
The latest release of NVIDIA CUDA Toolkit 12.2 introduces a range of essential new features, modifications to the programming model, and enhanced support for…
The latest release of NVIDIA CUDA Toolkit 12.2 introduces a range of essential new features, modifications to the programming model, and enhanced support for hardware capabilities accelerating CUDA applications.
Now out through general availability from NVIDIA, CUDA Toolkit 12.2 includes many new capabilities, both major and minor.
The following post offers an overview of many of the key capabilities, including:
- NVIDIA Hopper (H100) GPU support.
- Early access to NVIDIA Confidential Computing (CC) for Hopper GPUs.
- Heterogeneous Memory Management (HMM) support.
- A lazy loading default setting.
- Application prioritization with CUDA Multi-Process Service (MPS).
- Enhanced math libraries like cuFFT.
- NVIDIA Nsight Compute and NVIDIA Nsight Systems Developer Tools updates.
As pioneers in accelerated computing, NVIDIA creates solutions for helping solve the world’s toughest computing challenges. Accelerated computing requires full-stack optimization, from chip architecture, systems, and acceleration libraries, to security and network connectivity. It all begins with the CUDA Toolkit.
Watch the following CUDA Toolkit 12.2 YouTube Premiere webinar.
Hopper GPU support
New H100 GPU architecture features are now supported with programming model enhancements for all GPUs, including new PTX instructions and exposure through higher-level C and C++ APIs. An instance of this is Hopper Confidential Computing (see the following section to learn more), which offers early access deployment exclusively available with the Hopper GPU architecture.
Confidential computing for Hopper
The Hopper Confidential Computing early-access software release features a complete software stack targeting a single H100 GPU in passthrough mode, with a single session key for encryption and authentication, and basic use of NVIDIA Developer Tools. User code and data is encrypted and authenticated to the AES-GCM standard.
There is no need for any specific H100 SKUs, drivers, or toolkit downloads. Confidential computing with H100 GPUs requires a CPU that supports virtual machine (VM)–based TEE technology, such as AMD SEV-SNP and Intel TDX.
