
In MLPerf Inference v3.0, NVIDIA made its first submissions to the newly introduced Network division, which is now part of the MLPerf Inference Datacenter…
In MLPerf Inference v3.0, NVIDIA made its first submissions to the newly introduced Network division, which is now part of the MLPerf Inference Datacenter suite. The Network division is designed to simulate a real data center setup and strives to include the effect of networking—including both hardware and software—in end-to-end inference performance.
In the Network division, there are two types of nodes: Frontend nodes generate the queries, which are sent over the network to be processed by the Accelerator nodes, which perform inference. These are connected through standard network fabrics such as Ethernet or InfiniBand.
Figure 1. Closed division vs. Network division nodes
Figure 1 shows that the Closed division runs entirely on a single node. In the Network division, queries are generated on the Frontend node and transferred to the Accelerator node for inferencing.
In the Network division, the Accelerator nodes incorporate the inference accelerators as well as all networking components. This includes the network interface controller (NIC), network switch, and network fabric. So, while the Network division seeks to measure the performance of the Accelerator node and network, it excludes the impact of the Frontend node as the latter plays a limited role in the benchmarking.
NVIDIA performance in the MLPerf Inference v3.0 Network division
In MLPerf Inference v3.0, NVIDIA made Network division submissions on both the ResNet-50 and BERT workloads. The NVIDIA submissions achieved 100% of single-node performance on ResNet-50 by using the extremely high network bandwidth and low latency of GPUDirect RDMA technology on NVIDIA ConnectX-6 InfiniBand smart adapter cards.
BenchmarkDGX A100 (8x A100 80GB)Performance of the Network division compared to the Closed divisionResNet-50 (Low Accuracy)Offline100%Server100%BERT (Low Accuracy)Offline94%Server96%BERT (High Accuracy)Offline90%Server96%Table 1. ResNet-50 and BERT performance achieved in the Network division compared to the Closed division, with minimum network bandwidth required to sustain the achieved performance
The NVIDIA platform also showcased great performance on the BERT workload, with only a slight performance impact relative to the corresponding Closed division submission observed due to host-side batching overhead.
Technologies used in the NVIDIA Network division submission
A host of full-stack technologies enabled the strong NVIDIA Network division performance:
- A NVIDIA TensorRT backend for the optimized inference engine
- InfiniBand RDMA network transfers for low-latency, high-throughput tensor communication, built upon IBV verbs in Mellanox OFED software stack
- An Ethernet TCP socket for configuration exchange, run-state synchronization, and heartbeat monitoring
- A NUMA-aware implementation that uses CPU, GPU, and NIC resources for the best performance
Network division implementation details
Here’s a closer look at the implementation details of the MLPerf Inference Network division:
- InfiniBand for high-throughput, low-latency communication
- Network division inference flow
- Performance optimizations
InfiniBand for high-throughput, low-latency communication
The Network division requires the submitter to implement a query dispatch library (QDL) that takes the queries from the load generator and dispatches them to the Accelerator nodes in a way suited to the submitter’s setup.
- In the Frontend node, where the input tensor sequence is generated, the QDL abstracts the LoadGen system under the test (SUT) API to make it appear to the MLPerf Inference LoadGen that the accelerators are available to test locally.
- In the Accelerator node, the QDL makes it appear that it interacts with LoadGen for inference requests and responses directly. Within the QDL implementation by NVIDIA, we implement seamless data communication and synchronization using InfiniBand IBV verbs and an Ethernet TCP socket.
