
Real-time cloud-scale applications that involve AI-based computer vision are growing rapidly. The use cases include image understanding, content creation,…
Real-time cloud-scale applications that involve AI-based computer vision are growing rapidly. The use cases include image understanding, content creation, content moderation, mapping, recommender systems, and video conferencing.
However, the compute cost of these workloads is growing too, driven by demand for increased sophistication in the processing. The shift from still images to video is also now becoming the primary component of consumer Internet traffic. Given these trends, there is a critical need for building high-performance yet cost-effective computer vision workloads.
AI-based computer vision pipelines typically involve data pre- and post-processing steps around the AI inference model, which can be 50–80% of the entire workload. Common operators in these steps include the following:
- Resizing
- Cropping
- Normalizing
- Denoising
- Tensor conversions
While developers may use NVIDIA GPUs to significantly accelerate the AI model inference in their pipelines, pre– and post-processing are still commonly implemented with CPU-based libraries. This leads to bottlenecks in the performance of the entire AI pipeline. The decoding and encoding processes that are typically part of an AI image or video processing pipeline can also be bottlenecked on the CPU, affecting the overall performance.
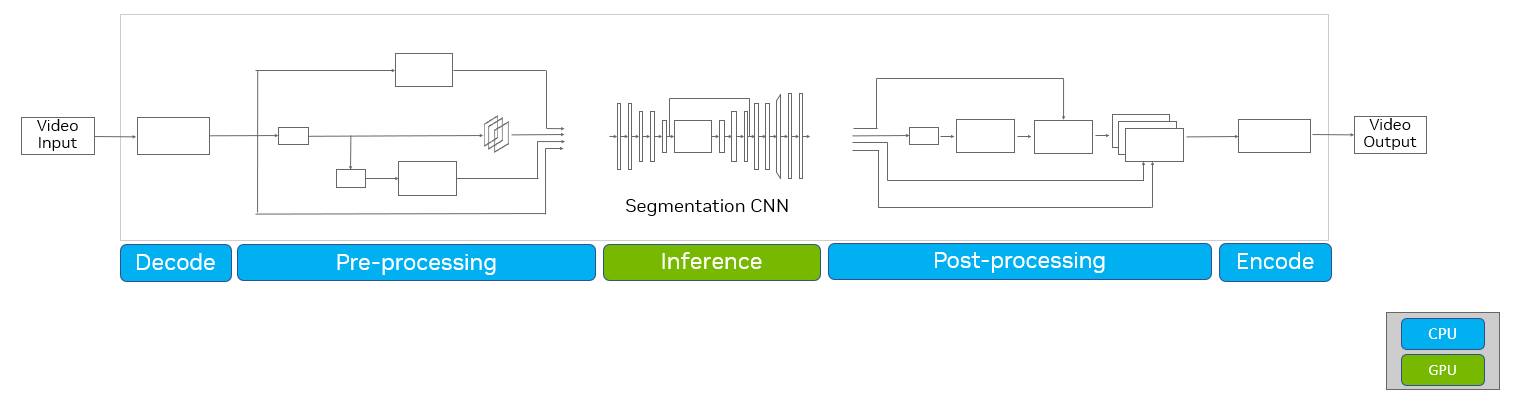 Figure 1. Conventional workflow for AI computer vision pipeline
Figure 1. Conventional workflow for AI computer vision pipeline
CV-CUDA optimization
CV-CUDA is an open-source library that enables you to build efficient cloud-scale AI computer vision pipelines. The library provides a specialized set of GPU-accelerated computer vision and image-processing kernels as standalone operators to easily implement highly efficient pre- and post-processing steps of the AI pipeline.
CV-CUDA can be used in a variety of common computer vision pipelines, such as image classification, object detection, segmentation, and image generation. For more information, see the keynote announcement at NVIDIA GTC Fall 2022.
In this post, we demonstrate the benefit of using CV-CUDA to enable end-to-end GPU acceleration for a typical AI computer vision workload achieving ~5x to up to 50x speedup in overall throughput. This can result in significant annual cloud cost savings on the order of hundreds of millions of USD, and hundreds of GWh of annual savings in energy consumption in data centers.
