
Imagine you are a robotics or machine learning (ML) engineer tasked with developing a model to detect pallets so that a forklift can manipulate them. You are…
Imagine you are a robotics or machine learning (ML) engineer tasked with developing a model to detect pallets so that a forklift can manipulate them. You are familiar with traditional deep learning pipelines, you have curated manually annotated datasets, and you have trained successful models.
You are ready for the next challenge, which comes in the form of large piles of densely stacked pallets. You might wonder, where should I begin? Is 2D bounding box detection or instance segmentation most useful for this task? Should I do 3D bounding box detection and, if so, how will I annotate it? Would it be best to use a monocular camera, stereo camera, or lidar for detection? Given the sheer quantity of pallets that occur in natural warehouse scenes, manual annotation will not be an easy endeavor. And if I get it wrong, it could be costly.
This is what I wondered when faced with a similar situation. Fortunately, I had an easy way to get started with relatively low commitment: synthetic data.
Overview of synthetic data
Synthetic Data Generation (SDG) is a technique for generating data to train neural networks using rendered images rather than real-world images. The advantage of using synthetically rendered data is that you implicitly know the full shape and location of objects in the scene and can generate annotations like 2D bounding boxes, keypoints, 3D bounding boxes, segmentation masks, and more.
Synthetic data can be a great way to bootstrap a deep learning project, as it enables you to rapidly iterate on ideas before committing to large manual data annotation efforts or in cases where data is limited, restricted, or simply does not exist. For such cases, you might find that synthetic data with domain randomization works very well for your application out-of-the-box first try. And viola–you save time.
Alternatively, you might find that you need to redefine the task or use a different sensor modality. Using synthetic data, you can experiment with these decisions without committing to a costly annotation effort.
In many cases, you may still benefit from using some real-world data. The nice part is, by experimenting with synthetic data you will have more familiarity with the problem, and can invest your annotation effort where it counts the most. Each ML task presents its own challenges, so it is difficult to determine exactly how synthetic data will fit in, whether you will need to use real-world data, or a mix of synthetic and real data.
Using synthetic data to train a pallet segmentation model
When considering how to use synthetic data to train a pallet detection model, our team started small. Before we considered 3D box detection or anything complex, we first wanted to see if we could detect anything at all using a model trained with synthetic data. To do so, we rendered a simple dataset of scenes containing just one or two pallets with a box on top. We used this data to train a semantic segmentation model.
We chose to train a semantic segmentation model because the task is well defined and the model architectures are relatively simple. It is also possible to visually identify where the model is failing (the incorrectly segmented pixels).
To train the segmentation model, the team first rendered coarse synthetic scenes (Figure 1).
 Figure 1. A coarse synthetic rendering of two pallets with a box on top
Figure 1. A coarse synthetic rendering of two pallets with a box on top
The team suspected that these rendered images alone would lack the diversity to train a meaningful pallet detection model. We also decided to experiment with augmenting the synthetic renderings using generative AI to produce more realistic images. Before training, we applied generative AI to these images to add variation that we believed would improve the ability of the model to generalize to the real world.
This was done using a depth conditioned generative model, which roughly preserved the pose of objects in the rendered scene. Note that using generative AI is not required when working with SDG. You could also try using traditional domain randomization, like varying the synthetic textures, colors, location, and orientation of the pallets. You may find that traditional domain randomization by varying the rendered textures is sufficient for the application.
 Figure 2. The synthetic rendering, augmented using generative AI
Figure 2. The synthetic rendering, augmented using generative AI
After rendering about 2,000 of these synthetic images, we trained a resnet18-based Unet segmentation model using PyTorch. Quickly, the results showed great promise on real-world images (Figure 3).
 Figure 3. Real-world pallet image, tested with segmentation model
Figure 3. Real-world pallet image, tested with segmentation model
The model could accurately segment the pallet. Based on this result, we developed more confidence in the workflow, but the challenge was far from over. Up to this point, the team’s approach did not distinguish between instances of pallets, and it did not detect pallets that were not placed on the floor. For images like the one shown in Figure 4, the results were barely usable. This likely meant that we needed to adjust our training distribution.
