
CUDA kernel function parameters are passed to the device through constant memory and have been limited to 4,096 bytes. CUDA 12.1 increases this parameter limit…
CUDA kernel function parameters are passed to the device through constant memory and have been limited to 4,096 bytes. CUDA 12.1 increases this parameter limit from 4,096 bytes to 32,764 bytes on all device architectures including NVIDIA Volta and above.
Previously, passing kernel arguments exceeding 4,096 bytes required working around the kernel parameter limit by copying excess arguments into constant memory with cudaMemcpyToSymbol or cudaMemcpyToSymbolAsync, as shown in the snippet below.
#define TOTAL_PARAMS (8000) // ints
#define KERNEL_PARAM_LIMIT (1024) // ints
#define CONST_COPIED_PARAMS (TOTAL_PARAMS - KERNEL_PARAM_LIMIT)
__constant__ int excess_params[CONST_COPIED_PARAMS];
typedef struct {
int param[KERNEL_PARAM_LIMIT];
} param_t;
__global__ void kernelDefault(__grid_constant__ const param_t p,...) {
// access <= 4,096 parameters from p
// access excess parameters from __constant__ memory
}
int main() {
param_t p;
int *copied_params = (int*)malloc(CONST_COPIED_PARAMS * sizeof(int));
cudaMemcpyToSymbol(excess_params,
copied_params,
CONST_COPIED_PARAMS * sizeof(int),
0,
cudaMemcpyHostToDevice);
kernelDefault<<>>(p,...);
cudaDeviceSynchronize();
}
This approach limits usability because you must explicitly manage both the constant memory allocation and the copy. Copy operation also adds significant latency, degrading the performance of latency-bound kernels that accept greater than 4,096 byte parameters.
Beginning with CUDA 12.1, you can now pass up to 32,764 bytes as kernel parameters on NVIDIA Volta and above, resulting in the simplified implementation shown in the second snippet below.
#define TOTAL_PARAMS (8000) // ints
typedef struct {
int param[TOTAL_PARAMS];
} param_large_t;
__global__ void kernelLargeParam(__grid_constant__ const param_large_t p,...) {
// access all parameters from p
}
int main() {
param_large_t p_large;
kernelLargeParam<<>>(p_large,...);
cudaDeviceSynchronize();
}
Note that in both preceding examples, kernel parameters are annotated with the __grid_constant__ qualifier to indicate they are read-only.
Toolkit and driver compatibility
Note that use of CUDA Toolkit 12.1 and a R530 driver or higher are required to compile, launch, and debug kernels with large kernel parameters. CUDA will issue the CUDA_ERROR_NOT_SUPPORTED error if the launch is attempted on an older driver.
Supported architectures
The higher parameter limit is available on all architectures, including NVIDIA Volta and above. The parameter limit remains at 4,096 bytes on architectures below NVIDIA Volta.
Link compatibility across CUDA Toolkit revisions
When linking device objects, if at least one device object contains a kernel with the higher parameter limit, you must recompile all objects from your device sources, with CUDA Toolkit 12.1 linking them together. Failure to do so will result in a linker error.
As an example, consider the scenario when two device objects—a.o and b.o—are linked together. If a.o or b.o contains at least one kernel with the higher parameter limit, then you must recompile respective sources and link the resulting objects together.
Performance savings with large kernel parameters
Figure 1 compares the performance of the two code snippets (provided above) on a single NVIDIA H100 system measured over 1,000 iterations. In this example, avoiding constant copies resulted in 28% overall savings in application runtime. For the same snippets, Figure 2 shows a 9% improvement in kernel execution time, as measured with NVIDIA Nsight Systems.