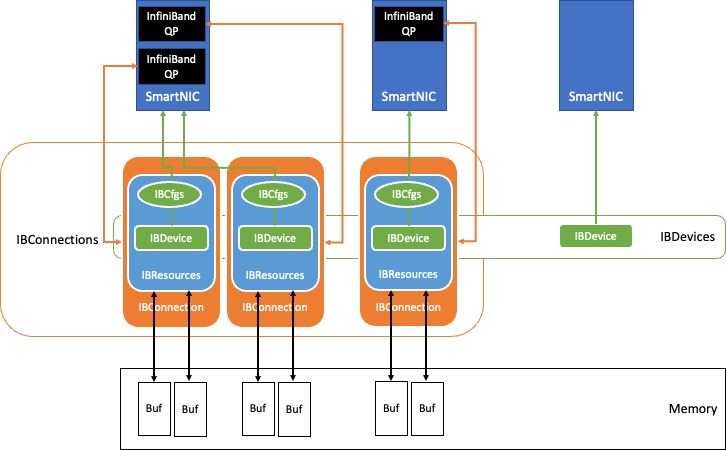 Figure 2. InfiniBand data exchange component inside the QDL
Figure 2. InfiniBand data exchange component inside the QDL
Figure 2 shows the data exchange component built in the QDL with InfiniBand technology.
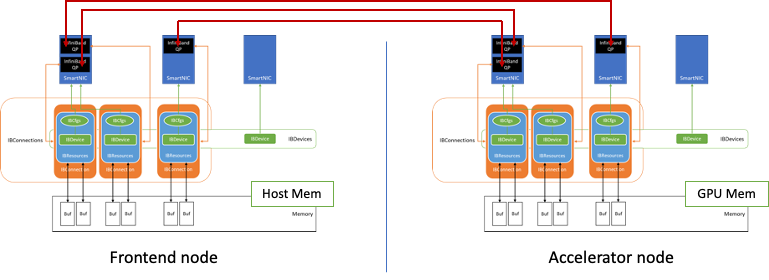 Figure 3. Example connection established between the Frontend and Accelerator nodes
Figure 3. Example connection established between the Frontend and Accelerator nodes
Figure 3 shows how connections are established between two nodes using this data exchange component.
InfiniBand queue pairs (QPs) are the basic connection point between the nodes. The NVIDIA implementation uses the lossless reliable connection (RC), which is similar to TCP, and transfer mode, while relying on an InfiniBand HDR optical fabric solution to sustain up to 200 Gbits/sec throughput.
When the benchmarking begins, the QDL initialization discovers the InfiniBand NICs available in the system. Following the configuration stored in IBCfgs, the NICs designated for use are populated as IBDevice instances. During this population, memory regions for RDMA transfers are allocated, pinned, and registered as RDMA buffers and kept in IBResources, together with proper handles.
RDMA buffers of the Accelerator node reside in GPU memory to leverage GPUDirect RDMA. The RDMA buffer information, as well as the proper protection keys, are then communicated with the peer node through a TCP socket over Ethernet. This creates the IBConnection instance for the QDL.
The QDL implementation is NUMA-aware and maps the closest NUMA host memory, CPUs, and GPUs to each NIC. Each NIC uses the IBConnection to talk to a peer’s NIC.
Network division inference flow
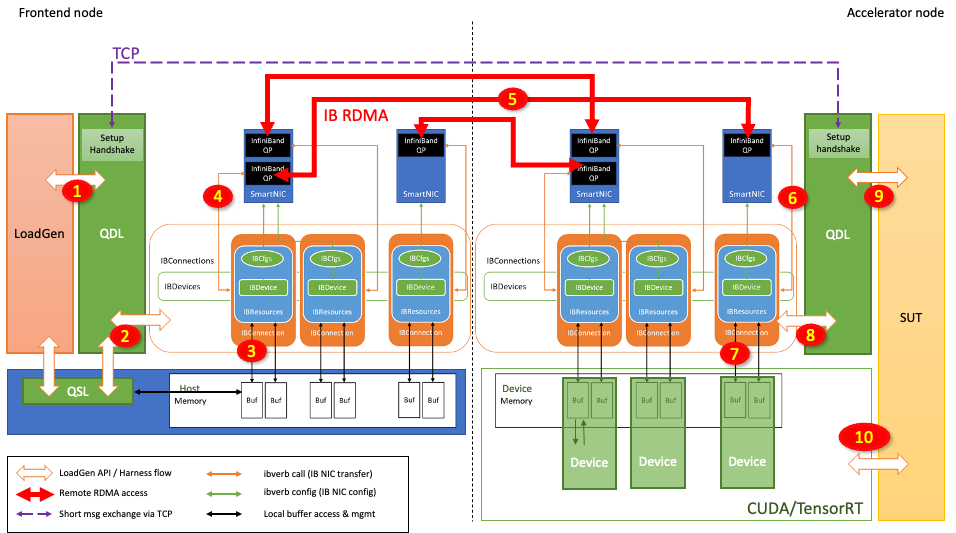 Figure 4. Inference request flow from Frontend node to Accelerator node using DirectGPU RDMA
Figure 4. Inference request flow from Frontend node to Accelerator node using DirectGPU RDMA
Figure 4 shows how the inference request is sent from the Frontend node and processed at the Accelerator node:
When the inference is ultimately performed as in step 10, the output tensors are generated and populated in the RDMA buffer. Then the Accelerator node starts transferring the response tensors to the Frontend node in a similar fashion but in the opposite direction.
