
The latest developments in large language model (LLM) scaling laws have shown that when scaling the number of model parameters, the number of tokens used for…
The latest developments in large language model (LLM) scaling laws have shown that when scaling the number of model parameters, the number of tokens used for training should be scaled at the same rate. The Chinchilla and LLaMA models have validated these empirically derived laws and suggest that previous state-of-the-art models have been under-trained regarding the total number of tokens used during pretraining.
Considering these recent developments, it’s apparent that LLMs need larger datasets, more than ever.
However, despite this need, most software and tools developed to create massive datasets for training LLMs are not publicly released or scalable. This requires LLM developers to build their own tools to curate large language datasets.
To meet this growing need for large datasets, we have developed and released the NeMo Data Curator: a scalable data-curation tool that enables you to curate trillion-token multilingual datasets for pretraining LLMs.
Data Curator is a set of Python modules that use Message-Passing Interface (MPI), Dask, and Redis Cluster to scale the following tasks to thousands of compute cores:
- Data download
- Text extraction
- Text reformatting and cleaning
- Quality filtering
- Exact or fuzzy deduplication
Applying these modules to your datasets helps reduce the burden of combing through unstructured data sources. Through document-level deduplication, you can ensure that models are trained on unique documents, potentially leading to greatly reduced pretraining costs.
In this post, we provide an overview of each module in Data Curator and demonstrate that they offer linear scaling to more than 1000 CPU cores. To validate the data curated, we also show that using documents it processes from Common Crawl for pretraining provides significant downstream task improvement over using raw downloaded documents.
Data-curation pipeline
This tool enables you to download data and extract, clean, deduplicate, and filter documents at scale. Figure 1 shows a typical LLM data-curation pipeline that can be implemented. In the following sections, we briefly describe the implementation of each of these modules available.
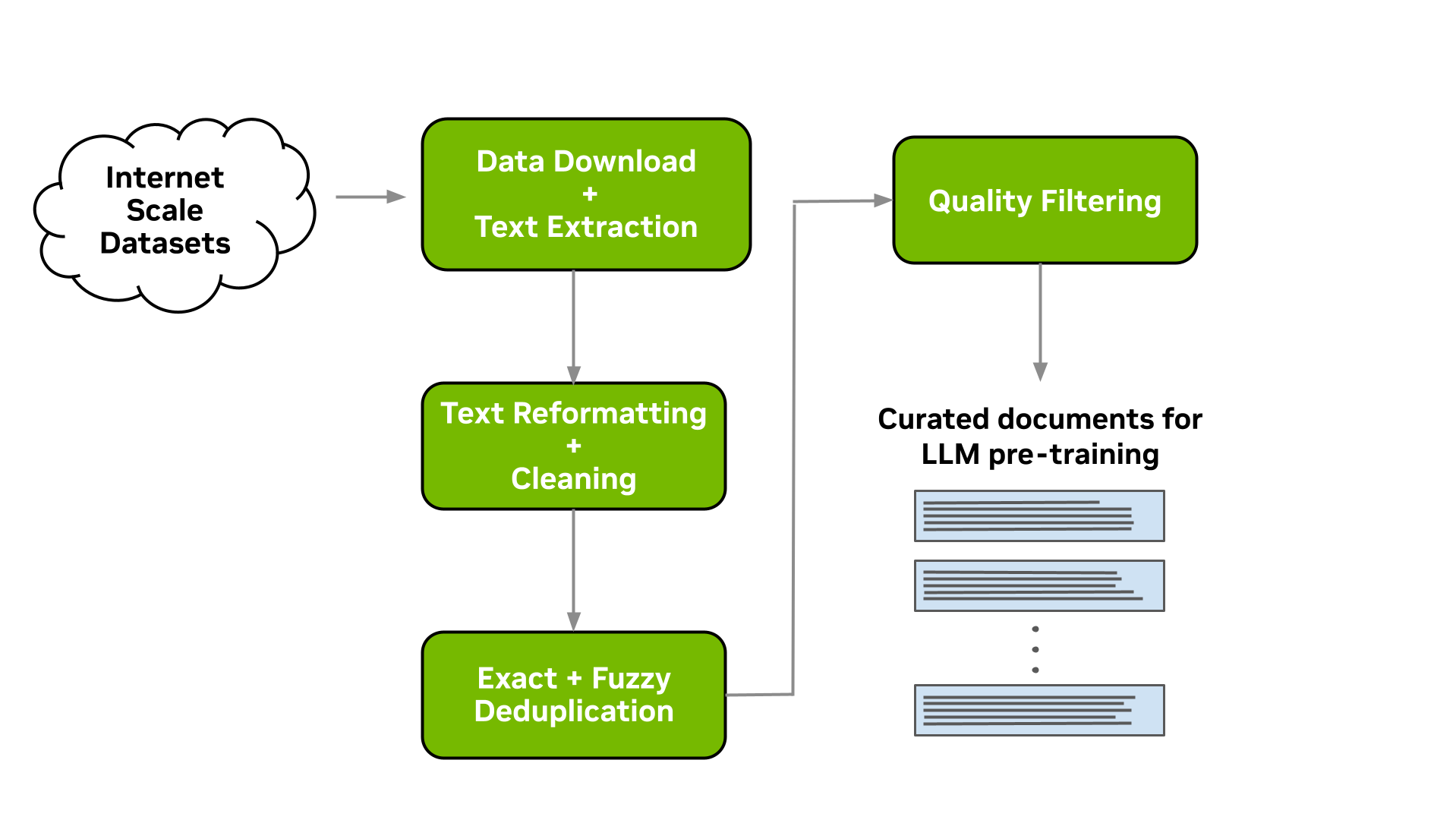 Figure 1. A common LLM data-curation pipeline for datasets like Common Crawl that can be implemented with the modules available within the Data Curator
Figure 1. A common LLM data-curation pipeline for datasets like Common Crawl that can be implemented with the modules available within the Data Curator
Download and text extraction
The starting point for preparing custom pretraining datasets for many LLM practitioners is a list of URLs that point to data files or websites that contain content of interest for LLM pretraining.
