
Automatic parking assist must overcome some unique challenges when perceiving obstacles. An ego vehicle contains sensors that perceive the environment around…
Automatic parking assist must overcome some unique challenges when perceiving obstacles. An ego vehicle contains sensors that perceive the environment around the vehicle. During parking, the ego vehicle must be close to dynamic obstacles like pedestrians and other vehicles, as well as static obstacles such as pillars and poles. To fit into the parking spot, it also may be required to navigate low obstacles such as wheel barriers and curbs.
NVIDIA DRIVE Labs videos take an engineering-focused look at autonomous vehicle challenges and how the NVIDIA DRIVE team is addressing them. The following video introduces early grid fusion (EGF) as a new technique that enhances near-field obstacle avoidance in automatic parking assist.
Video 1. NVIDIA DRIVE Labs Episode 29: Enhanced Obstacle Avoidance for Autonomous Parking in Tight Spaces
Existing parking obstacle perception solutions depend on either ultrasonic sensors or fisheye cameras. Ultrasonic sensors are mounted on the front and rear bumpers and typically don’t cover the flank. As a result, the system is unable to perceive the ego vehicle’s sides—especially for dynamic obstacles.
Fisheye cameras, on the other hand, suffer from degraded performance in low visibility, low light, and bad weather conditions.
The NVIDIA DRIVE platform is equipped with a suite of cameras, radar, and ultrasonic sensors to minimize unseen areas and maximize sensing redundancy for all operating conditions. EGF uses a machine-learned early fusion of multiple sensor inputs to provide an accurate, efficient, and robust near-field 3D obstacle perception.
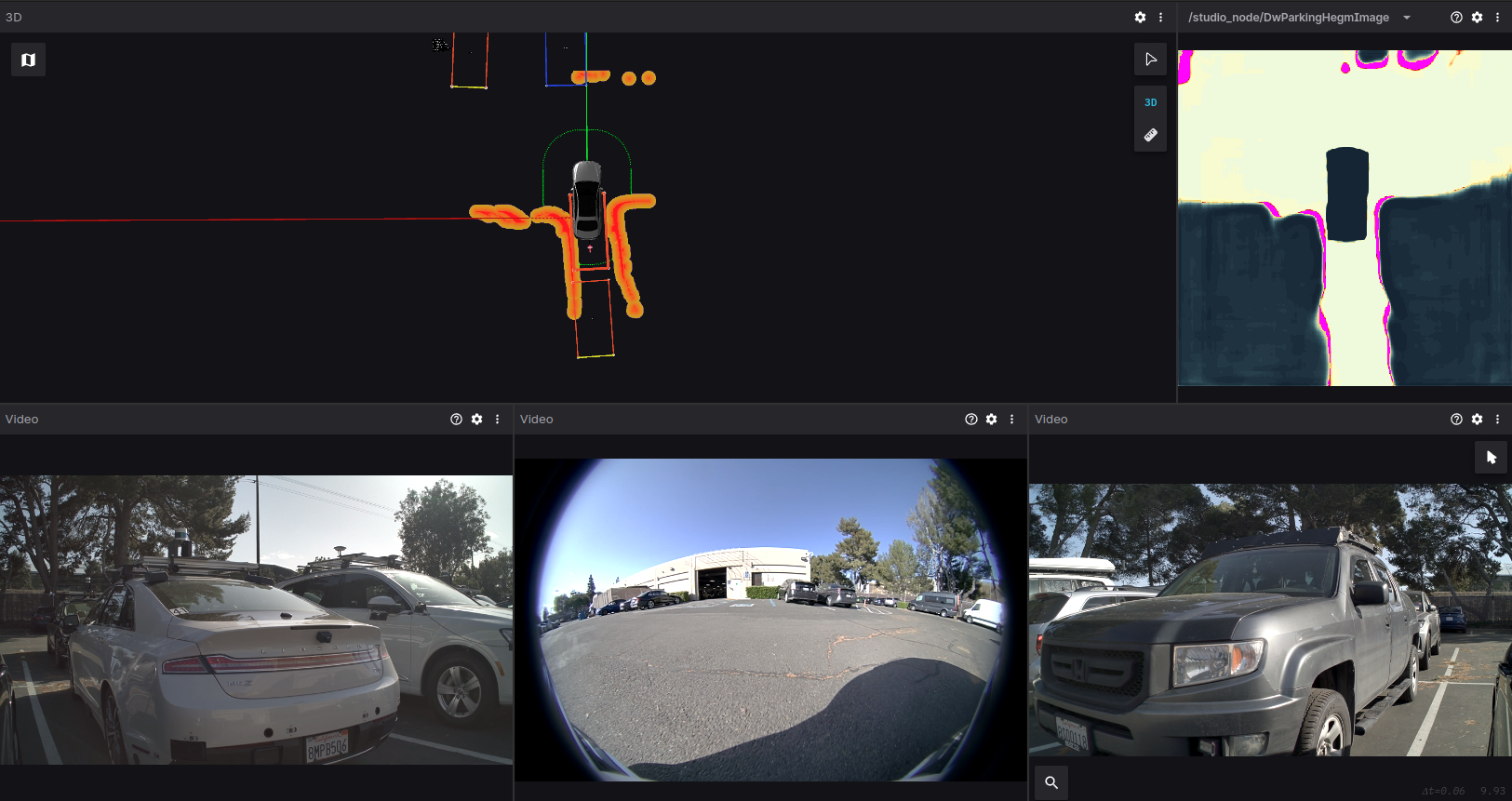 Figure 1. EGF detecting parked cars as obstacles while parking with NVIDIA automatic parking assist
Figure 1. EGF detecting parked cars as obstacles while parking with NVIDIA automatic parking assist
Early grid fusion overview
To better understand the innovative technique behind EGF, look at its DNN architecture and output/input representation.
Output: Height map representation
EGF outputs a height map with a grid resolution of 4 cm. Each pixel in the height map has a float value representing the height relative to the local ground.
In Figure 2, the green highlighted panel is the output of the EGF DNN. Light blue represents the ground. Yellow represents low obstacles, for example, the curb in the back. Bright red represents the outline of high obstacles, for example, the rounded L shape contours for parked cars and the dot for a tree behind the ego vehicle. The dark red area behind the bright red outlines represents potential occluded areas behind high obstacles.
