We’re not going to bury the lede: we’re excited to launch a major update to our D1 database, with dramatic improvements to performance and scalability. Alpha users (which includes any Workers user) can create new databases using the new storage backend right now with the following command:
$ wrangler d1 create your-database --experimental-backend
In the coming weeks, it’ll be the default experience for everyone, but we want to invite developers to start experimenting with the new version of D1 immediately. We’ll also be sharing more about how we built D1’s new storage subsystem, and how it benefits from Cloudflare’s distributed network, very soon.
Remind me: What’s D1?
D1 is Cloudflare’s native serverless database, which we launched into alpha in November last year. Developers have been building complex applications with Workers, KV, Durable Objects, and more recently, Queues & R2, but they’ve also been consistently asking us for one thing: a database they can query.
We also heard consistent feedback that it should be SQL-based, scale-to-zero, and (just like Workers itself), take a Region: Earth approach to replication. And so we took that feedback and set out to build D1, with SQLite giving us a familiar SQL dialect, robust query engine and one of the most battle tested code-bases to build on.
We shipped the first version of D1 as a “real” alpha: a way for us to develop in the open, gather feedback directly from developers, and better prioritize what matters. And living up to the alpha moniker, there were bugs, performance issues and a fairly narrow “happy path”.
Despite that, we’ve seen developers spin up thousands of databases, make billions of queries, popular ORMs like Drizzle and Kysley add support for D1 (already!), and Remix and Nuxt templates build directly around it, as well.
Turning it up to 11
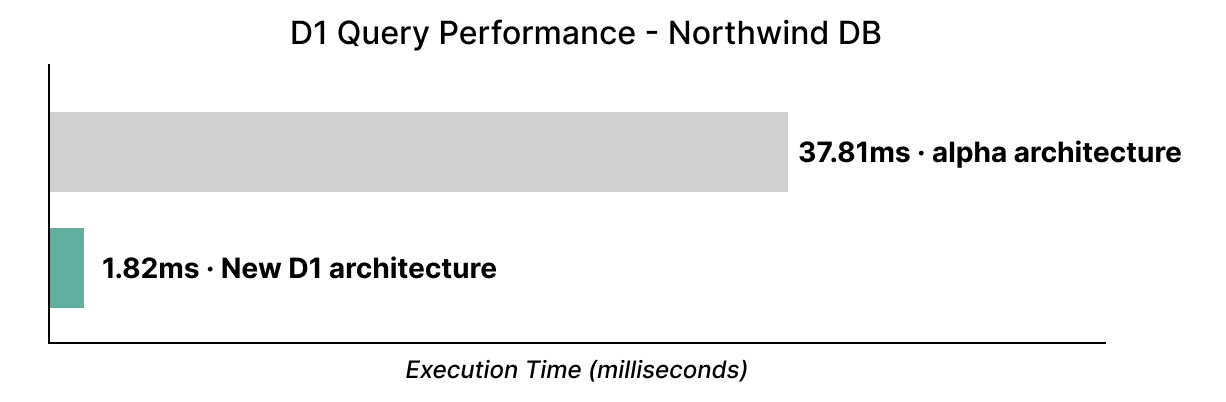
If you’ve used D1 in its alpha state to date: forget everything you know. D1 is now substantially faster: up to 37x faster on the well-known Northwind Traders Demo, which we’ve just migrated to use our new storage backend:
Our new architecture also increases write performance: a simple benchmark inserting 1,000 rows (each row about 200 bytes wide) is approximately 6.8x faster than the previous version of D1.
Larger batches (10,000 rows at ~200 bytes wide) see an even larger improvement: between 10-11x, with the new storage backend’s latency also being significantly more consistent. We’ve also not yet started to optimize our overall write throughput, and so expect D1 to only get faster here.