Performance optimizations
The NVIDIA implementation uses InfiniBand RDMA Write and takes advantage of the shortest latency. For the RDMA Write to happen successfully, the sender must explicitly manage target memory buffers.
Both Frontend and Accelerator nodes manage buffer trackers to make sure that each query and response is kept in memory until consumed. As an example, ResNet-50 requires that up to 8K transactions be managed per connection (QP) to sustain the performance.
Some of the following key optimizations are included in the NVIDIA implementation.
The following key optimizations support better scalability:
- Transaction tracker per IBConnection (QP): Each IBConnection has an isolated transaction tracker resulting in lock-free, intra-connection transaction bookkeeping.
- Multiple QP support per NIC: An arbitrary number of IBConnections can be instantiated on any NIC, making it easy to support a large number of transactions spontaneously.
The following key optimizations improve InfiniBand resource efficiency:
- Use of INLINE transfer for small messages: Transferring small messages (typically less than 64 bytes) through INLINE transfer significantly improves performance and efficiency by avoiding PCIe transfers.
- Use of UNSIGNALLED RDMA Write: CQ maintenance becomes much more efficient as UNSIGNALLED transactions wait in CQ until SIGNALLED transaction happens, triggering completion handling of all transactions queued up so far (bulk completion) in the same node.
- Use of solicited IB transfers: Unsolicited RDAM transactions may queue up in the remote node until a solicited RDMA transaction happens, triggering bulk completion in the remote node.
- Event-based CQ management: Avoiding busy waiting for CQ management frees up CPU cycles.
The following key optimizations improve memory system efficiency:
- RDMA transfer without staging in Frontend node: When sending input tensors, avoid host memory copies by populating input tensors in the RDMA registered memory.
- Aggregating (CUDA) memcpys in Accelerator node: Improve the efficiency of GPU memory copies and PCIe transfers by gathering tensors in the consecutive memory as much as possible.
Each vendor’s QP implementation details the maximum number of completion queue entries (CQEs) supported, as well as the supported maximum QP entry sizes. It’s important to scale the number of QPs per NIC to cover the latency while sustaining enough transactions on-the-fly to achieve maximum throughput.
Host CPUs can also be stressed significantly if an extremely large number of transactions are handled in a short time from CQ by polling. Event-based CQ management, together with a reduction in the number of notifications, helps greatly in this case. Maximize the memory access efficiency by aggregating data in contiguous space as much as possible and, if possible, in the RDMA registered memory space. This is crucial to achieving maximum performance.
Summary
The NVIDIA platform delivered exceptional performance in its inaugural Network division submission on top of our continued performance leadership in the MLPerf Inference: Datacenter Closed division. These results were achieved using many NVIDIA platform capabilities:
- NVIDIA A100 Tensor Core GPU
- NVIDIA DGX A100
- NVIDIA ConnectX-6 InfiniBand networking
- NVIDIA TensorRT
- GPUDirect RDMA
The results provide a further demonstration of the performance and versatility of the NVIDIA AI platform in real data center deployments on industry-standard, peer-reviewed benchmarks.
Source:: NVIDIA