Data Curator enables you to download pre-crawled web pages from data repositories such as Common Crawl, Wikidumps, and ArXiv and to extract the relevant text to JSONL files at scale. Data Curator also provides you with the flexibility of supplying your own download and extraction functions to process datasets from a variety of sources. Using a combination of MPI and Python Multiprocessing, thousands of asynchronous download and extraction workers can be launched at runtime across many compute nodes.
Text reformatting and cleaning
Upon downloading and extracting text from documents, a common step is to fix all Unicode-related errors that can be introduced when text data are not properly decoded during extraction. Data Curator uses the Fixes Text For You library (ftfy) to fix all Unicode-related errors. Cleaning also helps to normalize the text, which results in a higher recall when performing document deduplication.
Document-level deduplication
When downloading data from massive web-crawl sources such as Common Crawl, it’s common to encounter both documents that are exact duplicates and documents with high similarity (that is, near duplicates). Pretraining LLMs with repeated documents can lead to poor generalization and a lack of diversity during text generation.
We provide exact and fuzzy deduplication utilities to remove duplicates from text data. The exact deduplication utility computes a 128-bit hash of each document, groups documents by their hashes into buckets, selects one document per bucket, and removes the remaining exact duplicates within the bucket.
The fuzzy-deduplication utility uses a MinHashLSH-based approach where MinHashes are computed for each document, and then documents are grouped using the locality-sensitive property of min-wise hashing. After documents are grouped into buckets, similarities are computed between documents within each bucket to check for potential false positives created during MinHashLSH.
For both deduplication utilities, Data Curator uses a Redis Cluster distributed across compute nodes to implement a distributed dictionary for clustering documents into buckets. The scalable design and gossip protocol implemented by the Redis Cluster enables efficient scaling of deduplication workloads to many compute nodes.
Document-level quality filtering
In addition to containing a significant fraction of duplicate documents, data from web-crawl sources such as Common Crawl often tend to include many documents with informal prose. This includes, for example, many URLs, symbols, boilerplate content, ellipses, or repeating substrings. They can be considered low-quality content from a language-modeling perspective.
While it’s been shown that diverse LLM pretraining datasets lead to improved downstream performance, a significant quantity of low-quality documents can hinder performance. Data Curator provides you with a highly configurable document-filtering utility that enables you to apply custom heuristic filters at scale to your corpora. The tool also includes implementations of language-data filters (both classifier and heuristic-based) that have been shown to improve overall data quality and downstream task performance when applied to web-crawl data.
Scaling to many compute cores
To demonstrate the scaling capabilities of the different modules available within Data Curator, we used them to prepare a small dataset consisting of approximately 40B tokens. This involved running the previously described data-curation pipeline on 5 TB of Common Crawl WARC files.
For each pipeline stage, we fixed the input dataset size while linearly increasing the number of CPU cores used to scale the data curation modules (that is, strong scaling). We then measured the speedup for each module. The measured speedups for the quality-filtering and fuzzy-deduplication modules are shown in Figure 2.
Examining the trends of the measurements, it’s apparent that these modules can reach substantial speedups when increasing the number of CPU cores used for distributing the data curation workloads. Compared to the linear reference (orange curve), we observe that both modules are able to achieve considerable speedup when using up to 1,000 CPUs or more.