CPU bottlenecks addressed by GPU acceleration
CV-CUDA provides highly optimized, GPU-accelerated kernels as standalone operators for computer vision processing. These kernels can efficiently implement pre- and post-processing pipelines, resulting in significant throughput improvements.
Encode and decode operations can also be potential bottlenecks in the pipeline. With the optimized NVIDIA Video Processing Framework (VPF), you can efficiently optimize and run them as well. VPF is an open-source library from NVIDIA with Python bindings to C++ libraries. It provides full hardware acceleration for video decoding and encoding on GPUs.
To accelerate the entire end-to-end AI pipeline on the GPU (Figure 2), use CV-CUDA, along with VPF for decoding/encoding acceleration and TensorRT for further inference optimization. You can enable up to 50x end-to-end throughput improvement with four NVIDIA L4 GPUs, compared to CPU-based implementations in a typical pipeline.
The degree of improvement depends on factors such as the complexity of the inference DNN, the pre– and post-processing steps required, and the hardware. With multi-GPU nodes, you can expect the speedup factors to scale linearly for a given pipeline.
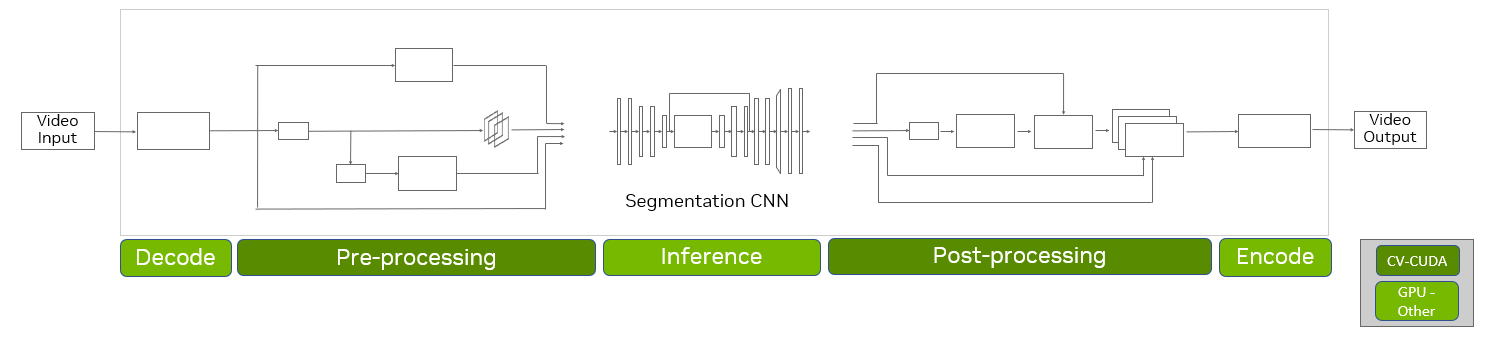 Figure 2. GPU-accelerated AI pipeline with CV-CUDA for pre- and post-processing operations.
Figure 2. GPU-accelerated AI pipeline with CV-CUDA for pre- and post-processing operations.
How CV-CUDA achieves high performance
CV-CUDA uses the power of GPU to achieve high performance:
- Pre-allocated memory pooling to avoid duplicate allocation of GPU memory in the inference stage
- Asynchronous operations
- Kernel fusion-implementing combinations of operators using one GPU kernel to minimize unnecessary data transfer and kernel launch latency
- Memory access efficiency by vectorizing global memory access and using fast shared memory
- Computation efficiency, fast math, warp reduce/block reduction
Case study: End-to-end acceleration of a video-segmentation pipeline
Video-based segmentation is a common AI technique that segments pixels in a video frame based on their attributes. For example, in a virtual background or background blurring applications in video conferencing, it segments the foreground person or object and the background.
In this study, we discuss the performance evaluation of an AI video-segmentation pipeline deployed in the cloud using the NVIDIA T4 Tensor Core GPU instance on AWS, with a specific focus on compute cost optimization. The CPU attached to the instance is Intel Xeon Platinum 8362.
When the entire end-to-end AI pipeline is executed on GPU, you can anticipate significant cost savings. We then discuss the impact of this throughput performance speedup of the same workload on data-center energy consumption.
To conduct the experiment, we compared the GPU with CV-CUDA AI pipeline with the CPU with OpenCV implementation of the same pipeline, assuming that the inference workload in both cases runs on the GPU. Specifically, we deployed a ResNet-101 video-segmentation model pipeline (Figure 3), to perform AI background blurring.