With our new storage backend, we also want to make clear that D1 is not a toy, and we’re constantly benchmarking our performance against other serverless databases. A query against a 500,000 row key-value table (recognizing that benchmarks are inherently synthetic) sees D1 perform about 3.2x faster than a popular serverless Postgres provider:
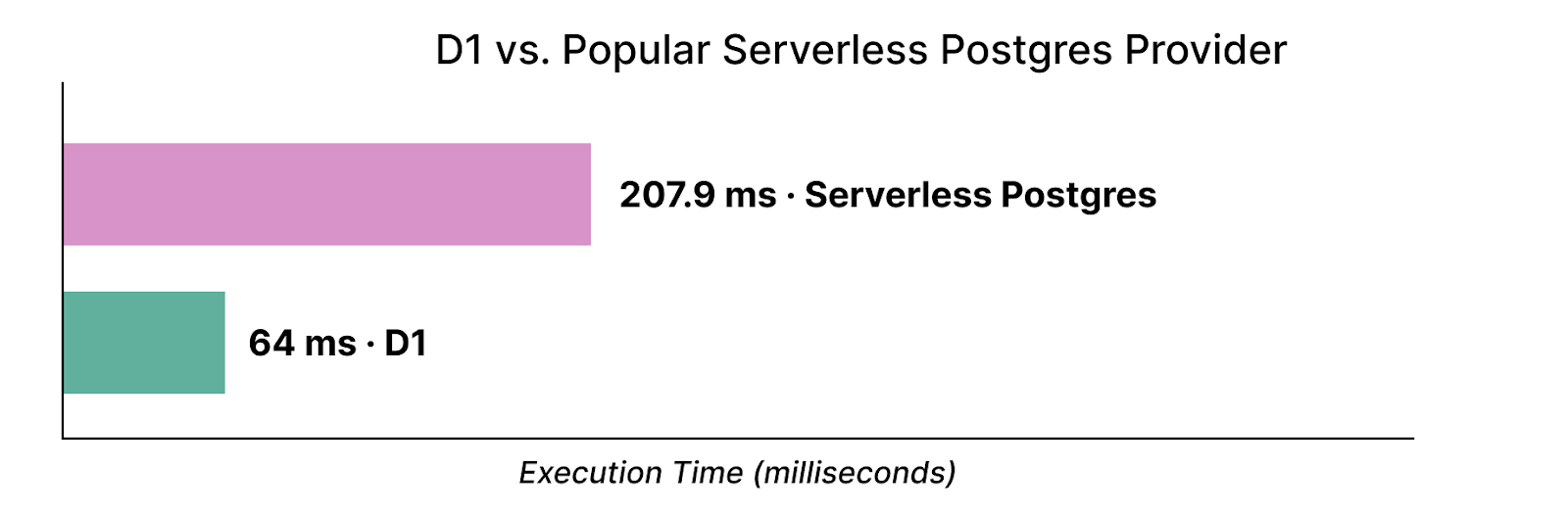
We ran the Postgres queries several times to prime the page cache and then took the median query time, as measured by the server. We’ll continue to sharpen our performance edge as we go forward.
Developers with existing databases can import data into a new database backed by the storage engine by following the steps to export their database and then import it in our docs.
What did I miss?
We’ve also been working on a number of improvements to D1’s developer experience:
- A new console interface that allows you to issue queries directly from the dashboard, making it easier to get started and/or issue one-shot queries.
- Formal support for JSON functions that query over JSON directly in your database.
