Building the large language models (LLMs) and diffusion models that power generative AI requires massive infrastructure. The most obvious component is compute – hundreds to thousands of GPUs – but an equally critical (and often overlooked) component is the data storage infrastructure. Training datasets can be terabytes to petabytes in size, and this data needs to be read in parallel by thousands of processes. In addition, model checkpoints need to be saved frequently throughout a training run, and for LLMs these checkpoints can each be hundreds of gigabytes!
To manage storage costs and scalability, many machine learning teams have been moving to object storage to host their datasets and checkpoints. Unfortunately, most object store providers use egress fees to “lock in” users to their platform. This makes it very difficult to leverage GPU capacity across multiple cloud providers, or take advantage of lower / dynamic pricing elsewhere, since the data and model checkpoints are too expensive to move. At a time when cloud GPUs are scarce, and new hardware options are entering the market, it’s more important than ever to stay flexible.
In addition to high egress fees, there is a technical barrier to object-store-centric machine learning training. Reading and writing data between object storage and compute clusters requires high throughput, efficient use of network bandwidth, determinism, and elasticity (the ability to train on different #s of GPUs). Building training software to handle all of this correctly and reliably is hard!
Today, we’re excited to show how MosaicML’s tools and Cloudflare R2 can be used together to address these challenges. First, with MosaicML’s open source StreamingDataset and Composer libraries, you can easily stream in training data and read/write model checkpoints back to R2. All you need is an Internet connection. Second, thanks to R2’s zero-egress pricing, you can start/stop/move/resize jobs in response to GPU availability and prices across compute providers, without paying any data transfer fees. The MosaicML training platform makes it dead simple to orchestrate such training jobs across multiple clouds.
Together, Cloudflare and MosaicML give you the freedom to train LLMs on any compute, anywhere in the world, with zero switching costs. That means faster, cheaper training runs, and no vendor lock in 🙂
“With the MosaicML training platform, customers can efficiently use R2 as the durable storage backend for training LLMs on any compute provider with zero egress fees. AI companies are facing outrageous cloud costs, and they are on the hunt for the tools that can provide them with the speed and flexibility to train their best model at the best price.” – Naveen Rao, CEO and co-founder, MosaicML
Reading data from R2 using StreamingDataset
To read data from R2 efficiently and deterministically, you can use the MosaicML StreamingDataset library. First, write your training data (images, text, video, anything!) into .mds shard files using the provided Python API:
import numpy as np
from PIL import Image
from streaming import MDSWriter
# Local or remote directory in which to store the compressed output files
data_dir = 'path-to-dataset'
# A dictionary mapping input fields to their data types
columns = {
'image': 'jpeg',
'class': 'int'
}
# Shard compression, if any
compression = 'zstd'
# Save the samples as shards using MDSWriter
with MDSWriter(out=data_dir, columns=columns, compression=compression) as out:
for i in range(10000):
sample = {
'image': Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)),
'class': np.random.randint(10),
}
out.write(sample)
After your dataset has been converted, you can upload it to R2. Below we demonstrate this with the awscli command line tool, but you can also use `wrangler `or any S3-compatible tool of your choice. StreamingDataset will also support direct cloud writing to R2 soon!
$ aws s3 cp --recursive path-to-dataset s3://my-bucket/folder --endpoint-url $S3_ENDPOINT_URL
Finally, you can read the data into any device that has read access to your R2 bucket. You can fetch individual samples, loop over the dataset, and feed it into a standard PyTorch dataloader.
from torch.utils.data import DataLoader
from streaming import StreamingDataset
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
# Remote path where full dataset is persistently stored
remote = 's3://my-bucket/folder'
# Local working dir where dataset is cached during operation
local = '/tmp/path-to-dataset'
# Create streaming dataset
dataset = StreamingDataset(local=local, remote=remote, shuffle=True)
# Let's see what is in sample #1337...
sample = dataset[1337]
img = sample['image']
cls = sample['class']
# Create PyTorch DataLoader
dataloader = DataLoader(dataset)
StreamingDataset comes out of the box with high performance, elastic determinism, fast resumption, and multi-worker support. It also uses smart shuffling and distribution to ensure that download bandwidth is minimized. Across a variety of workloads such as LLMs and diffusion models, we find that there is no impact on training throughput (no dataloader bottleneck) when training from object stores like R2. For more information, check out the StreamingDataset announcement blog!
