
This post is the fifth in a series about optimizing end-to-end AI. NVIDIA TensorRT is a solution for speed-of-light inference deployment on NVIDIA hardware….
This post is the fifth in a series about optimizing end-to-end AI.
NVIDIA TensorRT is a solution for speed-of-light inference deployment on NVIDIA hardware. Provided with an AI model architecture, TensorRT can be used pre-deployment to run an excessive search for the most efficient execution strategy.
TensorRT optimizations include reordering operations in a graph, optimizing the memory layout of weights, and fusing ops to a single kernel to reduce memory traffic to VRAM. To apply these optimizations, TensorRT must have the full network definition and its weights.
The evaluated strategy is serialized within a TensorRT engine, which is shipped with the application to achieve the best inference performance in production. Nothing else apart from this engine is needed during deployment to execute the network.
The inclusion of compiled kernels and the serialization to a file make this engine compatible only with a GPU of the same compute capability. The file is also specific to a TensorRT version but will be compatible with future versions after 8.6.
Generating a performant and correct engine
A network graph definition and its weights can be either parsed from an ONNX file or by building a network manually using the NetworkDefinition API. Building the graph manually provides the most granular access to TensorRT but also requires the most effort.
A quick way to evaluate TensorRT on a given ONNX file is to use trtexec. This tool can also be used to generate an engine file that can be deployed with the Python or C++ API later through the --saveEngine option. Run the following command to create an engine:
trtexec –onnx="model.onnx" –saveEngine="engine.trt"
When you are using TensorRT through ONNX Runtime, only some of the TensorRT native build features provided by trtexec or the TensorRT API are exposed. For more information about TensorRT through ONNX Runtime, see TensorRT Execution Provider.
In this post, I briefly discuss what is needed for acquiring a performant engine from an ONNX file using trtexec. Most of the command-line options can be easily translated to TensorRT C++/Python API functions.
For investigating TensorRT performance, precision, or compatibility, useful tools include polygraph or trex. In case the operations in the graph are not supported by TensorRT, you can write plugins to support custom operations in an engine.
Before going through the effort of implementing a custom operator, evaluate whether the operation can be realized through a combination of other ONNX operators.
Precision
TensorRT performance is heavily correlated to the respective operation precision INT8 or FP16 and FP32.
When using trtexec with an ONNX file, there is currently no option to use the precision specified inside the ONNX file. However, you can enable TensorRT to cast weights to the respective precision and evaluate the inference cost. Use --fp16 or --int8. Lower precision usually results in faster execution, so those weights are more likely to be selected in the resulting engine.
Model quality can be affected by reducing the numeric precision, so you can manually label specific layers to be executed at higher precision using the --layerPrecisions option. To get the most performance by using Tensor Cores it is important to have tensor alignment of, for example, eight elements for FP16. This is not only true for TensorRT but also for ONNX optimization in general.
When the model requires FP32 precision, TensorRT still enables TF32 on NVIDIA Ampere architecture and later by default, but it can be disabled using --noTF32. When TF32 is used, the multiplicands of a convolution are rounded to their nearest FP16 equivalent. The exponent and therefore the dynamic range of FP32 are preserved. After these multiplications, the result of the convolution multiplications is summed using FP32. For more information, see TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x.
Input format
In combination with the used precision, it can also be useful to change the I/O buffer type using --inputIOFormats and --outputIOFormats.
As Tensor Cores require an HWC layout, it can be beneficial to ingest data in that layout if possible. That way, TensorRT does not have to do an internal conversion, especially if the data is already present in FP16. If you have data in HWC and FP16, run the following command for compilation:
--inputIOFormats=fp16:hwc --outputIOFormats=fp16:hwc
All other precisions are also supported in CHW and HWC.
Workspace size
As I mentioned earlier, TensorRT has different tactics for executing operations in the graph. A 2D convolution, for example, can be executed without an intermediate buffer by loading the full kernel.
For large kernels, it can make sense to execute the convolution in two 1D convolution passes, requiring intermediate buffers. Use the –memPoolSize argument in trtexec to specify the maximum amount of VRAM that TensorRT can allocate in excess. For example, –-memPoolSize=workspace:100 limits the size of intermediate buffers to 100 MB. Experimenting with this value can help you find a balance between inference latency and VRAM usage.
For more information about optimizing TensorRT inference costs, see Optimizing TensorRT Performance.
Deployment target
After finding the ideal way of serving a network using TensorRT, it comes down to how this model can be deployed.
For this, it is important to pinpoint the requirements that must be fulfilled and compare the strategies. Those change heavily with the deployment target: server, embedded, or workstation.
For the server and embedded deployment scenarios, the hardware variety is usually limited, which makes shipping a dedicated engine together with the binary an attractive solution.
This post series focuses on workstation deployment for which a wide variety of systems must be considered. During development, end-user workstations are completely unknown, making it the most difficult deployment scenario.
The challenges that TensorRT has on workstations are two-fold.
First, depending on the AI model complexity, compiling engines on the user’s device can be a lengthy process (from seconds but also up to multiple minutes), which could be hidden in an installer for example. The GPU should ideally be idle during engine generation as inferences are timed on the GPU and the best performing is selected. Running any other tasks on the GPU simultaneously distorts timings and results in suboptimal execution strategies.