Figure 3. Example of a common end-to-end video-segmentation pipeline. The foreground object is segmented in the input frame using AI and then composited with the original input frame and blurred version for background blurring.
In this case, we measured the latency for different stages and maximum throughput across the entire end-to-end pipeline. The pipeline encompasses multiple stages ((Figure 4):
- Video decoding
- Preprocessing using operations like Downscale, Normalize, and Reformat
- Inference using PyTorch
- Post-processing using operations like Reformat, Upscale, BilateralFilter, Composition, and Blur
- Video encoding
For both the CPU and GPU pipelines, we assumed that the inference workload ran on the GPU using PyTorch and TensorRT, respectively.
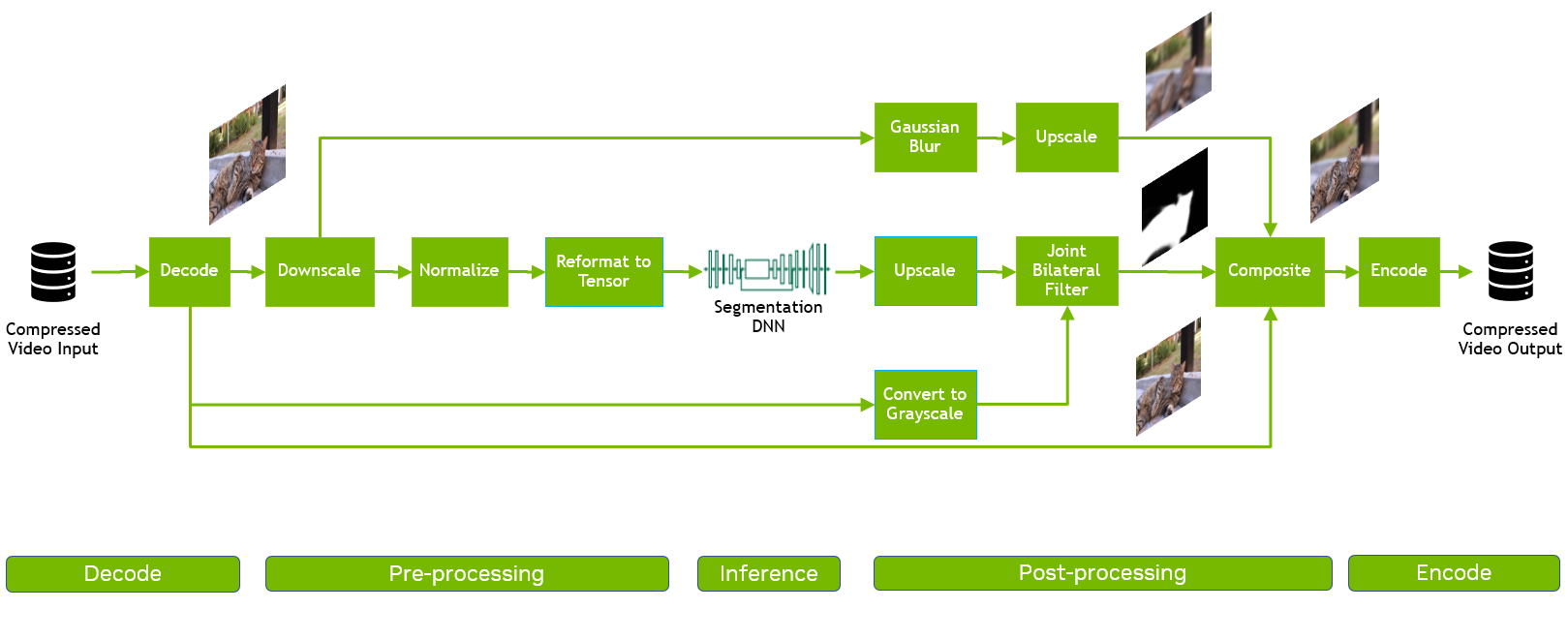 Figure 4. AI background blur pipeline with CV-CUDA operators for pre- and post-processing.
Figure 4. AI background blur pipeline with CV-CUDA operators for pre- and post-processing.