- Location Hints, allowing you to influence where your leader (which is responsible for writes) is located globally.
Although D1 is designed to work natively within Cloudflare Workers, we realize that there’s often a need to quickly issue one-shot queries via CLI or a web editor when prototyping or just exploring a database. On top of the support in wrangler for executing queries (and files), we’ve also introduced a console editor that allows you to issue queries, inspect tables, and even edit data on the fly:
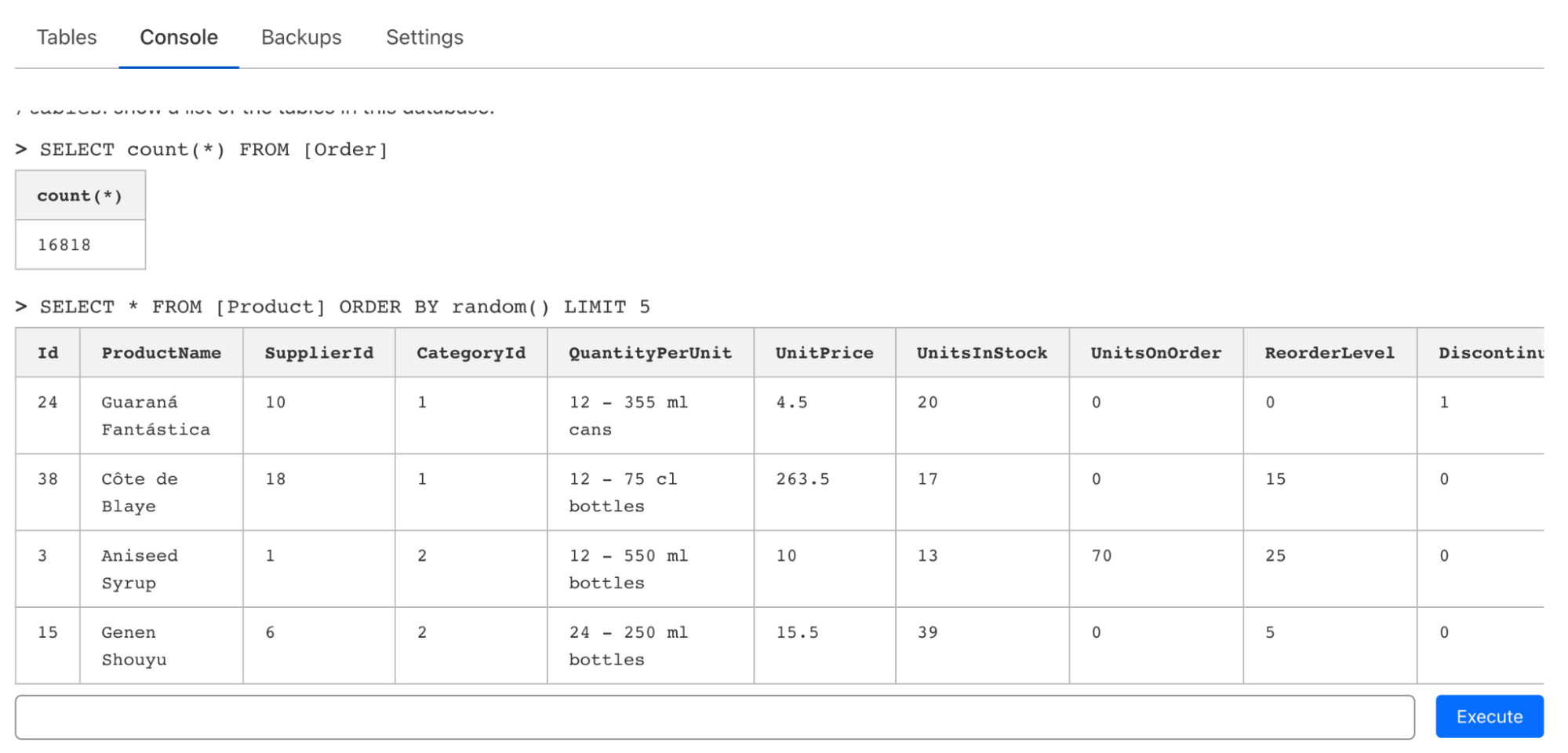
JSON functions allow you to query JSON stored in TEXT columns in D1: allowing you to be flexible about what data is associated strictly with your relational database schema and what isn’t, whilst still being able to query all of it via SQL (before it reaches your app).
For example, suppose you store the last login timestamps as a JSON array in a login_history TEXT column: I can query (and extract) sub-objects or array items directly by providing a path to their key:
SELECT user_id, json_extract(login_history, '$.[0]') as latest_login FROM users
D1’s support for JSON functions is extremely flexible, and leverages the SQLite core that D1 builds on.