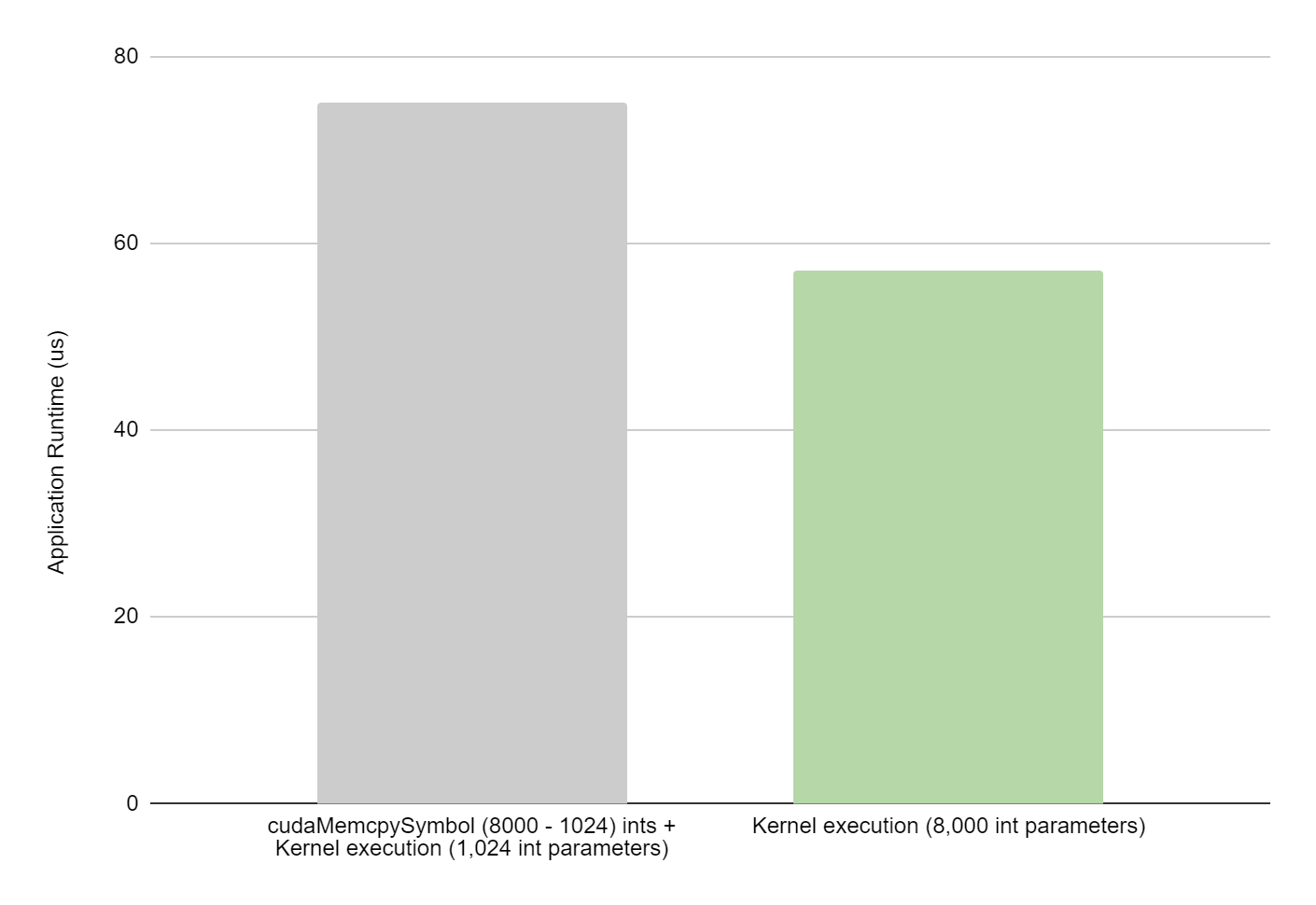 Figure 1. Application performance improvement with large kernel parameters on NVIDIA H100
Figure 1. Application performance improvement with large kernel parameters on NVIDIA H100
For both images, the gray bar shows execution time for a kernel where 1,024 integers are passed as kernel parameters and remaining integers are passed using constant memory (code snippet 1). The green bar shows execution time for a kernel where 8,000 integers are passed as kernel parameters (code snippet 2). Both kernels accumulate 8,000 integers.