The conventional pipeline was built with OpenCV and PyTorch (GPU), implemented in Python, as this is a typical pattern for customers. The input video has a resolution of 1080p and consists of 474 frames with a batch size of 1. In this pipeline, the GPU is only used for inference, thanks to PyTorch, while the rest of the process is CPU-based:
- The frames are decoded using OpenCV/ffmpeg.
- The decoded images are pre-processed using OpenCV and fed into a PyTorch-powered DNN to detect which pixels belong to a cat, generating a mask.
- In the post-processing stage, the output mask of the previous stage is composited with the original image and its blurred version resulting in the cat in the foreground and the background blurred.
For the GPU-based pipeline (Figure 4), we implemented the pre– and post-processing stages with optimized operators from CV-CUDA library, and the inference using the NVIDIA TensorRT library. We also accelerated the decoding and encoding parts of the pipeline on GPU using VPF.
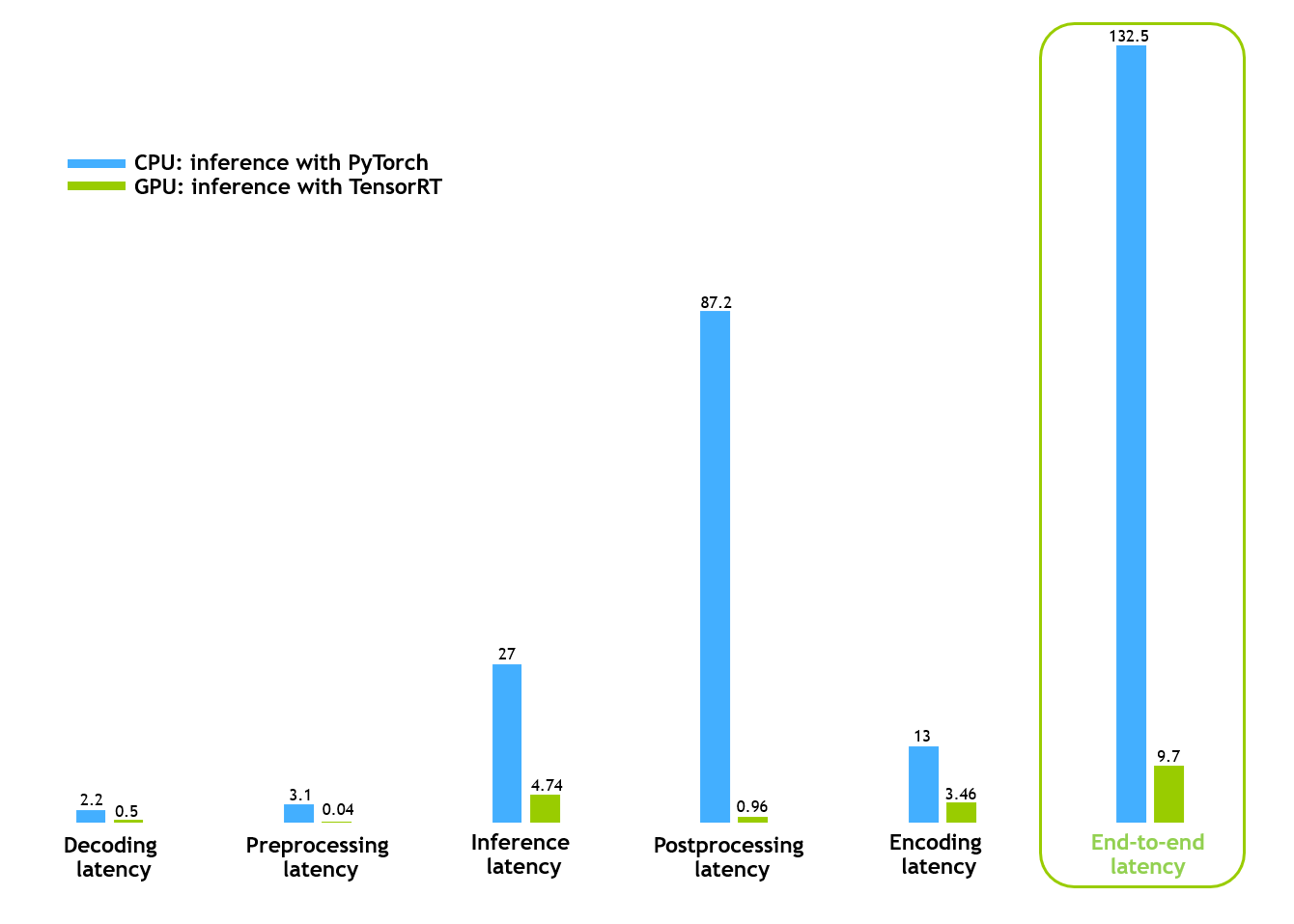 Figure 5. Latency (ms) comparison between CPU- and GPU-based pipelines. (GPU=NVIDIA T4; CPU=Intel Xeon Platinum 8362; batch size=1; # processes=1)
Figure 5. Latency (ms) comparison between CPU- and GPU-based pipelines. (GPU=NVIDIA T4; CPU=Intel Xeon Platinum 8362; batch size=1; # processes=1)
Figure 5 shows that the end-to-end time for a one-frame batch was reduced from 132 ms to approximately 10 ms, demonstrating the impressive latency reduction achieved by the GPU pipeline. By employing a single NVIDIA T4 GPU, the CV-CUDA pipeline was ~13x faster compared to the CPU pipeline.