Read the Protecting Sensitive Data and AI Models with Confidential Computing post, which highlights OEM partners shipping CC-compatible servers.
The following figure compares data flow when using a VM when CC is on and off.
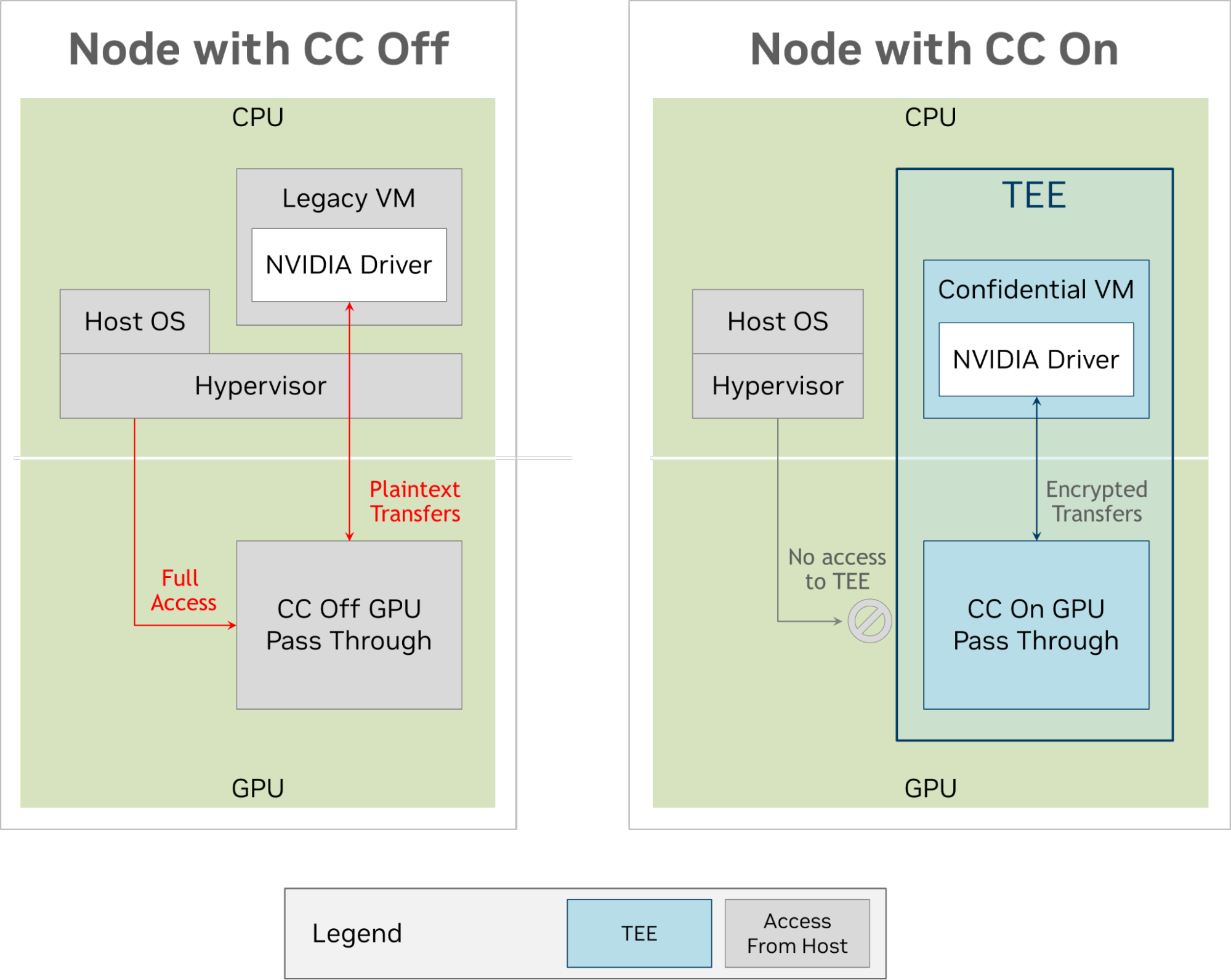 Figure 1. Comparing the flow of instructions and data with confidential computing on and off
Figure 1. Comparing the flow of instructions and data with confidential computing on and off
In Figure 1, a traditional VM is set up on the left. In this mode, the hypervisor assigns an H100 GPU (without CC mode enabled). While the hypervisor is isolated and protected from a malicious VM, the reverse isn’t true: the hypervisor can access the entirety of the VM space as well as direct access to the GPU.
The right side of Figure 1 shows the same environment but on a confidential computing-capable machine. The CPU architecture isolates the now confidential virtual machine (CVM) from the hypervisor such that it can no longer access its memory pages. The H100 is also configured so all external accesses are disabled, except for the path between it and the CVM. The CVM and the H100 have encrypted and signed transfers across the PCIe bus, preventing an attacker with a bus analyzer from making use of, or silently corrupting the data.
While using the early-access release, employ good practices and test only synthetic data and non-proprietary AI models. Security reviews, performance enhancements, and audits aren’t finalized.
Hopper Confidential Computing does not include encryption key rotation at this time. To learn more, see the post What Is Confidential Computing?
Heterogeneous memory management
The release also introduces heterogeneous memory management (HMM). This technology extends unified virtual memory support for seamless sharing of data between host memory and accelerator devices without needing memory allocated by or managed through CUDA. This makes porting applications into CUDA, or working with external frameworks and APIs, significantly easier.
Currently, HMM is supported on Linux only and requires a recent kernel (6.1.24+ or 6.2.11+) along with using the NVIDIA GPU Open Kernel Modules driver.
Some limitations exist with the first release and the following are not yet supported:
- GPU atomic operations on file-backed memory.
- Arm CPUs.
