
NVIDIA Base Command Platform provides the capabilities to confidently develop complex software that meets the performance standards required by scientific…
NVIDIA Base Command Platform provides the capabilities to confidently develop complex software that meets the performance standards required by scientific computing workflows. The platform enables both cloud-hosted and on-premises solutions for AI development by providing developers with the tools needed to efficiently configure and manage AI workflows. Integrated data and user management simplify both the user and administrator experience.
Now, creating high-fidelity digital twins across teams and locations using NVIDIA Modulus with Base Command Platform is the newest tool available for high-performance computing (HPC) workflows. Creating and using digital twins is crucial to saving time and money for many use cases—from predicting optimal airplane maintenance schedules to simulating wind farms.
Getting started on these use cases can be daunting. However, a well-integrated solution makes all the difference and enables developers to focus on solving problems. Base Command Platform puts the full breadth of NGC catalog software a few clicks away and empowers the creation of powerful physics-informed machine learning (physics-ML) neural networks and climate models.
Climate modeling with FourCastNet
FourCastNet, part of the open-source Modulus platform, is focused on the creation of global weather forecasting at speeds that were previously impossible. It relies on Fourier neural operators and transformers to achieve this incredible leap in performance and resolution. FourCastNet is now compatible with Base Command Platform.
Video 1. Accelerating extreme weather prediction with FourCastNet
The ERA5 dataset, a complex weather dataset for the entire Earth across several decades, is used to train and validate such a complex model. FourCastNet is a key technology enabling the creation of the NVIDIA Earth-2 digital twin. For more information, see NVIDIA to Build Earth-2 Supercomputer to See Our Future.
The Modulus team is constantly looking to improve the performance of FourCastNet and recently updated it to use NVIDIA Data Loading Library (DALI) to ingest data to GPUs, further accelerating time to insight.
Boost scalability with Modulus on Base Command Platform
The full power of Modulus is unleashed when run in an environment that can scale across several GPU-based systems. There is no better way to run a highly scalable platform like Modulus to train large models like FourCastNet than Base Command Platform.
To run these examples, we uploaded a slightly modified version of the Modulus NGC container to a Base Command Platform organization that has access to an accelerated computing environment composed of NVIDIA DGX A100 systems. We uploaded one terabyte of the ERA5 dataset to a workspace in that same environment.
