.
“We use TensorRT on DLA for DNN inference to provide hardware diversity from the GPU improving fault tolerance while offloading the GPU for other tasks. DLA delivers ~46 fps on Jetson AGX Orin for BI3D, which consists of three DNNs, providing low 30 ms of latency for our robotics applications,” said Gordon Grigor, vice president of Robotics Platform Software at NVIDIA.
NVIDIA DeepStream for DLA
The quickest way to explore DLA is through the NVIDIA DeepStream SDK, a complete streaming analytics toolkit.
If you are a vision AI developer building AI-powered applications to analyze video and sensor data, the DeepStream SDK enables you to build optimal end-to-end pipelines. For cloud or edge use cases such as retail analytics, parking management, managing logistics, optical inspection, robotics, and sports analytics, DeepStream enables the use of the entire SoC and specifically DLA with little effort.
For instance, you can use the pretrained models from the Model Zoo highlighted in the following table to run on DLA. Running these networks on DLA is as simple as setting a flag. For more information, see Using DLA for inference.
Model archInference resolutionGPU FPSDLA1 + DLA2 FPSGPU + DLA1 + DLA2 FPSPeopleNet-ResNet18960x544x3218128346PeopleNet-ResNet34 (v2.3)960x544x316994263PeopleNet-ResNet34 (v2.5 unpruned)960x544x37946125TrafficCamNet960x544x3251174425DashCamNet960x544x3251172423FaceDetect-IR384x240x314079742381VehicleMakeNet224x224x3243411663600VehicleTypeNet224x224x3178110642845FaceDetect (pruned)736x416x3395268663License Plate Detection640x480x37843881172Table 2. Model zoo network sample and their throughput on DLA
Get started with the Deep Learning Accelerator
Ready to dive in? For more information, see the following resources:
- Jetson DLA tutorial demonstrates a basic DLA workflow to help you in getting started with deploying a DNN to DLA.
- The DLA-SW GitHub repo has a collection of reference networks that you can use to explore running DNNs on your Jetson Orin DLA.
- The samples page has other examples and resources on how to use DLA to get the most out of your Jetson SoC.
- The DLA forum has ideas and feedback from other users.
Source:: NVIDIA