This result was obtained for a single process working on a single video. By deploying multiple processes to handle multiple videos concurrently, these optimizations enable higher throughput with the same hardware, resulting in significant cost and energy savings.
To better demonstrate the benefits that CV-CUDA delivers, we executed the GPU pipeline on different instances (one T4 GPU, one L4 GPU, four T4 GPUs, and four L4 GPUs).
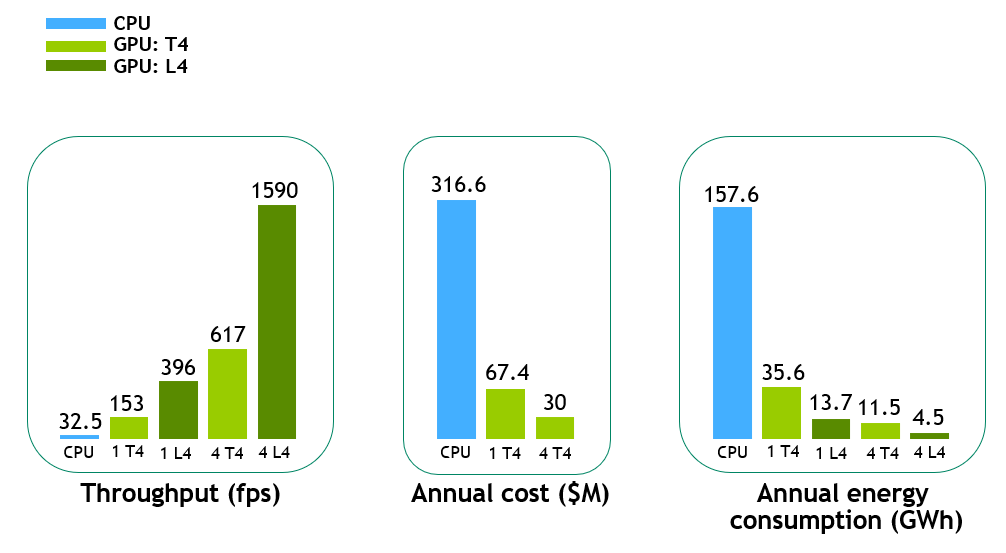 Figure 6. Relative comparison of end-to-end throughput performance, annual compute cost, and energy consumption of a GPU pipeline executed on different single and multi-GPU servers with the CPU pipeline on a CPU server
Figure 6. Relative comparison of end-to-end throughput performance, annual compute cost, and energy consumption of a GPU pipeline executed on different single and multi-GPU servers with the CPU pipeline on a CPU server
The newly introduced NVIDIA L4 Tensor Core GPU, powered by the NVIDIA Ada Lovelace architecture, delivers low-cost, energy-efficient acceleration for video, AI, visual computing, graphics, and virtualization.
In Figure 6, the end-to-end throughput speedup on a single T4 GPU is ~5x compared to the CPU baseline, and the speedup is further improved on the new L4 GPU to ~12x. With multiple GPU instances, the performance almost scales linearly, for instance, ~19x and ~48x on four T4 GPUs and four L4 GPUs, respectively.