To support coordinated multi-instance workloads, Base Command Platform integrates a tool called bcprun. bcprun simplifies multi-instance workload deployment by abstracting away complexity for machine learning (ML) practitioners and removing the need for additional software within workload containers (such as mpirun). It also provides an easier onboarding path for applications originally written for use with HPC schedulers, like Slurm.
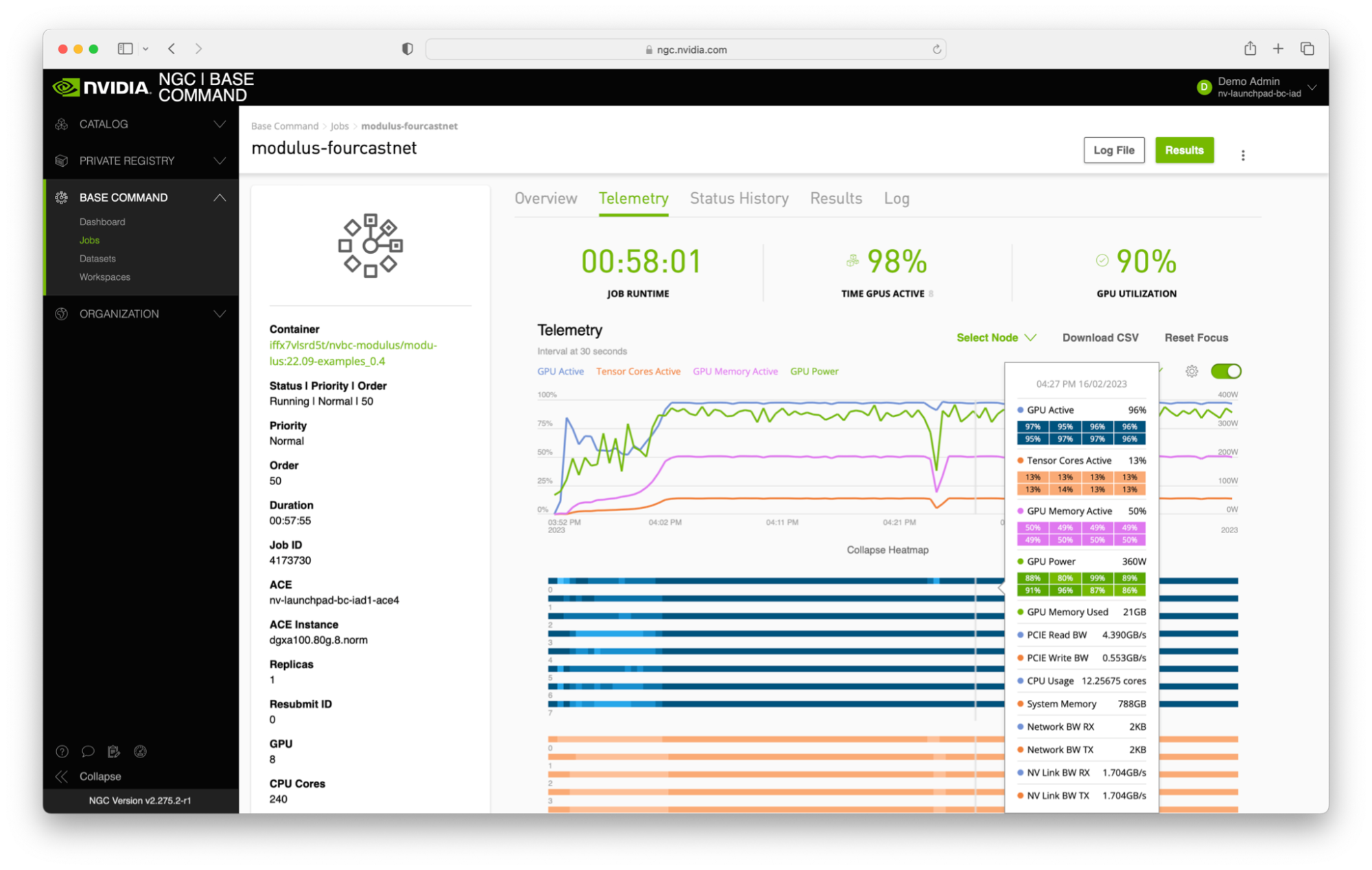 Figure 1. Telemetry output from Base Command Platform showing FourCastNet maximizing resource utilization
Figure 1. Telemetry output from Base Command Platform showing FourCastNet maximizing resource utilization
The following code example shows a single-instance job launch of FourCastNet on Base Command Platform:
ngc batch run
--name "bcp-dali.fcn.training.ml-model.modulus"
--total-runtime 12H
--org org-name
--ace ace-name
--instance dgxa100.80g.8.norm
--workspace ERA5_test_21Vars:/era5/ngc_era5_data/:RO
--result /results
--image "nvcr.io/org-name/team-name/modulus:22.09-examples_0.4"
--commandline "
set -x &&
cd /examples/fourcastnet/ &&
ln -s /era5/stats . &&
python fcn_era5.py
custom.train_dataset.kind=dali
custom.num_workers.grid=1
training.max_steps=50000
training.print_stats_freq=500
network_dir=/results/network_checkpoint
"To scale to two NVIDIA DGX A100 eight GPU instances (16 total), use the following command (with changes highlighted in bold):
ngc batch run
--name "bcp-dali.fcn.training.ml-model.modulus"
--total-runtime 12H
--org org-name
--ace ace-name
--replicas "2"
--array-type "PYTORCH"
--instance dgxa100.80g.8.norm
--workspace ERA5_test_21Vars:/era5/ngc_era5_data/:RO
--result /results
--image "nvcr.io/org-name/team-name/modulus:22.09-examples_0.4"
--commandline "
set -x &&
cd /examples/fourcastnet/ &&
mkdir -p /results/network_checkpoint &&
ln -s /era5/stats . &&
bcprun --nnodes $NGC_ARRAY_SIZE
--npernode $NGC_GPUS_PER_NODE
--cmd '
python fcn_era5.py
custom.train_dataset.kind=dali
custom.num_workers.grid=1
training.max_steps=50000
training.print_stats_freq=500
network_dir=/results/network_checkpoint
'
"The bcprun addition, along with the arguments added, ensures that the specified command (from the --cmd argument) runs on each replica created for the job (as specified by the --replicas and --nnodes arguments). The --npernode argument ensures that there is a process running on each instance for each GPU in that instance. This results in 16 total process launches for this job (eight in each replica, two total replicas). To scale to using four instances, set the --replicas argument to four instead of two.
Base Command Platform not only provides ease of use for ML practitioners and administrators but proves that peak performance has been achieved. The NVIDIA Selene supercomputer runs FourCastNet training with Modulus for comparison.
After testing the workload on Selene, we seamlessly reproduced the workload on a Base Command Platform deployment and achieved nearly identical results between the two environments. This outcome provides strong evidence that Base Command Platform can support the most demanding performance requirements for customers across both enterprise and scientific computing use cases.