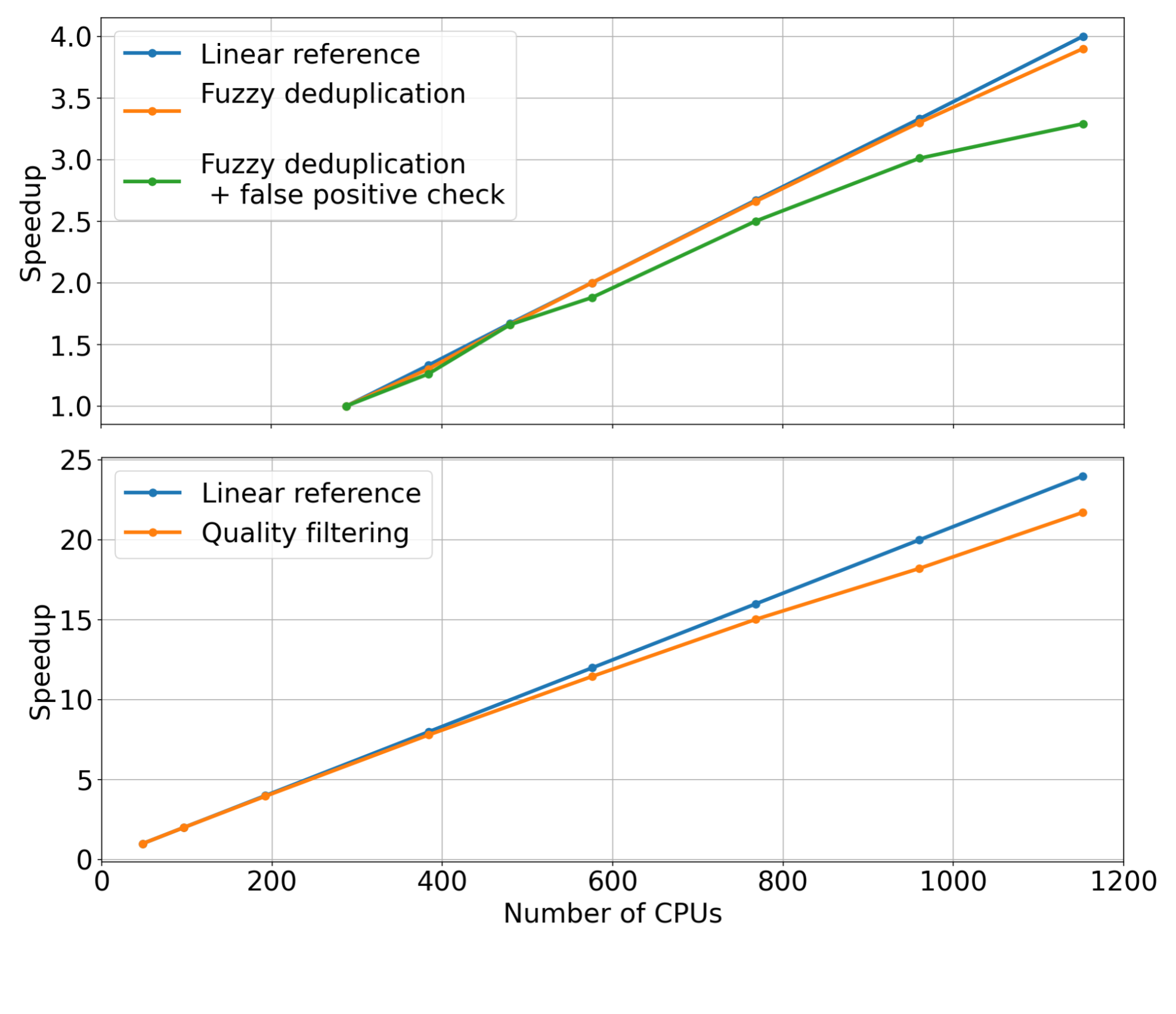 Figure 2. Measured speedup for the fuzzy-deduplication and quality-filtering modules within Data Curator
Figure 2. Measured speedup for the fuzzy-deduplication and quality-filtering modules within Data Curator
Curated pretraining data results in improved model downstream performance
In addition to verifying the scaling of each module, we also performed an ablation study on the data curated from each step of the data-curation pipeline implemented within the tool. Starting from a downloaded Common Crawl snapshot, we trained a 357M parameter GPT model on 78M tokens curated from this snapshot after extraction, cleaning, deduplication, and filtering.
After each pretraining experiment, we evaluated the model across the RACE-High, PiQA, Winogrande, and Hellaswag tasks in a zero-shot setting. Figure 3 shows that the results of our ablation experiments averaged over all four tasks. As the data progresses through the different stages of the pipeline, the average over all four tasks increases significantly, indicating improved data quality.