Reading/writing model checkpoints to R2 using Composer
Streaming data into your training loop solves half of the problem, but how do you load/save your model checkpoints? Luckily, if you use a training library like Composer, it’s as easy as pointing at an R2 path!
from composer import Trainer
...
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
trainer = Trainer(
run_name='mpt-7b',
model=model,
train_dataloader=train_loader,
...
save_folder=s3://my-bucket/mpt-7b/checkpoints,
save_interval='1000ba',
# load_path=s3://my-bucket/mpt-7b-prev/checkpoints/ep0-ba100-rank0.pt,
)
Composer uses asynchronous uploads to minimize wait time as checkpoints are being saved during training. It also works out of the box with multi-GPU and multi-node training, and does not require a shared file system. This means you can skip setting up an expensive EFS/NFS system for your compute cluster, saving thousands of dollars or more per month on public clouds. All you need is an Internet connection and appropriate credentials – your checkpoints arrive safely in your R2 bucket giving you scalable and secure storage for your private models.
Using MosaicML and R2 to train anywhere efficiently
Using the above tools together with Cloudflare R2 enables users to run training workloads on any compute provider, with total freedom and zero switching costs.
As a demonstration, in Figure X we use the MosaicML training platform to launch an LLM training job starting on Oracle Cloud Infrastructure, with data streaming in and checkpoints uploaded back to R2. Part way through, we pause the job and seamlessly resume on a different set of GPUs on Amazon Web Services. Composer loads the model weights from the last saved checkpoint in R2, and the streaming dataloader instantly resumes to the correct batch. Training continues deterministically. Finally, we move again to Google Cloud to finish the run.
As we train our LLM across three cloud providers, the only costs we pay are for GPU compute and data storage. No egress fees or lock in thanks to Cloudflare R2!
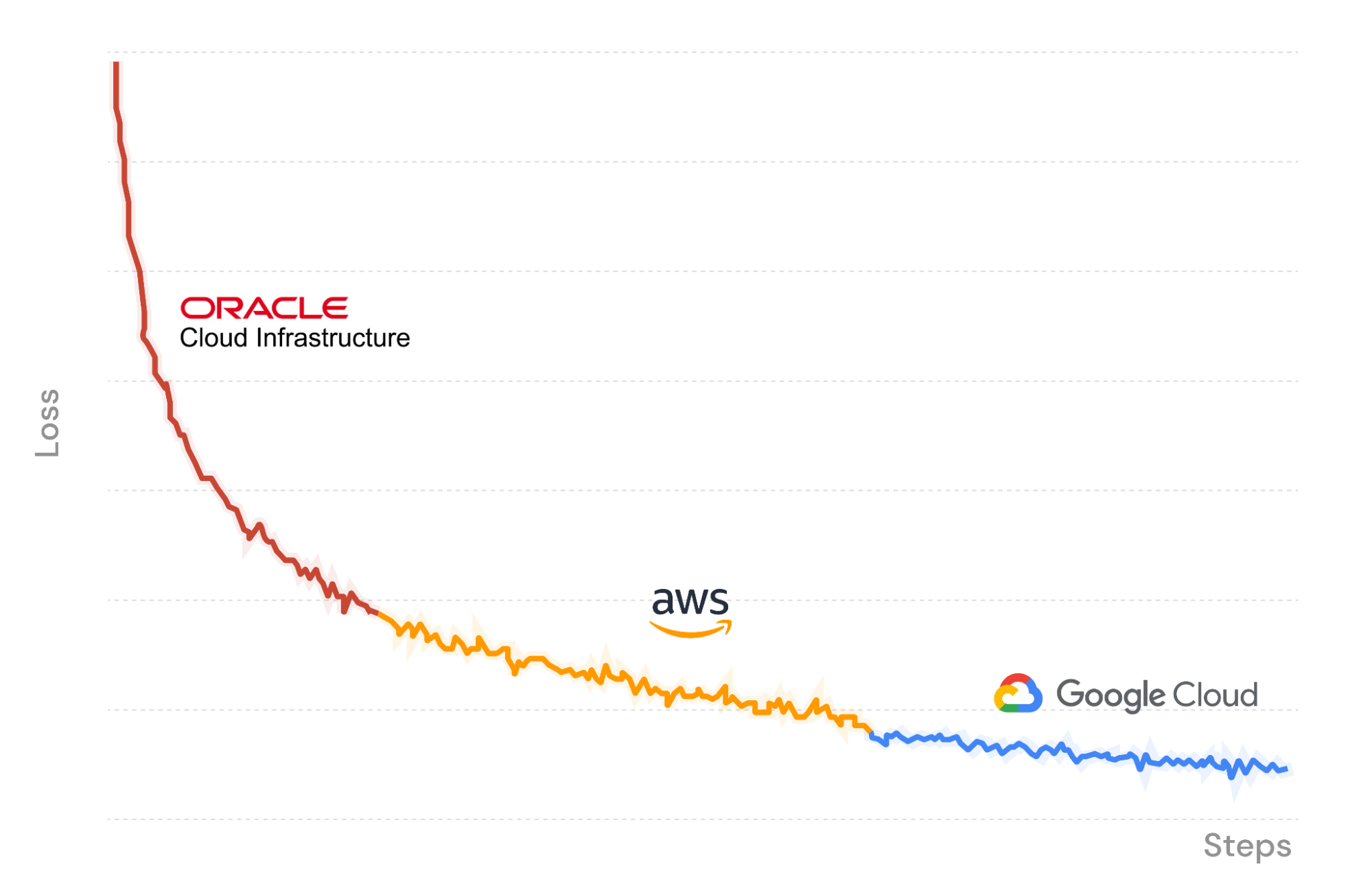 Using the MosaicML training platform with Cloudflare R2 to run an LLM training job across three different cloud providers, with zero egress fees.
Using the MosaicML training platform with Cloudflare R2 to run an LLM training job across three different cloud providers, with zero egress fees.
