
As data generation continues to increase, linear performance scaling has become an absolute requirement for scale-out storage. Storage networks are like car…
As data generation continues to increase, linear performance scaling has become an absolute requirement for scale-out storage. Storage networks are like car roadway systems: if the road is not built for speed, the potential speed of a car does not matter. Even a Ferrari is slow on an unpaved dirt road full of obstacles.
Scale-out storage performance can be hindered by the Ethernet fabric that connects the storage nodes. NVIDIA accelerated Ethernet can remove performance bottlenecks, enabling maximum storage performance for applications in general, and AI/ML in particular.
Scale-out storage requires a strong network
Every second, 54,000 pictures are taken worldwide. By the time you read this, that number will be even higher. No matter what your business is, chances are you have massive amounts of data that must be stored and analyzed, with the amount growing every day.
The old scale-up approach of using ever-larger storage filers has been replaced with a scale-out approach to deliver storage that scales linearly in both capacity and performance.
With scale-out storage, or distributed storage, several smaller nodes are configured and connected to act as one logical unit. A single file or object can be spread across many nodes.
As more scale is needed, additional storage nodes are easily added to increase both storage capacity and performance. This applies to both a traditional enterprise storage vendor solution, or a software-defined solution, with the software and hardware sourced independently.
Distributed storage enables flexible scaling and cost efficiency, but requires a high-performance network to connect the storage nodes. Many data center switches are ill-suited to the unique traffic characteristics of storage, and in fact can cripple the performance of scale-out storage solutions.
How storage traffic is different from traditional traffic
For many use cases, network traffic is consistent and homogeneous, and traditional Ethernet suffices. However, traffic generated by storage devices may cause the issues detailed below.
Network stress
Current storage solutions benefit from faster SSDs and storage interfaces, such as NVMe and PCIe Gen 4 (soon PCIe Gen 5), that are designed to provide higher performance.
Congestion
When the storage fabric is saturated, network congestion becomes inevitable, just like roadway congestion when too much traffic is on the highway. Network congestion is particularly problematic for scale-out storage because each storage node is expected to offer fast data delivery. But when congestion occurs, many data center switches have a fairness problem, where some nodes will be slowed much more than others. A single file or object is usually spread across many nodes, so anything that slows a single node effectively slows the whole cluster.
Bursty traffic
Most storage workloads are bursty, generating intense data transfers and repeatedly requiring large amounts of bandwidth for short periods. When that happens, the network switch must use its buffer to absorb the burst until the transient burst is over, thus preventing packet loss. Otherwise, that packet loss will require data retransmissions, significantly deteriorating application performance.
Storage jumbo frames
Traditional data center network traffic uses a maximum packet size (MTU) of 1.5 KB. Scale-out storage nodes perform better when they can use 9 KB “jumbo frames,” which increase throughput while reducing CPU processing overhead. Many data center switches built with commodity switch ASICs perform poorly or unpredictably with jumbo frames.
Low latency
One of the ways storage IOPs have improved is through the orders-of-magnitude latency reduction for the read/write operations in flash-based media. However, those costly performance improvements can be lost when the network introduces high latency—especially due to excessive buffering.
Both training and inference require adequate amounts of data with high-speed access, to make sure that GPU processors are fed quickly enough to keep them fully engaged. During training, WRITE operations are performed by all nodes to improve model accuracy. This results in a burst, making it imperative for switches to handle congestion effectively. Finally, lower storage latency enables GPUs to handle compute tasks more efficiently.
Why ASICs are suboptimal for storage traffic
Most data center switches are built using commodity switch ASICs that were cost-optimized for traditional data traffic patterns and packet sizes. To keep costs low while achieving their bandwidth targets, Ethernet switch chip vendors compromised fairness by using a split buffer architecture.
Every switch has a buffer to absorb traffic bursts and prevent packet loss when congestion occurs. The common approach is to have a buffer that is shared across many ports. However, not all shared buffers are the same—there are different buffer architectures.
Commodity switches do not have a fully shared buffer—they use either an ingress-shared buffer, or an egress-shared buffer.