- HugeTLBfs pages on HMM.
- The
fork()system call when attempting to share GPU-accessible memory between parent and child processes.
HMM is also not yet fully optimized and may perform slower than programs using cudaMalloc(), cudaMallocManaged(), or other existing CUDA memory management APIs.
Lazy loading
A feature NVIDIA initially introduced in CUDA 11.7 as an opt-in, lazy loading is now enabled by default on Linux with the R535 driver and beyond. Lazy loading can substantially reduce both the host and device memory footprint by loading only CUDA kernels and library functions as needed. It’s common for complex libraries to contain thousands of different kernels and variants. This results in substantial savings.
Lazy loading is under user control and only the default value is changed. You can disable the feature on Linux by setting the environment variable before launching your application:
CUDA_MODULE_LOADING=EAGER While disabling in Windows is currently unavailable, you can enable it in Windows by setting the environment variable before launch:
CUDA_MODULE_LOADING=LAZYApplication prioritization with CUDA MPS
When running applications with CUDA MPS, each application is often coded as the only application present in the system. As such, its individual stream priorities may assume no system-level contention. In practice, however, users often want to make certain processes a higher or lower priority globally.
To help address this requirement, a coarse-grained per-client priority mapping at runtime for CUDA MPS is now available. This gives multiple processes running under MPS to arbitrate priority at a coarse-grained level between multiple processes without changing the application code.
A new environment variable called CUDA_MPS_CLIENT_PRIORITY accepts two values: NORMAL priority, 0, and BELOW_NORMAL priority, 1.
For example, given two clients, a potential configuration is as follows:
Client 1 EnvironmentClient 2 Environmentexport CUDA_MPS_CLIENT_PRIORITY=0 // NORMALexport CUDA_MPS_CLIENT_PRIORITY=1 // BELOW NORMALTable 1. An example configuration for setting priority variables
It’s worth noting that this doesn’t introduce priority-preemptive scheduling or hard real-time processing into the GPU scheduler. It does provide additional information to the scheduler about which kernels should enqueue when.
cuFFT LTO preview
An early access preview of the cuFFT library containing support for new and enhanced LTO-enabled callback routines is now available for download on Linux and Windows. LTO-enabled callbacks bring callback support for cuFFT on Windows for the first time. On Linux, these new enhanced callbacks offer a significant boost to performance in many callback use cases. You can learn more and download this new update on the cuFFT web page.
In CUDA 12.0, NVIDIA introduced the nvJitLink library for supporting Just-In-Time Link-Time Optimization (JIT LTO) in CUDA applications. This preview builds upon nvJitLink to leverage JIT LTO for LTO-enabled callbacks by enabling runtime fusion of user callback code and library kernel code.
Nsight Developer Tools
Nsight Developer Tools are included in the CUDA Toolkit to help with debugging and performance profiling for CUDA applications. Tools for GPU development are already compatible with the H100 architecture. Support for the NVIDIA Grace CPU architecture is now available in Nsight Systems, for system-wide performance profiling.
Nsight Systems traces and analyzes platform hardware metrics, like CPU and GPU interactions, as well CUDA apps, APIs, and libraries on a unified timeline. Version 2023.2, available in CUDA Toolkit 12.2, introduces Python backtrace sampling.
GPU-accelerated Python is transforming AI workloads. With a periodic sampling of Python code, the Nsight Systems timeline offers a deeper understanding of what algorithms are involved in refactoring toward maximum GPU usage. Python sampling joins multi-node analysis and network metric collection to help optimize computing at the data center scale; learn more about accelerating data center and HPC performance analysis with Nsight Systems.
Nsight Compute provides detailed performance profiling and analysis of CUDA kernels running on a GPU. Version 2023.2 adds a new sorted list of detected performance issues on the summary page, including estimated speedups for correcting the issue. This list guides performance tuning focus and helps users avoid spending time on unnecessary issues.
