
We were stuck. Really stuck. With a hard delivery deadline looming, our team needed to figure out how to process a complex extract-transform-load (ETL) job on…
We were stuck. Really stuck. With a hard delivery deadline looming, our team needed to figure out how to process a complex extract-transform-load (ETL) job on trillions of point-of-sale transaction records in a few hours. The results of this job would feed a series of downstream machine learning (ML) models that would make critical retail assortment allocation decisions for a global retailer. Those models needed to be tested and validated on real transactional data.
However, up to that point, not a single ETL job ran to completion. Each test run took several days of processing time and all had to be terminated before completion.
Using NVIDIA RAPIDS Accelerator for Apache Spark, we observed significantly faster run times with additional cost savings when compared to a conventional approach using Spark on CPUs. Let us back up a bit.
Getting unstuck: ETL for a global retailer
The Artificial Intelligence & Analytics practice at Capgemini is a data science team that provides bespoke, platform–, and language-agnostic solutions that span the data science continuum, from data engineering to data science to ML engineering and MLOps. We are a team with deep technical experience and knowledge, having 100+ North America-based data science consultants, and a global team of 1,600+ data scientists.
For this project, we were tasked with providing an end-to-end solution for an international retailer with the following deliverables:
- Creating the foundational ETL
- Building a series of ML models
- Creating an optimization engine
- Designing a web-based user interface to visualize and interpret all data science and data engineering work
This work ultimately provided an optimal retail assortment allocation solution for each retail store. What made the project more complex was the state-space explosion that occurs after we begin to incorporate halo effects, such as interaction effects across departments. For example, if we allocated shelf space to fruit, what effect does that have on KPIs associated with allocating further shelf space to vegetables, and how can we jointly optimize those interaction effects?
But none of that ML, optimization, or front end would matter without the foundational ETL. So here we were, stuck. We were operating in an Azure cloud environment, using Databricks and Spark SQL, and even then, we were not observing the results we needed in the timeframe required by the downstream models.
Spurred by a sense of urgency, we explored potential variations that might enable us to significantly speed up our ETL process.
Accelerating ETL
Was the code inefficiently written? Did it maximize compute speed? Did it have to be refactored?
We rewrote code several times, and tested various cluster configurations, only to observe marginal gains. However, we had limited options to scale up owing to cost limitations, none of which provided the horsepower we needed to make significant gains. Remember when cramming for final exams, and time was just a little too tight, that pit in your stomach getting deeper by the minute? We were quickly running out of options and time. We needed help. Now.
With the Databricks Runtime 9.1 LTS, Databricks released a native vectorized query engine named Photon. Photon is a C++ runtime environment that can run faster and be more configurable than its traditional Java runtime environment. Databricks support assisted us for several weeks in configuring a Photon runtime for our ETL application.
We also reached out to our partners at NVIDIA, who recently updated the RAPIDS suite of accelerated software libraries. Built on CUDA-X AI, RAPIDS executes data science and analytics pipelines entirely on GPUs with APIs that look and feel like the most popular open-source libraries. They include a plug-in that integrates with Spark’s query planner to speed up Spark jobs.
With support from both Databricks and NVIDIA over the course of the following month, we developed both solutions in parallel, getting previously untenable run times down to sub-two hours, an amazing jump in speed!
This was the target speed that we needed to hit for the downstream ML and optimization models. The pressure was off, and—owing solely to having solved the ETL problem with Photon a few days earlier than we did with RAPIDS—the Databricks Photon solution was put into production.
Having emerged from the haze of anxiety surrounding the tight deadlines around the ETL processes, we collected our thoughts and results and conducted a posthoc analysis. Which solution was the fastest to implement? Which solution provided the fastest ETL? The cheapest ETL? Which solution would we implement for similar future projects?
Experimental results
To evaluate our hypotheses, we created a set of experiments. We ran these experiments on Azure using two approaches:
We would run the same ETL jobs on both, using two different data sets. The data sets were five and 10 columns of mixed numeric and unstructured (text) data, each with 20 million rows that measured 156 and 565 terabytes, respectively. The number of workers was maximized as permitted by infrastructure spending limits. Each individual experiment was run three times.
The experimental parameters are summarized in Table 1.
Worker typeDriver typeNumber of workersPlatformNumber of columnsData sizeStandard_NC6s_v3Standard_NC6s_v312RAPIDS10565Standard_E20s_v5Standard_E16s_v56PHOTON10565Standard_NC6s_v3Standard_NC6s_v316RAPIDS10565Standard_NC6s_v3Standard_NC6s_v314RAPIDS10565Standard_NC6s_v3Standard_NC6s_v314RAPIDS5157Standard_E20s_v5Standard_E16s_v56PHOTON5148Table 1. ETL experimentation parameters
We examined the pure speed of runtimes. The experimental results demonstrated that run times across all different combinations of worker types, driver types, workers, data set size, platform, columns of data, and data set size were remarkably consistent and statistically and practically indifferentiable at an average of 4 min 37 sec per run, with min and max run times at 4 min 28 sec and 4 min 54 sec, respectively.
We had a DBU/hour infrastructure spending limit and, as a result, a limit on the varying workers per cluster tested. In response, we developed a composite metric that enabled the most balanced evaluation of results, which we named adjusted DBUs per minute (ADBUs). DBUs are Databricks units, a proprietary Databricks unit of computational cost. ADBUs are computed as follows:
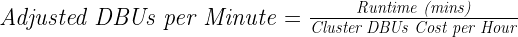
In the aggregate, we observed a 6% decrease in ADBUs by using RAPIDS Accelerator for Apache Spark when compared to running Spark on the Photon runtime, when accounting for the cloud platform cost. This meant we could achieve similar run times using RAPIDS at a lower cost.
Considerations
Other considerations include the ease of implementation and the need for rewriting code, both of which were similar for RAPIDS and Photon. A first-time implementation of either is not for the faint of heart.
Having done it one time, we are quite certain we can replicate the required cluster configuration tasks in a matter of hours for each. Moreover, neither RAPIDS nor Photon required us to refactor the Spark SQL code, which was a huge time savings.
The limitations of this experiment were the small number of replications, the limited number of worker and driver types, and the number of worker combinations, all owing to infrastructure cost limitations.
What’s next?
In the end, combining Databricks with RAPIDS Accelerator for Apache Spark helped expand the breadth of our data engineering toolkit, and demonstrated a new and viable paradigm for ETL processing on GPUs.
For more information, see RAPIDS Accelerator for Apache Spark.
Source:: NVIDIA