
Apache Spark is an industry-leading platform for distributed extract, transform, and load (ETL) workloads on large-scale data. However, with the advent of deep…
Apache Spark is an industry-leading platform for distributed extract, transform, and load (ETL) workloads on large-scale data. However, with the advent of deep learning (DL), many Spark practitioners have sought to add DL models to their data processing pipelines across a variety of use cases like sales predictions, content recommendations, sentiment analysis, and fraud detection.
Yet, combining DL training and inference with large-scale data has historically been a challenge for Spark users. Most of the DL frameworks were designed for single-node environments, and their distributed training and inference APIs were often added as an after-thought.
To help solve this disconnect between the single-node DL environments and large-scale distributed environments, there are multiple third-party solutions such as Horovod-on-Spark, TensorFlowOnSpark, and SparkTorch. But, since these solutions were not natively built into Spark, users must evaluate each platform against their own needs.
With the release of Spark 3.4, users now have access to built-in APIs for both distributed model training and model inference at scale, as detailed below.
Distributed training
For distributed training, there is a new TorchDistributor API for PyTorch, which follows the spark-tensorflow-distributor API for TensorFlow. These simplify the migration of distributed DL model training code to Spark by taking advantage of Spark’s barrier execution mode to spawn the distributed DL cluster nodes on top of the Spark executors.
Once the DL cluster has been started by Spark, control is essentially handed off to the DL frameworks through the main_fn that was passed to the TorchDistributor API.
As shown in the following code, only minimal code changes are required to run standard distributed DL training on Spark with this new API.
from pyspark.ml.torch.distributor import TorchDistributor
def main_fn(checkpoint_dir):
# standard distributed PyTorch code
...
# Set num_processes = NUM_WORKERS * NUM_GPUS_PER_WORKER
output_dist = TorchDistributor(num_processes=2, local_mode=False, use_gpu=True).run(main_fn, checkpoint_dir)Once launched, the processes running on the executors rely on the built-in distributed training APIs of their respective DL frameworks. There should be few or no modifications required to port existing distributed training code to Spark. The processes can then communicate with each other during training and also directly access the distributed file system associated with the Spark cluster (Figure 1).
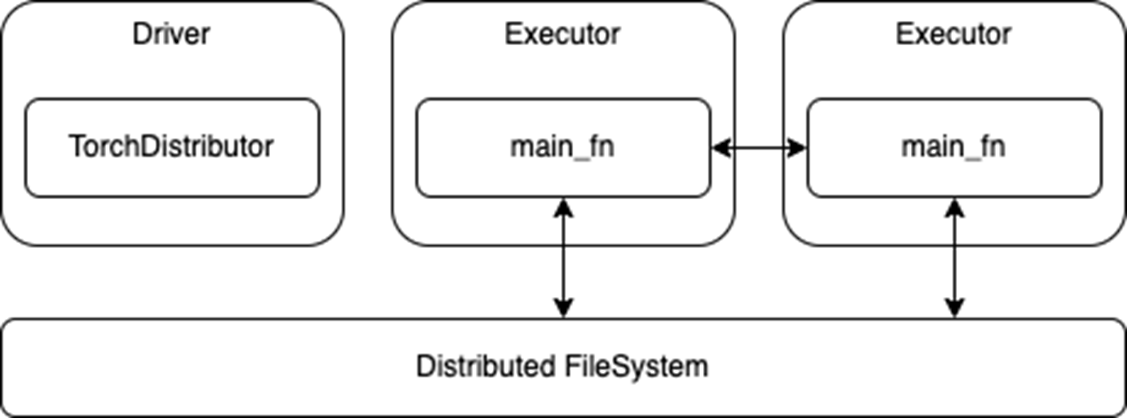 Figure 1. Distributed training using
Figure 1. Distributed training using TorchDistributor API
However, this ease of migration also means that these APIs do not use Spark RDDs or DataFrames for data transfer. While this removes any need to translate or serialize data between Spark and the DL frameworks, it also requires that any Spark preprocessing is done and persisted to storage before launching the training job. The main training functions may also need to be adapted to read from a distributed file system instead of a local store.
Distributed inference
For distributed inference, there is a new predict_batch_udf API, which builds on the Spark Pandas UDF to provide a simpler interface for DL model inference. Pandas UDFs provide several advantages over row-based UDFs, including faster serialization of data through Apache Arrow and faster vectorized operations through Pandas. For more details, see Introducing Pandas UDF for PySpark.
However, while the Pandas UDF API may be a great solution for ETL use cases, it is still not ideal for DL inference use cases. First, the Pandas UDF API presents the data as a Pandas Series or DataFrame, which again is suitable for performing ETL operations like selection, sorting, math transforms, and aggregations.
Yet most DL frameworks expect either NumPy arrays or standard Python arrays as input, and these are often wrapped by custom Tensor variables. So, at a minimum, a Pandas UDF implementation needs to translate the incoming Pandas data to NumPy arrays. Unfortunately, the exact translation can vary greatly depending on the use case and dataset.