Another key feature added is performance rule markers at the source-line level on the source page. Previously, issues detected with the built-in performance rules were only displayed on the details page. Now, issues are marked with a warning icon on the source page. Performance metrics identify the location.
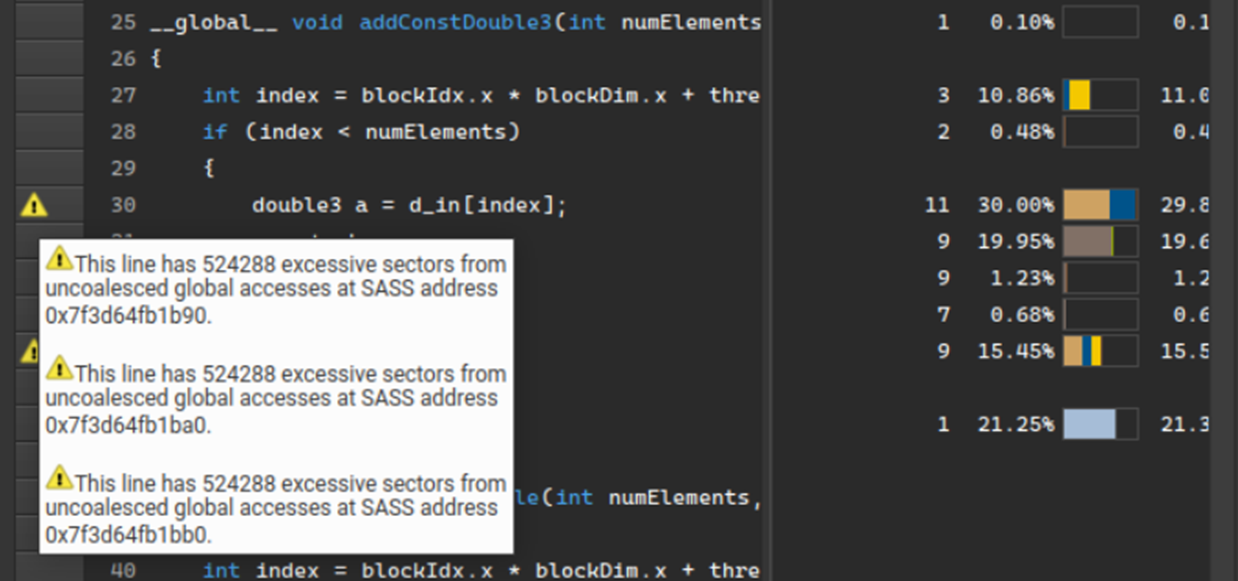 Figure 3. Examine performance issues line-by-line in the source code viewe
Figure 3. Examine performance issues line-by-line in the source code viewe
These new features extend the guided analysis at both the high-level summary view and low-level source view, further improving Nsight Compute performance profiling and analysis capabilities.
CUDA Toolkit 12.2 also equips you with the latest debugging tools. These include:
- NVIDIA Compute Sanitizer for functional correctness checking.
- CUDA-GDB for command-line CPU and GPU debugging.
- NVIDIA Nsight Visual Studio Code Edition for IDE-integrated CUDA debugging.
Learn about how to debug CUDA code with Compute Sanitizer.
Summary
The latest CUDA Toolkit release introduces new features essential to boosting CUDA applications that create the foundation for accelerated computing applications. From chip architecture, NVIDIA DGX Cloud and NVIDIA DGX SuperPOD platforms, AI Enterprise software, and libraries, to security and accelerated network connectivity, the CUDA Toolkit offers incomparable full-stack optimization.
For more information, see the following:
- NVIDIA CUDA Toolkit
- CUDA Toolkit 12.2 Release Notes
- NVIDIA Hopper architecture
- CUDA Compatibility
- NVIDIA Releases Open-Source GPU Kernel Modules
- GPU-Accelerated Libraries
- NVIDIA Nsight Compute and NVIDIA Nsight Systems
Source:: NVIDIA