 Figure 2. EGF input and output visualization
Figure 2. EGF input and output visualization
This representation enables EGF to capture rich information about the world around it. The high-resolution grid can represent the rounded corner of cars on the rear left and right of the ego vehicle. Capturing the rounded corners is essential for the parking planner to have sufficient free space to perform the parking maneuver between two parked cars in a tight spot.
With different height values per pixel, you can distinguish between the curb for which the car has sufficient clearance and the light pole on the curb that the car must stay clear of.
Input: Ultrasonic and camera
Most multi-sensor fusion perception solutions are late-fusion systems operating on the detection level. Traditional ultrasonic detections obtained by trilateration are fused with polygon detections from the camera in a late-fusion stage, usually with hand-crafted fusion rules.
In contrast, EGF uses an early-fusion approach. Low-level signals from the sensor are directly fed to the DNN, which learns the sensor fusion through a data-driven approach.
For ultrasonic sensors, EGF taps into the raw envelope interface that provides reflection intensity with sub-centimeter accuracy. These envelope signals are projected into a planar view map using the extrinsic position and intrinsic beam properties of the ultrasonic sensor (Figure 3 bottom left). These ultrasonic maps, as shown in the highlighted pink panel in Figure 2, capture much more information than trilateration detections. This enables height detection in EGF.
Figure 3. EGF DNN architecture
For camera sensors, EGF shares the image encoder backbone with MLMCF–NVIDIA multitask multi-camera perception backbone used for higher-speed driving. First, we process image features through CNN layers. Then, we perform uplifting of the features from an image space to a bird’s eye view space using a learned transform per camera (Figure 3 top-right box).
The ultrasonic and camera feature maps are then fused in an encoder network, and the height map is decoded from the combined features (Figure 3 right side).
Conclusion
EGF is an innovative, machine-learning–based, perception component to increase safety for autonomous parking. By using early fusion for multi-modality raw sensor signals, EGF builds a high level of trust for near-field obstacle avoidance.
To learn more about the software functionality that we’re building, see the rest of the NVIDIA DRIVE Labs video series. Catch up on more NVIDIA DRIVE posts.
Source:: NVIDIA