With an ingress-shared buffer, there is a static mapping between a group of incoming ports and a specific memory slice. These ports can use only the memory in that assigned slice and not the whole buffer, not even if the rest of the buffer is available and no one is using it.
With an egress-shared buffer, the mapping is between a group of outgoing ports and a specific buffer memory slice. Again, each group of egress ports can only use its assigned buffer slice, not the whole buffer.
With these two architectures, flows that stay within the same memory slice do not behave like flows that travel between memory slices. If many flows use ports with the same buffer, those ports will experience higher latency and lower throughput, while traffic using other slices of the buffer will enjoy higher performance.
The storage performance depends on which ports the storage traffic (and other traffic) is using and how busy are the buffer slices for those ports. This is why switches that use split buffers often experience issues related to fairness, predictability, and microburst absorption.
Why deep-buffer switches are suboptimized for storage
Deep-buffer switches usually refer to a switch that offers much more buffering (GBs rather than MBs). Deep-buffer switches are often promoted for use as routers, because they can absorb and hold large traffic bursts if there is a mismatch in network speeds or an incast situation.
But in most data center applications, including scale-out storage, the deep-buffer switches negatively impact performance for the following reasons:
Job completion time
With parallel file systems, the storage node with the slowest response dictates the time required to fetch a file. Unlike commodity switch ASICs that have a sliced on-chip buffer, deep-buffer switches have both on-chip and off-chip buffers, and they all are sliced, not fully shared, buffers.
Think of how many ways flows can go before they leave the switch. They can stay within one on-chip memory slice (fastest), travel between on-chip memory slices (slower), or travel between on-chip and off-chip memory slices (very slow).
All these flows will behave differently, and hence will cause fairness and predictability issues for storage traffic. Because these issues slow down one or more nodes, they adversely impact job completion time and slow down the whole distributed storage cluster.
Latency
The larger the switch buffer, the longer the queue each packet must go through and the greater the latency. The tested average port-to-port latency of a deep-buffer switch is more than 500 microseconds. Compared to a fully shared buffer switch from the same generation, NVIDIA Spectrum 1 latency is just 0.3 microseconds. It requires nanoseconds rather than microseconds to switch/route a packet.
Deep-buffer latency is 1,000x higher. You may be wondering, is this just happening when congestion occurs? No. Under congestion, deep-buffer latencies will be much higher; in fact, up to 20 milliseconds, or 50,000x higher. While 500 microseconds of latency might be okay for a router between data centers, within a data center it spells death to flash storage performance.
Power and cost
Deep-buffer switches need hundreds of watts of power to operate even when idling, making their ongoing operational cost higher. The initial purchase cost of deep-buffer switches is also much higher. This might be justified if performance was better, but real-world testing has proven just the opposite.
Choosing an inappropriate network switch will severely slow down your storage workloads, making your expensive fast storage act like cheaper and slower storage.
With NVIDIA Spectrum, both CapEx and OpEx can be reduced. Watts can also be used for other purposes within a rack.
NVIDIA Spectrum switches are optimized for storage
With commodity switch ASICs, flows are either staying at the same memory slice or traveling between memory slices.
With NVIDIA Spectrum switches, all flows behave the same due to the fully shared buffer. The value of this architecture is maximum burst absorption capacity as well as optimal fair and predictable performance. All traffic flows through a switch receive the same treatment and generally enjoy the same good performance, regardless of which ingress and egress ports they use.
Benchmarking the deep-buffer switch and NVIDIA Spectrum
The first case uses a common storage benchmarking FIO tool for WRITE operations from two initiators to one target while background traffic is running. This is a typical storage scenario.
The team measured the time required for the FIO job to complete (shorter is better). With the deep-buffer switch, the FIO job took 87 seconds. With the NVIDIA Spectrum switch, the job ran 40% faster and completed after just 51 seconds.