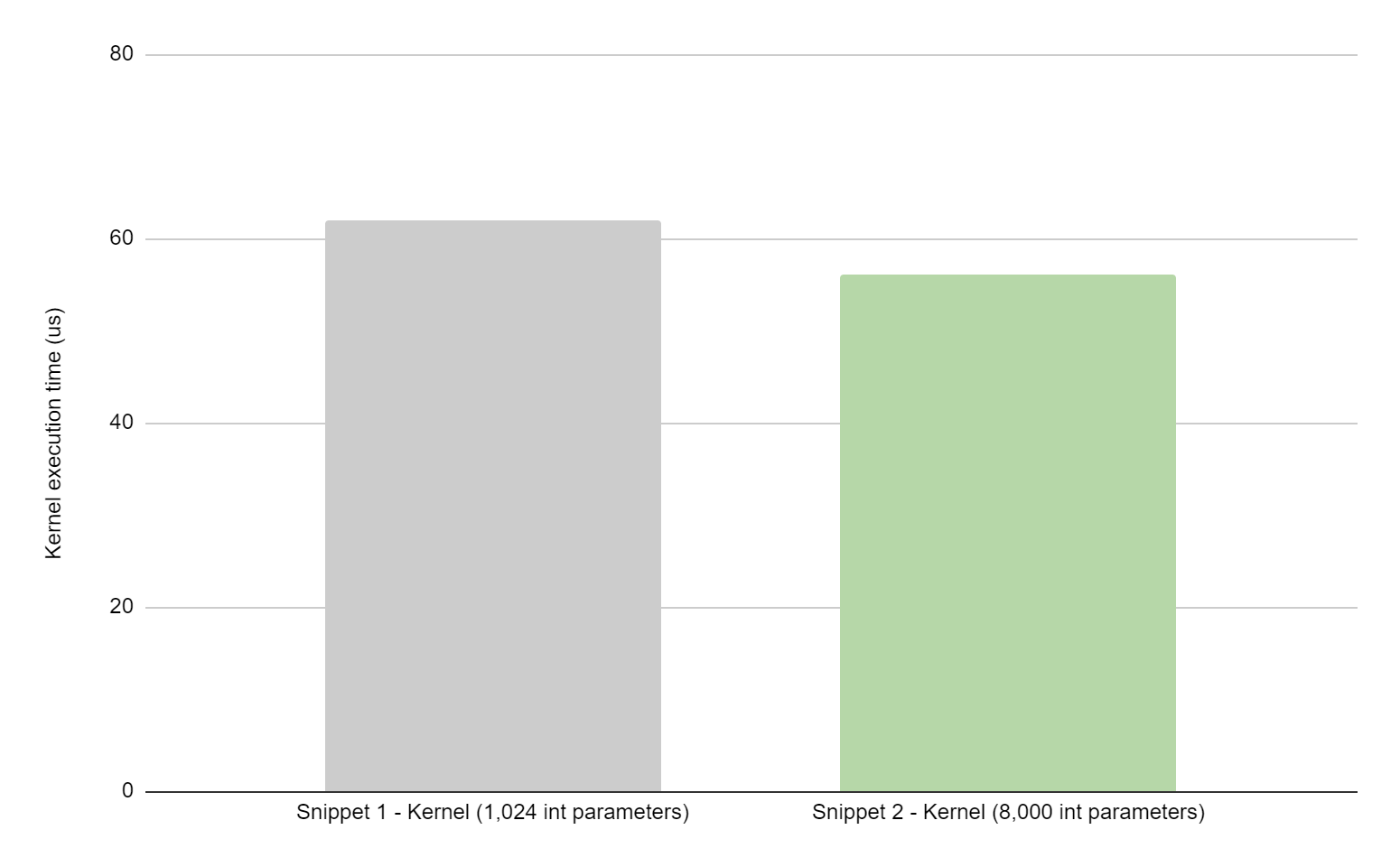 Figure 2. Kernel execution time improvement with large kernel parameters on NVIDIA H100
Figure 2. Kernel execution time improvement with large kernel parameters on NVIDIA H100
Note that if you omit the __grid_constant__ qualifier to the kernel parameter and perform a subsequent write operation to it from the kernel, an automatic copy to thread-local-memory is triggered. This may offset any performance gains.