 Figure 4. Semantic segmentation model fails to detect stacked pallets
Figure 4. Semantic segmentation model fails to detect stacked pallets
Iteratively increasing the data diversity to improve accuracy
To improve the accuracy of the segmentation model, the team added more images of a wider variety of pallets stacked in different random configurations. We added about 2,000 more images to our dataset, bringing the total to about 4,000 images. We created the stacked pallet scenes using the USD Scene Construction Utilities open-source project.
USD Scene Construction Utilities was used to position pallets relative to each other in configurations that reflect the distribution you might see in the real world. We used Universal Scene Description (OpenUSD) SimReady Assets, which offered a large diversity of pallet models to choose from.
 Figure 5. Structured scenes created using the USD Python API and USD Scene Construction Utilities, and further randomized and rendered with Omniverse Replicator
Figure 5. Structured scenes created using the USD Python API and USD Scene Construction Utilities, and further randomized and rendered with Omniverse Replicator
Training with the stacked pallets, and with a wider variety of viewpoints, we were able to improve the accuracy of the model for these cases.
If adding this data helped the model, why generate only 2,000 images if there is no added annotation cost? We did not start with many images because we were sampling from the same synthetic distribution. Adding more images would not necessarily add much diversity to our dataset. Instead, we might just be adding many similar images without improving the model’s real-world accuracy.
Starting small enabled the team to quickly train the model, see where it failed, and adjust the SDG pipeline and add more data. For example, after noticing the model had a bias towards specific colors and shapes of pallets, we added more synthetic data to address these failure cases.
 Figure 6. A rendering of plastic pallets in various colors
Figure 6. A rendering of plastic pallets in various colors
These data variations improved the model’s ability to handle the failure scenarios it encountered (plastic and colored pallets).
If data variation is good, why not just go all-out and add a lot of variation at once? Until our team began testing on real-world data, it was difficult to tell what variance might be required. We might have missed important factors needed to make the model work well. Or, we might have overestimated the importance of other factors, exhausting our effort unnecessarily. By iterating, we better understood what data was needed for the task.
Extending the model for pallet side face center detection
Once we had some promising results with segmentation, the next step was to adjust the task from semantic segmentation to something more practical. We decided that the simplest next task to evaluate was detecting the center of the pallet side faces.
 Figure 7. Example data for the pallet side face center detection task
Figure 7. Example data for the pallet side face center detection task
The pallet side face center points are where a forklift would center itself when manipulating the pallet. While more information may be necessary in practice to manipulate the pallet (such as the distance and angle at this point), we considered this point a simple next step in this process that enables the team to assess how useful our data is for any downstream application.
Detecting these points could be done with heat map regression, which, like segmentation, is done in the image domain, is easy to implement, and simple to visually interpret. By training a model for this task, we could quickly assess how useful our synthetic dataset is at training a model to detect important key points for manipulation.
The results after training were promising, as shown in Figure 8.
 Figure 8. Real-world detection results for the pallet side face detection model
Figure 8. Real-world detection results for the pallet side face detection model
The team confirmed the ability to detect the pallet side faces using synthetic data, even with closely stacked pallets. We continued to iterate on the data, model, and training pipeline to improve the model for this task.
Extending the model for corner detection
When we reached a satisfactory point for the side face center detection model, we explored taking the task to the next level: detecting the corners of the box. The initial approach was to use a heat map for each corner, similar to the approach for the pallet side face centers.
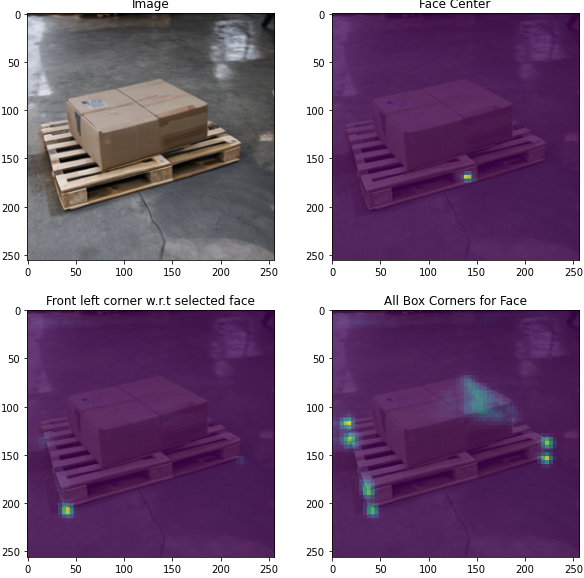 Figure 9. Pallet corner detection model using heat maps
Figure 9. Pallet corner detection model using heat maps
However, this approach quickly presented a challenge. Because the object for detection had unknown dimensions, it was difficult for the model to precisely infer where the corner of the pallet should be if it was not directly visible. Using heat maps, if the peak values are inconsistent, it is difficult to parse them reliably.