Next, the Pandas UDF API generally operates on partitions of data whose size is determined by either the original writer of the dataset or the distributed file system. As such, it can be difficult to properly batch incoming data for optimal compute.
Finally, there is still the issue of loading the DL models across the Spark executors and tasks. In a normal Spark ETL job, the workload follows a functional programming paradigm, where stateless functions can be applied against the data. However, for DL inference, the predict function typically needs to load its DL model weights from disk.
Spark has the capability to serialize variables from the driver to the executors through task serialization and broadcast variables. However, these both rely on Python pickle serialization, which may not work for all DL models. Additionally, loading and serializing very large models can be extremely costly for performance, if not done properly.
Addressing current limitations
To solve these problems, the predict_batch_udf introduces standardized code for:
- Translating Spark DataFrames into NumPy arrays, so the end-user DL inferencing code does not need to convert from a Pandas DataFrame.
- Batching the incoming NumPy arrays for the DL frameworks.
- Model loading on the executors, which avoids any model serialization issues, while leveraging the Spark
spark.python.worker.reuseconfiguration to cache models in the Spark executors.
The code presented below demonstrates how this new API hides the complexity of translating DL inferencing code to Spark. The user simply defines a make_predict_fn function, using standard DL APIs, to load the model and return a predict function. Then, the predict_batch_udf function generates a standard PandasUDF, which takes care of everything else behind the scenes.
from pyspark.ml.functions import predict_batch_udf
def make_predict_fn():
# load model from checkpoint
import torch
device = torch.device("cuda")
model = Net().to(device)
checkpoint = load_checkpoint(checkpoint_dir)
model.load_state_dict(checkpoint['model'])
# define predict function in terms of numpy arrays
def predict(inputs: np.ndarray) -> np.ndarray:
torch_inputs = torch.from_numpy(inputs).to(device)
outputs = model(torch_inputs)
return outputs.cpu().detach().numpy()
return predict
# create standard PandasUDF from predict function
mnist = predict_batch_udf(make_predict_fn,
input_tensor_shapes=[[1,28,28]],
return_type=ArrayType(FloatType()),
batch_size=1000)
df = spark.read.parquet("/path/to/test/data")
preds = df.withColumn("preds", mnist('data')).collect()Note that this API uses the standard Spark DataFrame for inference, so the executors will read from the distributed file system and pass that data to your predict function (Figure 2). This also means that any processing of the data can be done inline with the model prediction, as needed.
Also note that this is a data-parallel architecture, where each executor loads the model and predicts on their portions of the dataset, so the model must fit in the executor memory.
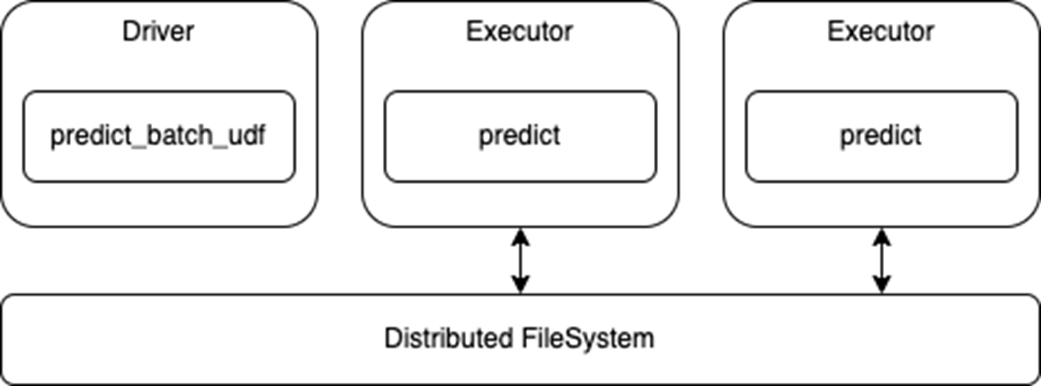 Figure 2. Distributed inference using
Figure 2. Distributed inference using predict_batch_udf API
End-to-end example for Spark deep learning
To try these new APIs, check out the Spark DL Training and Inference Notebook for an end-to-end example. Based on the Distributed Training E2E on Databricks Notebook from Databricks, the example notebook demonstrates:
- How to train a MNIST model from single-node to distributed, using the new
TorchDistributorAPI. - How to use the new
predict_batch_udfAPI for distributed inference. - How to load training data from a distributed file store, like S3, using NVTabular.
More on deep learning inference integrations
If you are working with common DL frameworks such as Hugging Face, PyTorch, and TensorFlow, check out the example notebooks for external frameworks. These examples demonstrate the ease of using the new predict_batch_udf API and its broad applicability.
Learn more about this API at the 2023 Data+AI Summit session, An API for Deep Learning Inferencing on Apache Spark.
Source:: NVIDIA