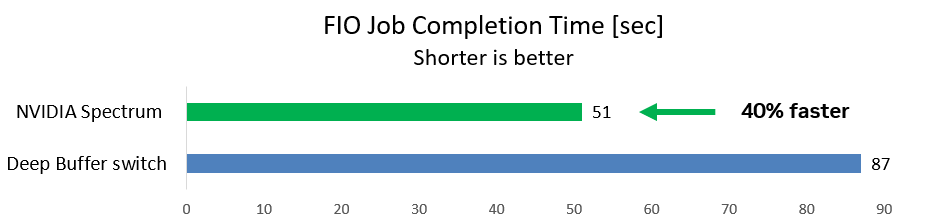 Figure 1. Storage write operations are 40% faster with the NVIDIA Spectrum switch compared to a deep-buffer switch
Figure 1. Storage write operations are 40% faster with the NVIDIA Spectrum switch compared to a deep-buffer switch
Deep-buffer switches greatly increase latency, which slows down your storage and reduces your application performance. But how high can the latency go?
For the second case, the team took the deep-buffer switch and tested how latency is impacted under different congestion use cases. The maximum buffer occupancy is only around 10% of the whole buffer size.
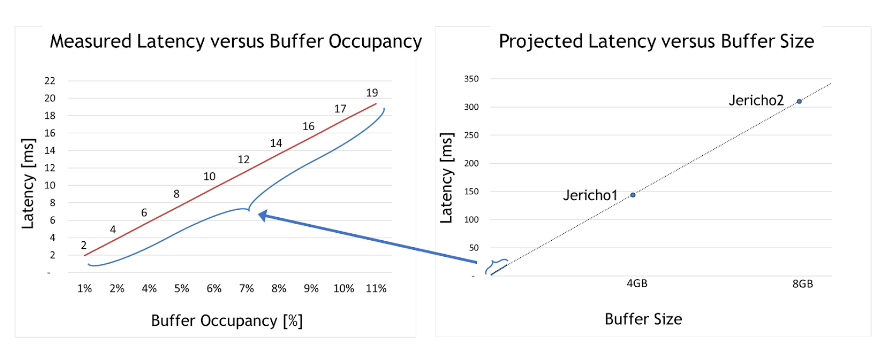 Figure 2. Real and projected latency compared to buffer size and buffer occupancy
Figure 2. Real and projected latency compared to buffer size and buffer occupancy
Two meaningful insights can be derived from the graph on the left of Figure 2. First, deep-buffer switch latency is 50,000x higher than Spectrum switches (2–19 milliseconds compared to only 300 nanoseconds for Spectrum).
Second, linear dependency is apparent between buffer occupancy and latency. In other words, testing proved that the larger the occupied buffer, the greater the latency.
With that understanding, the graph on the right of Figure 2 projects the maximum latency per deep-buffer ASIC (such as Jericho 1, Jericho 2, or Ramon). These very high latency numbers are incompatible with data center applications in general and fast storage solutions in particular.
For the third case, the team used two Windows machines and simultaneously copied a file from each to the same target storage.
With the deep-buffer switch, one Windows machine had three times the bandwidth of the other (830 MBps compared to 290 MBps). With Spectrum switch, each machine had 584 MBps (50% as expected).
Real-world testing showed that deep-buffer switches do not have a positive impact on data center applications, such as absorbing packets and preventing drops.
Deep-buffer switches may be needed for long haul or WAN connections; however, they are suboptimal for data center applications and will have negative effects, particularly when the workload is scaled beyond just two nodes, as in this use case.
 Figure 3. The deep-buffer switch provides unfair bandwidth per node (left) while the NVIDIA Spectrum switch provides equal bandwidth (right)
Figure 3. The deep-buffer switch provides unfair bandwidth per node (left) while the NVIDIA Spectrum switch provides equal bandwidth (right)
These three use cases demonstrate proof points for why deep-buffer switches adversely impact AI/ML and storage workloads, while Spectrum switches provide maximized performance.
Summary
NVIDIA Spectrum Ethernet switches are built for AI/ML and storage workloads, and perform better than switches with split buffers or deep buffers. They handle congestion better, prevent packet loss, and outperform with jumbo frames (preferred for storage). NVIDIA Spectrum Ethernet switches provide overall good application performance with consistently low network latency.
Learn more about NVIDIA Spectrum Ethernet switches. Dive deeper into networking storage in the NVIDIA Developer Forums.
Source:: NVIDIA