So, instead of using heat maps, we chose to regress the corner locations after detecting the face center peak. We trained a model to infer a vector field that contains the offset of the corners from a given pallet face center. This approach quickly showed promise for this task, and we could provide meaningful estimates of corner locations, even with large occlusions.
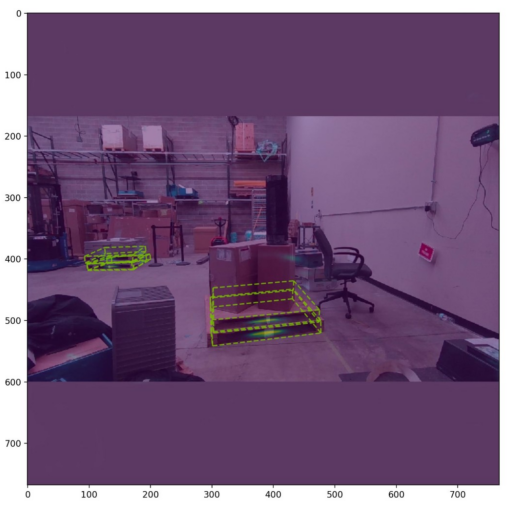 Figure 10. The pallet detection results using face center heat map and vector field-based corner regression
Figure 10. The pallet detection results using face center heat map and vector field-based corner regression
Now that the team had a promising working pipeline, we iterated and scaled this process to address different failure cases that arose. In total, our final model was trained on roughly 25,000 rendered images. Trained at a relatively low resolution (256 x 256 pixels), our model was capable of detecting small pallets by running inference at higher resolutions. In the end, we were able to detect challenging scenes, like the one above, with relatively high accuracy.
This was something we could use–all created with synthetic data. This is where our pallet detection model stands today.
 Figure 11. The final pallet model detection results, with only the front face of the detection shown for ease of visualization
Figure 11. The final pallet model detection results, with only the front face of the detection shown for ease of visualization
 Figure 12. The pallet detection model running in real time
Figure 12. The pallet detection model running in real time
Get started building your own model with synthetic data
By iteratively developing with synthetic data, our team developed a pallet detection model that works on real-world images. Further progress may be possible with more iteration. Beyond this point, our task might benefit from the addition of real-world data. However, without synthetic data generation, we could not have iterated as quickly, as each change we made would have required new annotation efforts.
If you are interested in trying this model, or are working on an application that could use a pallet detection model, you can find both the model and inference code by visiting SDG Pallet Model on GitHub. The repo includes the pretrained ONNX model as well as instructions to optimize the model with TensorRT and run inference on an image. The model can run in real time on NVIDIA Jetson AGX Orin, so you will be able to run it at the edge.
You can also check out the recently open-sourced project, USD Scene Construction Utilities, which contains examples and utilities for building USD scenes using the USD Python API.
We hope our experience inspires you to explore how you can use synthetic data to bootstrap your AI application. If you’d like to get started with synthetic data generation, NVIDIA offers a suite of tools to simplify the process. These include:
If you have questions about the pallet model, synthetic data generation with NVIDIA Omniverse, or inference with NVIDIA Jetson, reach out on GitHub or visit the NVIDIA Omniverse Synthetic Data Generation Developer Forum and the NVIDIA Jetson Orin Nano Developer Forum.
Explore what’s next in AI at SIGGRAPH
Join us at SIGGRAPH 2023 for a powerful keynote by NVIDIA CEO Jensen Huang. You’ll get an exclusive look at some of our newest technologies, including award-winning research, OpenUSD developments, and the latest AI-powered solutions for content creation.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. If you’re a developer, get started building your first extension or developing a Connector with Omniverse resources. Stay up-to-date on the platform by subscribing to the newsletter, and following NVIDIA Omniverse on Instagram, Medium, and Twitter. For resources, check out our forums, Discord server, Twitch, and YouTube channels.
Source:: NVIDIA