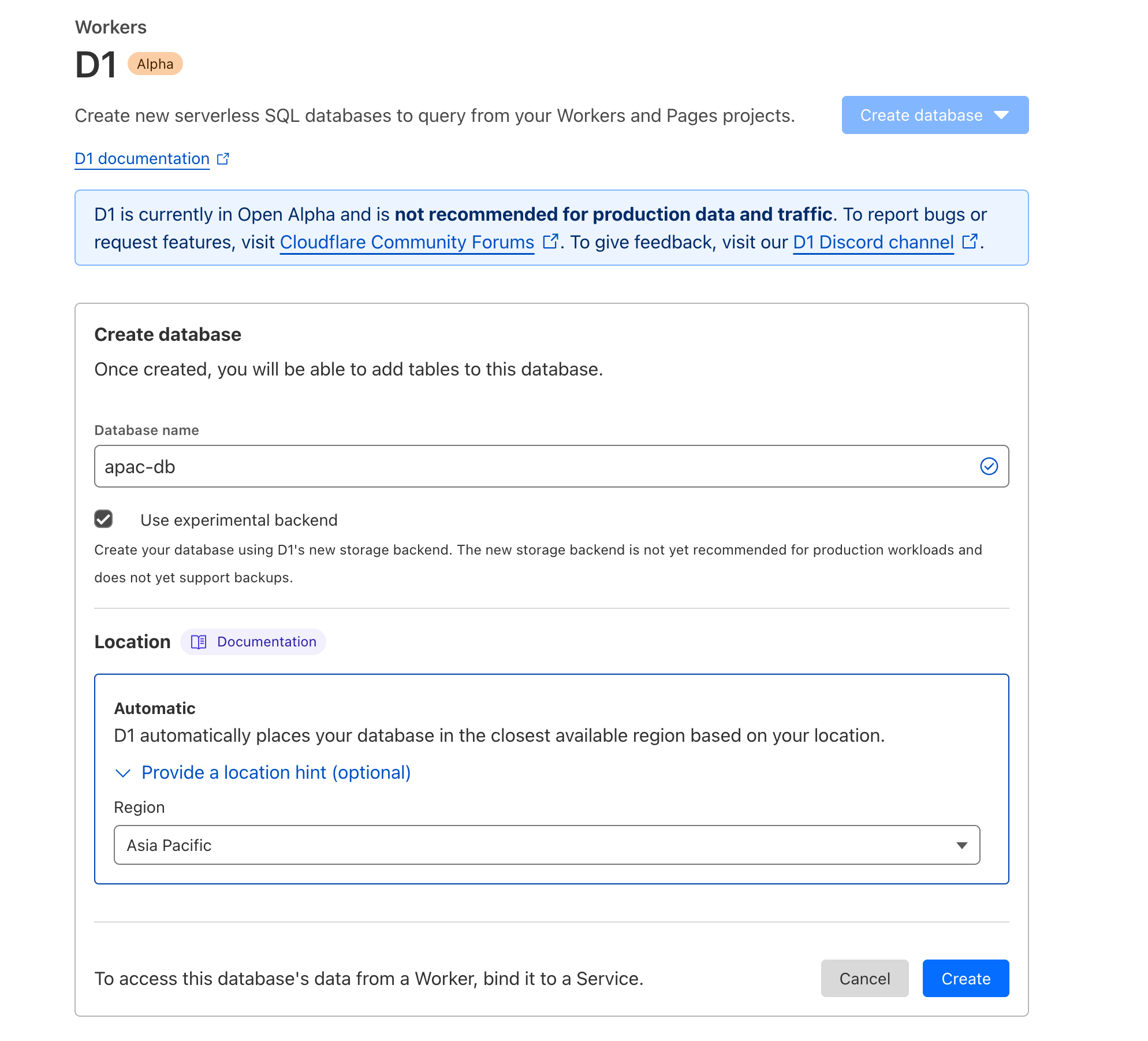
When you create a database for the first time with D1, we automatically infer the location based on where you’re currently connecting from. There are some cases, however, where you might want to influence that — maybe you’re traveling, or you have a distributed team that’s distinct from the region you expect the majority of your writes to come from.
D1’s support for Location Hints makes that easy:
# Automatically inferred based your location
$ wrangler d1 create user-prod-db --experimental-backend
# Indicate a preferred location to create your database
$ wrangler d1 create eu-users-db --location=weur --experimental-backend
Location Hints are also now available in the Cloudflare dashboard:
We’ve also published more documentation to help developers not only get started, but make use of D1’s advanced features. Expect D1’s documentation to continue to grow substantially over the coming months.
Not going to burn a hole in your wallet
We’ve had many, many developers ask us about how we’ll be pricing D1 since we announced the alpha, and we’re ready to share what it’s going to look like. We know it’s important to understand what something might cost before you start building on it, so you’re not surprised six months later.
In a nutshell:
- We’re announcing pricing so that you can start to model how much D1 will cost for your use-case ahead of time. Final pricing may be subject to change, although we expect changes to be relatively minor.
- We won’t be enabling billing until later this year, and we’ll notify existing D1 users via email ahead of that change. Until then, D1 will remain free to use.
- D1 will include an always-free tier, included usage as part of our $5/mo Workers subscription, and charge based on reads, writes and storage.