$ mcli get clusters
NAME PROVIDER GPU_TYPE GPUS INSTANCE NODES
r1z1 MosaicML │ a100_80gb 8 │ mosaic.a100-80sxm.1 1
│ none 0 │ cpu 1
r3z1 GCP │ t4 - │ n1-standard-48-t4-4 -
│ a100_40gb - │ a2-highgpu-8g -
│ none 0 │ cpu 1
r4z4 AWS │ a100_40gb ≤8,16,...,32 │ p4d.24xlarge ≤4
│ none 0 │ cpu 1
r7z2 OCI │ a100_40gb 8,16,...,216 │ oci.bm.gpu.b4.8 ≤27
│ none 0 │ cpu 1
$ mcli create secret s3 --name r2-creds --config-file path/to/config --credentials-file path/to/credentials
✔ Created s3 secret: r2-creds
$ mcli create secret env S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
✔ Created environment secret: s3-endpoint-url
$ mcli run -f mpt-125m-r2.yaml --follow
✔ Run mpt-125m-r2-X2k3Uq started
i Following run logs. Press Ctrl+C to quit.
Cloning into 'llm-foundry'...
Using the MCLI command line tool to manage compute clusters, secrets, and submit runs.
### mpt-125m-r2.yaml ###
# set up secrets once with `mcli create secret ...`
# and they will be present in the environment in any subsequent run
integrations:
- integration_type: git_repo
git_repo: mosaicml/llm-foundry
git_branch: main
pip_install: -e .[gpu]
image: mosaicml/pytorch:1.13.1_cu117-python3.10-ubuntu20.04
command: |
cd llm-foundry/scripts
composer train/train.py train/yamls/mpt/125m.yaml
data_remote=s3://mosaicml-datasets/c4-gptneox20b-2k
max_duration=100ba
save_folder=s3://checkpoints/mpt-125m
save_interval=20ba
run_name: mpt-125m-r2
gpu_num: 8
gpu_type: a100_40gb
cluster: r7z2 # can be any compute cluster!
An MCLI job template. Specify a run name, a Docker image, a set of commands, and a compute cluster to run on.
Get started today!
The MosaicML platform is an invaluable tool to take your training to the next level, and in this post, we explored how Cloudflare R2 empowers you to train models on your own data, with any compute provider – or all of them. By eliminating egress fees, R2’s storage is an exceptionally cost-effective complement to MosaicML training, providing maximum autonomy and control. With this combination, you can switch between cloud service providers to fit your organization’s needs over time.
To learn more about using MosaicML to train custom state-of-the-art AI on your own data visit here or get in touch.
Source:: CloudFlare