For computing annual cloud cost and energy consumption, we assumed a typical video workload of 500 video hours uploaded every minute to a video streaming platform. For the annual cloud cost, we only took T4 GPUs into consideration (L4 GPUs will be available in the future) and assumed one-year reserved pricing on Amazon EC2 G4 Instances.
Given this, the annual cost for this example video workload on a single T4 GPU would be ~1/5th of the CPU pipeline. This predicts typical cloud cost-saving estimates on the order of hundreds of millions of USD for such a workload.
For data centers, in addition to the costs associated with the hardware required to handle such huge workloads, energy efficiency is critical to lower energy costs and environmental impact.
In Figure 6 (right), the annual energy consumption (in GWh) is computed for the same video workload on a server with the respective hardware based on their average hourly power consumption. The energy consumption on a single L4 system is about ~1/12th of the CPU server. For a workload like the example video (500 hrs of video per minute), the annual energy savings estimates are on the order of hundreds of GWh.
These energy savings are significant as this is equivalent to avoiding greenhouse gas emissions from tens of thousands of passenger vehicles driven in a year, each driving ~11K miles per year.
CV-CUDA Beta v0.3.0 features
Now that you have seen the benefits of using CV-CUDA to accelerate AI computer vision workloads, here are some of the key features:
- Open source: Apache 2.0 licensed open-source software on GitHub.
- Supported operators: CV-CUDA provides 30+ specialized operators commonly used in the pre- and post-processing steps of AI computer vision workloads. These stateless, standalone operators are easily plugged in to existing custom processing frameworks. The common operators include ConvertTo, Custom crop, Normalize, PadStack, Reformat, and Resize. For more information, see the full list in the CV-CUDA Developer Guide.
- New operators: CV-CUDA Beta v0.3.0 provides new operators like Remap, Find Contours, Non-Max Suppression, Thresholding, and Adaptive Thresholding.
- Custom backend for NVIDIA Triton: You can now integrate CV-CUDA into a custom backend when building computer vision pipelines, with a sample application.
- Multiple language APIs: CV-CUDA includes APIs for C/C++, and Python.
- Framework interfaces: Easy-to-use and zero-copy interfaces to existing DL frameworks such as PyTorch and TensorFlow.
- Batch support: All CV-CUDA operators are supported, so that you can achieve higher GPU utilization and better performance.
- Uniform and variable shape batch support: CV-CUDA accepts tensors that have the same or different dimensions.
- Sample applications: End-to-end accelerated image classification, object detection, and video segmentation sample applications.
- Single-line PIP installation.
- Installation, getting started, and API reference guides.
CV-CUDA is available for download
The open beta release (v0.3.0) of CV-CUDA is now available on GitHub.
CV-CUDA enables accelerating complex AI computer vision workloads in the cloud using optimized image and video processing kernels. The Python-friendly library can be easily integrated into existing pipelines with zero-copy interfaces to common deep learning frameworks like PyTorch and TensorFlow.
CV-CUDA, along with VPF and TensorRT, further optimizes the end-end AI workloads to achieve significant cost and energy savings. This makes it suitable for cloud-scale use cases:
- Video content creation and enhancement
- Image understanding
- Recommender systems
- Mapping
- Video conferencing
For more information, see the following resources:
- CV-CUDA documentation
- NVIDIA Announces Microsoft, Tencent, Baidu Adopting CV-CUDA for Computer Vision AI
- Runway Optimizes AI Image and Video Generation Tools Using CV-CUDA (video)
- Overcome Pre- and Post-Processing Bottlenecks in AI-Based Imaging and Computer Vision Pipelines with CV-CUDA (video, free registration required)
- Build AI-Based HD Maps for Autonomous Vehicles (video, free registration required)
- Advance AI Applications with Custom GPU-Powered Plugins for NVIDIA DeepStream (video, free registration required)
- FastDeploy: Full-Scene, High-Performance AI Deployment Tool (Presented by Baidu) (video, free registration required)
- Accelerate Modern Video Applications in the Cloud using Video Codec SDK, CV-CUDA, and TensorRT on GPU (video in Mandarin, free registration required)
Using or considering CV-CUDA? Engage the product team for support. We’d love to hear from you.
Source:: NVIDIA