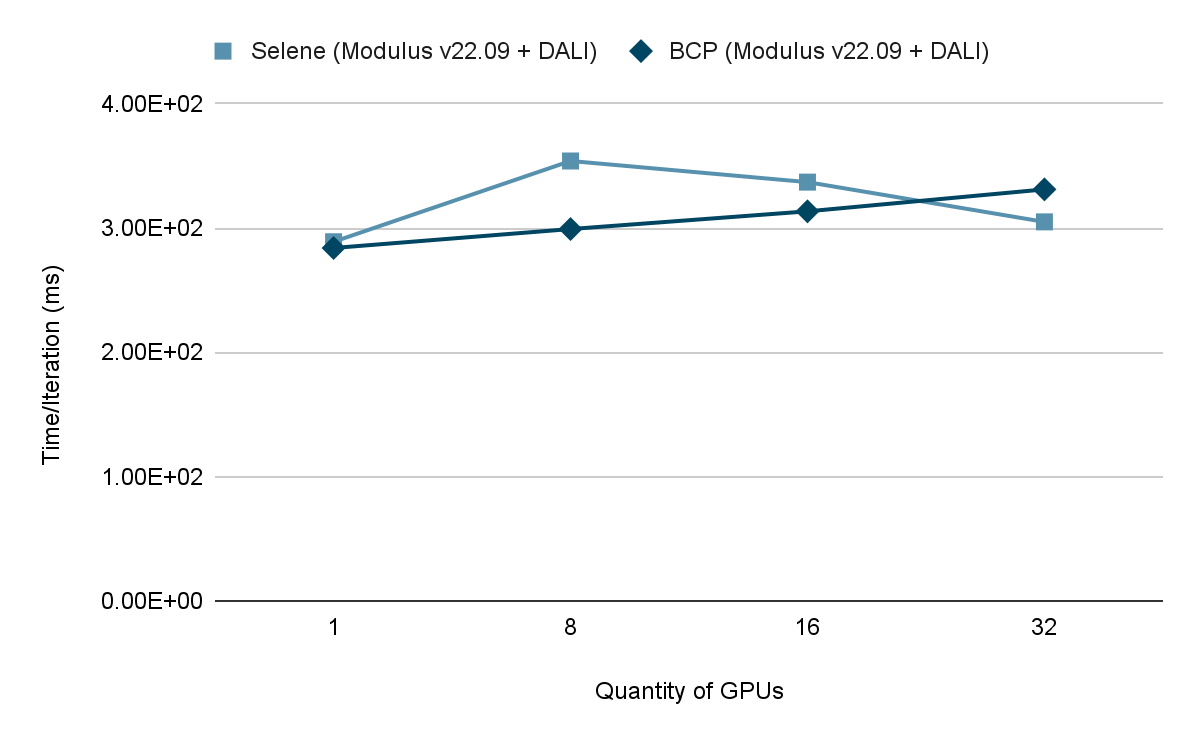 Figure 2. Modulus FourCastNet performance comparison between the NVIDIA Selene supercomputer and a Base Command Platform deployment at various GPU quantities (same time across GPU quantities is better)
Figure 2. Modulus FourCastNet performance comparison between the NVIDIA Selene supercomputer and a Base Command Platform deployment at various GPU quantities (same time across GPU quantities is better)
An interview with developer Kaustubh Tangsali
To learn more about the experience of using NVIDIA Modulus on Base Command Platform, we spoke with Kaustubh Tangsali, a developer on the Modulus team. Kaustubh led the investigation of running FourCastNet and several other software examples on Base Command Platform.
Briefly describe your industry background and experience.
I have primarily worked in the software industry with applications in simulation and computational fluid dynamics. I work on the development of the Modulus platform, which is a framework for domain experts and AI practitioners to develop physics-ML models. I have worked closely with internal partners like the NVIDIA Thermal team for using Modulus to design heat sinks and also several external partners to accelerate their workflows using Modulus.
How long have you been working with Modulus on Base Command Platform?
I have been using Modulus on Base Command Platform since mid-2020.
What does a routine day of use look like for you on Base Command Platform? What does your development cycle look like?
After I’ve done some local testing of my code or model, I typically mount my code in a Base Command Platform workspace and then launch jobs using either the NGC web interface or just using the command-line interface (CLI). The Jupyter interface is great for early debugging. When the model has run to completion, I download the checkpoints and results for further analysis. During the runtime, I also use the log feature and telemetry to monitor the job’s status.
How does a Base Command Platform environment compare to other environments you have used?
The web interface of Base Command Platform is something that I find useful. It is easy to monitor jobs, see the commands used to launch them, clone the jobs, and use different instance types, to name a few features. I think getting access to the latest and the best NVIDIA hardware is a big plus.
Do you have any advice for someone who is just getting started with Base Command Platform?
The NVIDIA Base Command Platform User Guide is well-documented and covers many common use cases that a data scientist might encounter, with command samples for single GPU, multi-GPU, and multi-instance jobs. As I mentioned earlier, I like to leverage the interactive nature of running jobs during the early stages of development before scaling the jobs, which the CLI streamlines.
Summary
Cutting-edge digital twin technology such as NVIDIA Modulus relies on powerful computing environments to make continued advancements. Base Command Platform harnesses the power of NVIDIA GPUs in an easy-to-use set of interfaces, continuing the NVIDIA mission of making advanced software capabilities broadly accessible to solve important problems. For more information, see Simplifying AI Development with NVIDIA Base Command Platform.
Kick-start your inference journey with short-term access in NVIDIA LaunchPad for Modulus. There’s no need for setting up your own environment.
For more information about NVIDIA Modulus, see the NVIDIA Deep Learning Institute course, Introduction to Physics-Informed Machine Learning with Modulus.
To get the latest release details, download and try NVIDIA Modulus.
Register for NVIDIA GTC 2023 for free and attend the Enterprises Share Their Experience with DGX Cloud session to learn about the wide array of use cases that are powered by Base Command Platform.
Source:: NVIDIA