Second, a TensorRT engine is specific to a certain compute capability (for example, for the NVIDIA Ampere and NVIDIA Ada Lovelace architectures). For a single model, you’d ship multiple precompiled engines to support multiple GPUs. When you’re trying to squeeze the best inference performance out of the GPU, you’d have to ship an engine for each GPU SKU (for example, 4080, 4070, and 4060) instead of one for the whole compute capability. Shipping many engines of the same model is counterintuitive. It’s often not feasible as each engine holds all the needed weights already and it just bloats the binary shipment size.
Based on those challenges, two solutions are best suited for workstations:
- Shipping prebuilt engines
- Shipping a prepopulated timing cache
For both approaches, you must compile engines on all supported GPU architectures before deploying.
Be aware that these solutions are not just a consideration for the first deployment, as workstation hardware is subject to change. If you decide to upgrade your GPU to the latest generation, you must generate a new engine.
Shipping prebuilt engines
Shipping prebuilt engines is especially useful for server or embedded appliances and is usually the best solution. In those scenarios, the hardware is already known and an engine fitting for this hardware can be included into the deployment binaries.
For workstations, it is not usually feasible to ship all required engines. A download must be executed during installation or upon requesting a specific feature.
For this download, you must query the GPU’s compute capability and download the respective engine. In that case, TensorRT AI deployment does not impact an application’s shipping size at all, apart from the shared library. The original weights and network definition in the form of an ONNX file, for example, do not have to be shipped.
Usually, a TensorRT engine is much smaller than its corresponding ONNX file. The obvious downside of this is that an offline installer is not possible. This is not necessarily a big problem nowadays.
NameEngine size (MB)RoBERTa475Fast Neural Style Transfer3sub-pixel CNN0YoloV4125EfficientNet-Lite425Table 1. Engine sizes for different models
Shipping a prepopulated timing cache
First, I want to explain what a timing cache is and how you can acquire one.
While building an engine, you can evaluate the inference time of the evaluated execution plans. The results of this timing can be saved to a timing cache for later reuse through the --timingCacheFile option of trtexec.
A timing cache does not have to be model-specific. In fact, I recommend using a system-wide timing cache for all TensorRT build processes. Whenever a kernel timing is needed, the process checks the timing cache and either skips timing or extends the timing cache. This drastically reduces the engine build time!
The timing cache is usually only a few MB big or even under 1 MB. This makes it possible to include multiple caches in the initially shipped binaries of an application and drastically reduce build times.
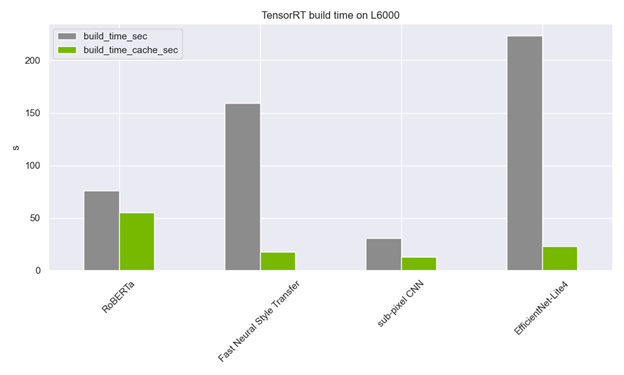 Figure 1. Engine build time with and without a timing cache for some models taken from the ONNX model zoo. During the build, FP16 execution was enabled.
Figure 1. Engine build time with and without a timing cache for some models taken from the ONNX model zoo. During the build, FP16 execution was enabled.
You are still required to precompile all engines on multiple compute capabilities to populate the cache. However, for shipment, only a small additional file is needed.
As with the engines, it would be ideal to have one cache for every single GPU, but it is possible to ignore those mismatches in deployment across a compute capability. With this file present, building an engine on the user side is a CPU-only operation that can be done during installation without worrying about a busy GPU during timing. Using this approach of shipping a timing cache and the ONNX model enables a controllable engine-building process on the user device without downloading files on demand.
Further acceleration is possible using a new heuristic algorithm selection (--heuristic flag). It currently only prunes convolution tactics that are unlikely to be the fastest but it will be extended to other operations in future releases.
Conclusion
This post shows the options for TensorRT engine deployment to workstations without shipping vast amounts of binaries. The options also avoid putting you through a time-consuming and possibly incorrect building process in case of a busy GPU.
All the trtexec options mentioned in this post can be found in the open-source code of trtexec or by searching the C++ or Python API documentation for the respective features.
After reading, you should be able to decide which method is the optimal deployment choice for your application and find a balance between binary size and compute time on a user device. Be aware that mixing the strategy on multiple models is also an option.
For commonly used models, you might want to compile them in the installer with a timing cache. For other models that not all users need, download the respective ONNX or TensorRT engine on demand.
Learn more about TensorRT deployment in our forum, AI & Data Science.
Attend GTC 2023 for free from March 21-23 and see our AI for Creative Applications sessions.
Source:: NVIDIA