Figure 3 shows the kernel execution time improvement profiled using Nsight Systems on QUDA. QUDA is an HPC library used for performing calculations in lattice quantum chromodynamics.
The reference kernel in this example performs a batched matrix multiply X * A + Y, where A, X, and Y are matrices. Kernel parameters store the coefficients of A. Prior to CUDA 12.1, when the coefficients exceeded the parameter limit of 4,096 bytes, they were explicitly copied over to constant memory, greatly increasing the kernel latency. With that copy removed, a significant performance improvement can be observed (Figure 3).
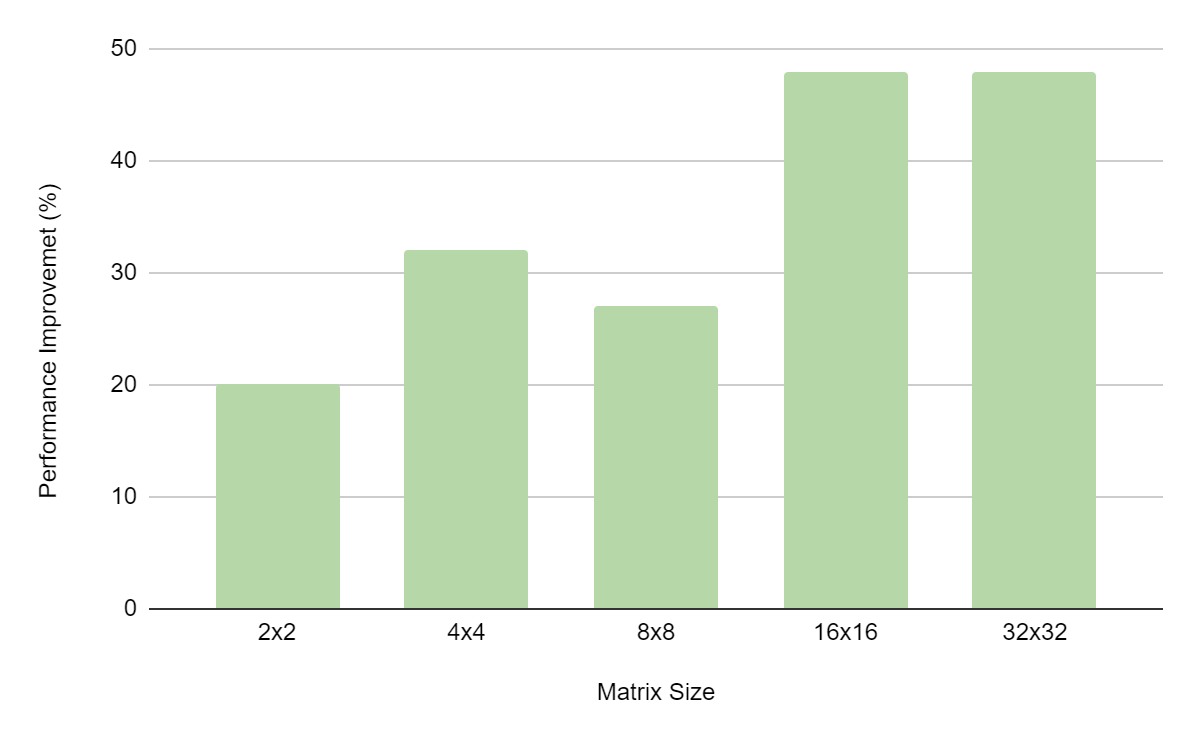 Figure 3. Kernel execution time improvement in QUDA with large kernel parameters
Figure 3. Kernel execution time improvement in QUDA with large kernel parameters
Summary
CUDA 12.1 offers you the option of passing up to 32,764 bytes using kernel parameters, which can be exploited to simplify applications as well as gain performance improvements. To see the full code sample referenced in this post, visit NVIDIA/cuda-samples on GitHub.
Source:: NVIDIA