If you’re already subscribed to Workers, then you don’t have to lift a finger: your existing subscription will have D1 usage included when we enable billing in the future.
Here’s a summary (we’re keeping it intentionally simple):

Importantly, when we enable global read replication, you won’t have to pay extra for it, nor will replication multiply your storage consumption. We think built-in, automatic replication is important, and we don’t think developers should have to pay multiplicative costs (replicas x storage fees) in order to make their database fast everywhere.
Beyond that, we wanted to ensure D1 took the best parts of serverless pricing — scale-to-zero and pay-for-what-you-use — so that you’re not trying to figure out how many CPUs and/or how much memory you need for your workload or writing scripts to scale down your infrastructure during quieter hours.
D1’s read pricing is based on the familiar concept of a read unit (per 4KB read), and a write unit (per 1KB written). A query that reads (scans) ~10,000 rows of 64 bytes each would consume 160 read units. Write a big 3KB row in a “blog_posts” table that has a lot of Markdown, and that’s three write units. And if you create indexes for your most popular queries to improve performance and reduce how much data those queries need to scan, you’ll also reduce how much we bill you. We think making the fast path more cost-efficient by default is the right approach.
Importantly: we’ll continue to take feedback on our pricing before we flip the switch.
Time Travel
We’re also introducing new backup functionality: point-in-time-recovery, and we’re calling this Time Travel, because it feels just like it. Time Travel allows you to restore your D1 database to any minute within the last 30 days, and will be built into D1 databases using our new storage system. We expect to turn on Time Travel for new D1 databases in the very near future.
What makes Time Travel really powerful is that you no longer need to panic and wonder “oh wait, did I take a backup before I made this major change?!” — because we do it for you. We retain a stream of all changes to your database (the Write-Ahead Log), allowing us to restore your database to a point in time by replaying those changes in sequence up until that point.
Here’s an example (subject to some minor API changes):
# Using a precise Unix timestamp (in UTC):
$ wrangler d1 time-travel my-database --before-timestamp=1683570504
# Alternatively, restore prior to a specific transaction ID:
$ wrangler d1 time-travel my-database --before-tx-id=01H0FM2XHKACETEFQK2P5T6BWD
And although the idea of point-in-time recovery is not new, it’s often a paid add-on, if it is even available at all. Realizing you should have had it turned on after you’ve deleted or otherwise made a mistake means it’s often too late.
For example, imagine if I made the classic mistake of forgetting a WHERE on an UPDATE statement:
-- Don't do this at home
UPDATE users SET email = '[email protected]' -- missing: WHERE id = "abc123"
Without Time Travel, I’d have to hope that either a scheduled backup ran recently, or that I remembered to make a manual backup just prior. With Time Travel, I can restore to a point a minute or so before that mistake (and hopefully learn a lesson for next time).
We’re also exploring features that can surface larger changes to your database state, including making it easier to identify schema changes, the number of tables, large deltas in data stored and even specific queries (via transaction IDs) — to help you better understand exactly what point in time to restore your database to.
On the roadmap
So what’s next for D1?
- Open beta: we’re ensuring we’ve observed our new storage subsystem under load (and real-world usage) prior to making it the default for all `d1 create` commands. We hold a high bar for durability and availability, even for a “beta”, and we also recognize that access to backups (Time Travel) is important for folks to trust a new database. Keep an eye on the Cloudflare blog in the coming weeks for more news here!
- Bigger databases: we know this is a big ask from many, and we’re extremely close. Developers on the Workers Paid plan will get access to 1GB databases in the very near future, and we’ll be continuing to ramp up the maximum per-database size over time.
- Metrics & observability: you’ll be able to inspect overall query volume by database, failing queries, storage consumed and read/write units via both the D1 dashboard and our GraphQL API, so that it’s easier to debug issues and track spend.
- Automatic read replication: our new storage subsystem is built with replication in mind, and we’re working on ensuring our replication layer is both fast & reliable before we roll it out to developers. Read replication is not only designed to improve query latency by storing copies — replicas — of your data in multiple locations, close to your users, but will also allow us to scale out D1 databases horizontally for those with larger workloads.
In the meantime, you can start prototyping and experimenting with D1 right now, explore our D1 + Drizzle + Remix example project, or join the #d1 channel on the Cloudflare Developers Discord server to engage directly with the D1 team and others building on D1.
Source:: CloudFlare