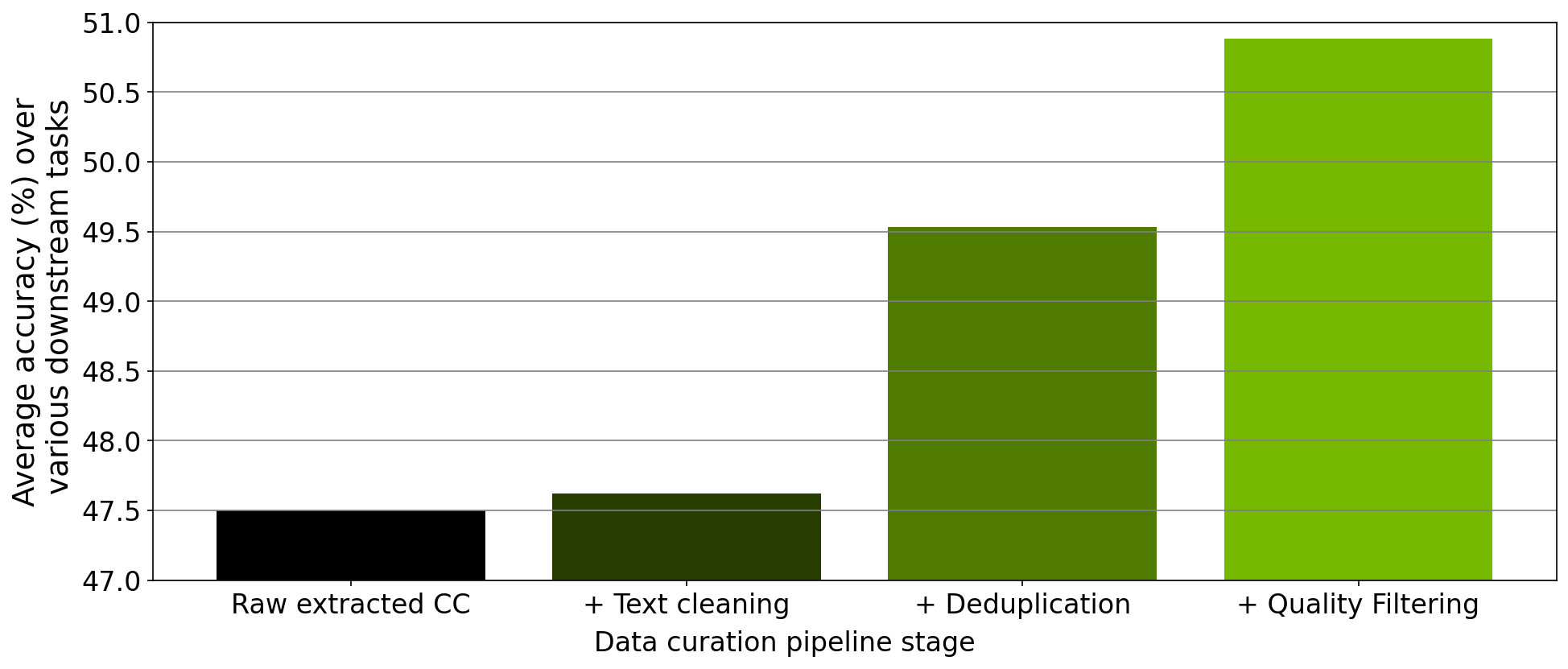 Figure 3. Results of dataset ablation tests for a 357M parameter model trained on data generated from each stage of the processing pipeline within NeMo Data Curator
Figure 3. Results of dataset ablation tests for a 357M parameter model trained on data generated from each stage of the processing pipeline within NeMo Data Curator
Curating a 2T token dataset with NeMo Data Curator
Recently, the NVIDIA NeMo service started providing early-access users with the opportunity to customize an NVIDIA-trained 43B-parameter multilingual large foundation model. To pretrain this foundation model, we prepared a dataset consisting of 2T tokens that included 53 natural languages originating from a variety of diverse domains as well as 37 different programming languages.
Curating this large dataset required applying our data-curation pipeline implemented within Data Curator to a total of 8.7 TB of text data on a CPU cluster of more than 6K CPUs. Pretraining the 43B foundation model on 1.1T of these tokens resulted in a state-of-the-art LLM that’s currently being used by NVIDIA customers for their LLM needs.
Conclusion
To meet the growing demands for curating pretraining datasets for LLMs, we have released Data Curator as part of the NeMo framework. We have demonstrated that the tool curates high-quality data that leads to improved LLM downstream performance. Further, we have shown that each data-curation module available within Data Curator can scale to use thousands of CPU cores. We anticipate that this tool will significantly benefit LLM developers attempting to build pretraining datasets.
Source:: NVIDIA